(点击
上方公众号
,可快速关注)
来源:朱小厮
链接:blog.csdn.net/u013256816/article/details/52769297
数据增量订阅与消费
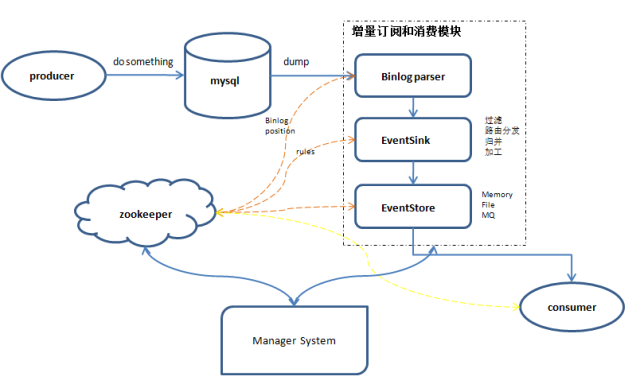
基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql.
有关数据增量订阅与消费的中间件回顾一下:
-
增量订阅和消费模块应当包括binlog日志抓取,binlog日志解析,事件分发过滤(EventSink),存储(EventStore)等主要模块。
-
如果需要确保HA可以采用Zookeeper保存各个子模块的状态,让整个增量订阅和消费模块实现无状态化,当然作为consumer(客户端)的状态也可以保存在zk之中。
-
整体上通过一个Manager System进行集中管理,分配资源。
Canal
Canal架构图:
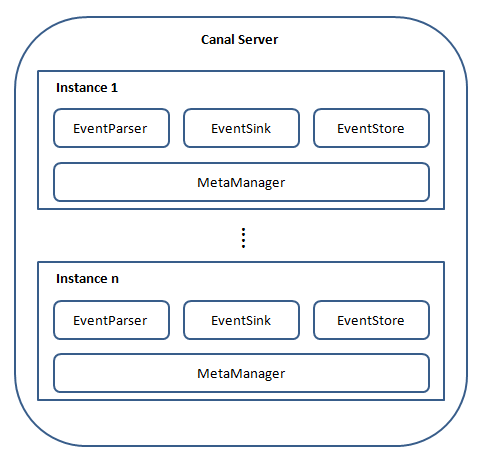
说明:
instance模块:
-
eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
-
eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
-
eventStore (数据存储)
-
metaManager (增量订阅&消费信息管理器)
说明:一台机器下部署一个canal,一个canal可以运行多个instance(通过配置destinations等), 一般情况下一个client连接一个instance(每个instance可以配置standby功能), 可以多个client连接同一个instance,但是同一时刻只能有一个client消费instance的数据,这个通过zookeeper控制。
数据库同步
Otter
背景:alibaba B2B因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otter4。
基于数据库增量日志解析,准实时同步到本地机房或异地机房的mysql/oracle数据库,一个分布式数据库同步系统。
工作原理
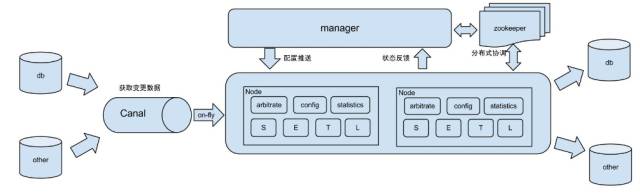
原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。
2. 典型管理系统架构,manager(Web管理)+node(工作节点)
-
manager运行时推送同步配置到node节点
-
node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作。
Otter的作用
1. 异构库
2. 单机房同步(数据库之间RTT(Round-Trip Time)
3. 跨机房同步(比如阿里巴巴国际站就是杭州和美国机房的数据库同步,RTT>200ms)
4. 双向同步
5. 文件同步
单机房复制示意图
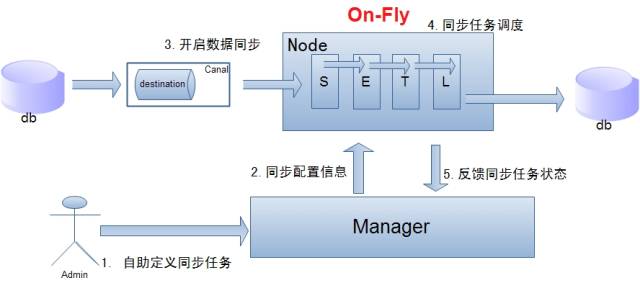
说明:
- 数据On-Fly, 尽可能不落地,更快的进行数据同步。(开启node load balance算法, 如果Node节点S+ETL落在不同的Node上,数据会有个网络传输过程)
- node节点可以有failover/loadBalancer.
SETL
S: Select
为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
E: Extract
T: Transform
L: Load
类似于数据仓库的ETL模型,具体可为数据join,数据转化,数据加载。
跨机房复制示意图
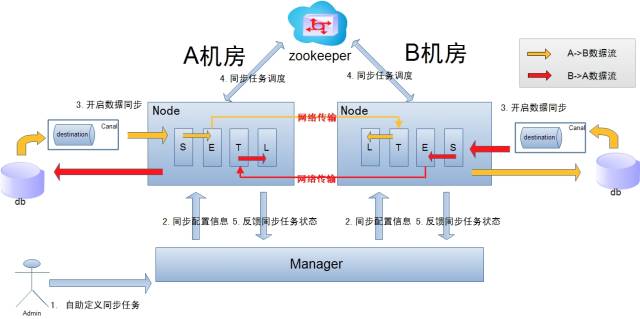
数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作(一般是Select和Extract在一个机房的Node, Transform/Load落在另一个机房的Node)
node节点可以有failover/loadBalancer。(每个机房的Node节点,都可以是集群,一台或者多台机器)
More:
-
Otter调度模型:batch处理+双节点部署。
-
Otter数据入库算法
-
Otter双向回环控制
-
Otter数据一致性
-
Otter高可用性
-
Otter扩展性
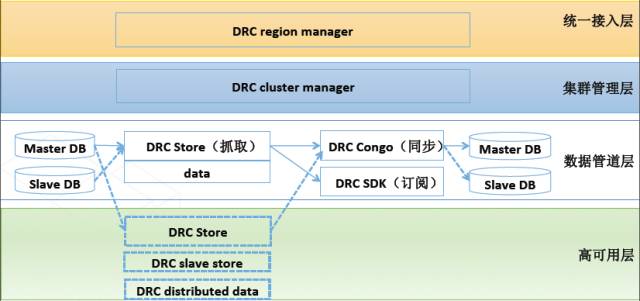
异地双活数据架构基础设施DRC
所谓DRC,就是Data Replication Center的缩写,数据复制中心。这种复制是同步的,支持异构的,高可用的(有严格容灾系统,实时性好),支持订阅分发的。项目期初是为了淘宝异地容灾而成立的,用于数据库之间主备同步,后来采用这套技术方案衍生出了DRC-TAIR, DRC-DUMP等项目。
所谓异地双活主要关注两件事,一个数据同步,一个数据分发。
到底怎样的应用会需要异地的双活?比较常见的场景有三个:
-
两个地域或多个地域都有大量用户的场景,比如在中国的用户希望他们用杭州的RDS服务,在美国的用户用美国的RDS服务,这就需要数据在异地同步。很多游戏,金融,传媒,电商业务都有这种需求。满足这个需求的难点在于跨地域的网络,比如网络延时长,丢包多,而且数据在公网传输会有数据泄露风险。
-
数据来源较多,需要介入各种异构数据的场景。比如一个应用需要从ODPS, RDS, OTS, OceanBase, PostgreSQL这几个服务介入数据,他们的数据结构和接口都不同,这种接入的成本会比较高。因此另一个可用的方法是数据写入的时候就一份多谢为不同数据结构
-
下游订阅很多的情况,比如一份数据,备份系统、通知系统、大数据分析系统、索引系统等等都要来取,如果用上面一份数据多写的方案是可以应对的,但这里还有其他难点,就是数据一致性、可扩展性、跨网同步稳定性、以及同步的实时性。
DRC支持读取集团MySQL, RDS, OceanBase, HBase, Oracle等多种不同的数据源的实时增量数据,支持写入数据库、MetaQ, ODPS等多种存储媒介.
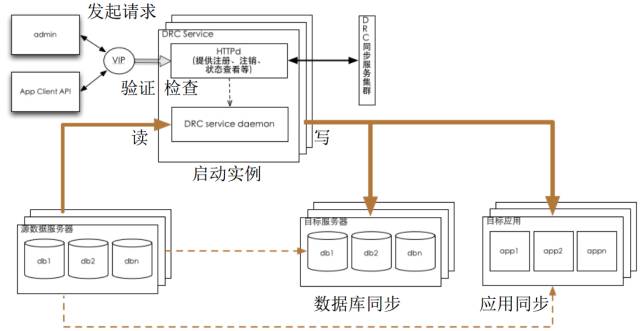
以前在一个城市做双机房主备,两个机房是数据对等的,写入是随机分布,然后通过主备HA进行数据同步。这样机房对等的思路会导致业务增长、数据增长只能通过两个机房不停堆机器来解决。另一方面,如果整个城市断电,那么双活就成了双死。下一个思路是做跨城市,早期常用的做法是一个城市写,另一个城市冷备,就是晚上做同步,但这就意味着白天如果发生了什么事儿,这一天的数据就比较危险。另一个思路是两个城市多写,数据落两边,这样的问题是应用调用次数频繁的话,如果调用异地数据多来那么一两次,整个应用的延时就很长。这个思路再进一步发展,就是做单元内封闭以减少异地调用,这就涉及到业务上的改造。
顺着这个思路,阿里的异地双活重点做了几件事。一个是热插拔,可以做到在业务高峰时增加节点,高峰过了把增加的节点关闭。做到这个的一个关键是流量实时切换 ,DRC可以在20秒以内把一个单元(region)的流量迁移到另一个单元。另一个是数据实时恢复,就是通过一定的冗余设计,一旦一个单元挂掉了,可以在另一个单元做全量恢复。
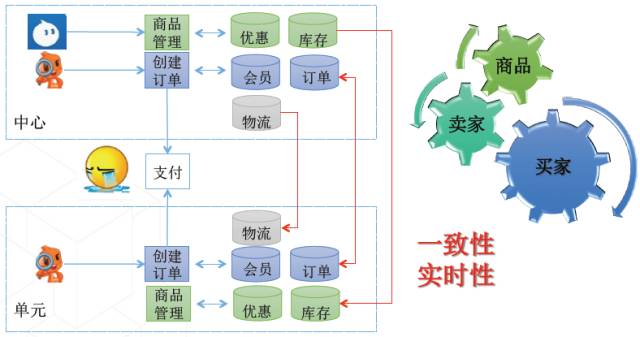
异地多活在数据方面的挑战是非常大的。双十一期间,交易会激增,所以交易链路做了单元化。交易链路的数据分为三个维度:买家、卖家、商品。买家之间通常没有太多交叉,天然的适应这种隔离,而且卖家对延迟的敏感度非常高,所以按照卖家维度切分,在单元内封闭,而卖家和商品都是在中心写入。
数据方面的两个核心要求:
-
一致性,要求卖家和商品一致,单元和中心一致,也就是数据同步不能丢数据,不能错数据,还要保证事务。
-
实时性,需要做到秒级别的延迟。
双单元的同步架构有两种:
一种是读写分离的方式,中心写,单元读。单元需要的数据如果没有从中心及时同步过来,或者同步错了,那有问题这段时间的交易会全部收到影响。这里的核心是,保证秒级延迟,同时保证一致性。(JD的多中心交易系统就采用了这种方式)
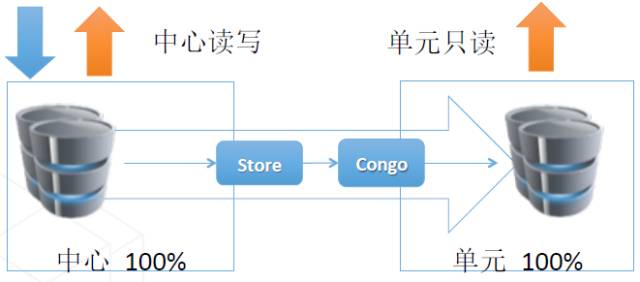
第二种同步架构是单元封闭的方式。中心和单元各有写入,我们通过冗余是的中心和单元随时可以各自接管。(类似Otter)
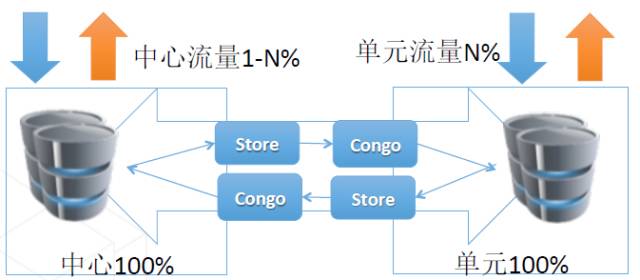
这里的关键是:
Otter与DRC的区别:
- Otter是阿里B2B的产品,DRC是阿里技术保障团队的产品
- Otter是针对MySQL的,DRC可以支持多种类型的数据源
- DRC从业务上进行了划分,可以实现单元内封闭,Otter的实现不涉及业务,而是在纯数据库层打通的技术
- Otter是双写,DRC是中心写、分中心读,或者都部分写,相互同步。
- Otter所处的网络环境较DRC差,解决一致性问题也较复杂(基于trusted source的单向环回的补救,基于时间交集的补救),DRC有两种实现方式,具体参考上面。
异地多活中DRC的核心能力就是在低延迟,一致性和高可用。
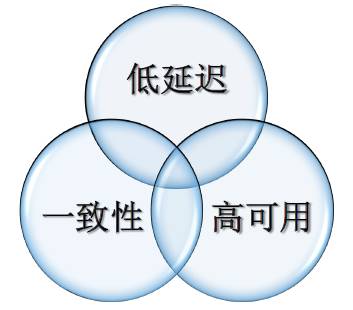
-
一致性:基于日志流式抓取、回放库表结构变更、基于事务的冲突检测。
-
低延迟:最大延迟不超过1s, 消息协议优化,三级数据存储,预读优化IO, 多连接复用和传输压缩,高效的并发复制算法。
-
高可用:主备切换,拓扑变化,心跳跟踪,多维度容灾。
JD多中心交易系统
JD数据复制中间件考察和借鉴了开源社区的实现,例如Databus、Canal/Otter、OpenReplicator等,解析部分使用了Canal的DBSync。
多中心交易本质上是一个更大的分布式系统,交易流程中依赖和产生的数据和服务有不同的特点,必然涉及到数据分区、路由、复制、读写一致性、延迟等分布式领域的常见问题。
其中,数据一致性是电商网站需要面临的首要问题,越是流量增大的时候越要保证数据更新的即时性和准确性。在多中心之间需要同步卖家数据和商品数据,如果同步的延时太长,买家、卖家都不可接受。比如,卖家改了价格或库存,用户不能过很久才看到。同样,数据正确性也是很大的挑战,卖掉的商品能够及时减少,退货的商品能够及时增加。这都时刻考验着后端系统和数据库平台的健壮性。
除了数据一致性之外,如何保证路由规则的一致性也是关键性的问题。从技术角度来说,要保障单一用户从登录到访问服务、到访问数据库,全链路的路由规则都是完全一致的。如果路由错误,看到的数据不正确,也会影响到最终用户的体验。
架构
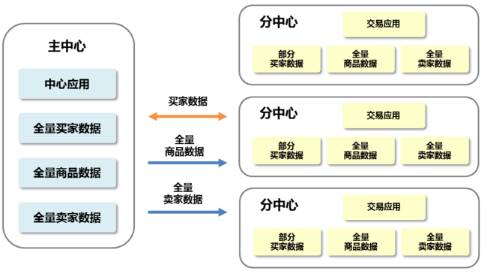
系统包括一个主中心和多个分中心,主中心与分中心之间通过数据总线交换数据。数据流向中,主数据(商品数据、商家数据、用户数据等)的流向从主中心通过数据总线实时同步到分中心,分中心只读;而交易数据(订单数据)的流向从分中心实时同步到主中心;在故障时,会从分中心转移到主中心。
在这个系统中,有多处体现分流的概念。首先,买家访问京东网站下单时,会被优先分流到附近的交易中心;其次,根据交易系统的特点,接单前(包括购物车、结算页等),多中心交易按用户维度分流,如下图所示。用户登录时,查询用户与区域的映射关系表(类似你是哪个片区的),标识此用户属于哪个分中心,并保存标识到cookie中,然后将用户路由到指定的分中心。用户访问其他系统,如购物车和结算页时,从cookie中读取标识,重定向到相应分中心页面。
通过分流,将用户分配到相应的分中心,一方面响应速度快,用户体验更好,不用跨地域访问数据中心了;另一方面,每个中心服务一定数量的用户,水平扩展性好,也能支撑更大的交易规模了。当然,多数据中心不能盲目干活,还考虑到容灾备份的问题。(支付宝光纤事件)
交易系统包括应用和数据部分,应用部分是无状态的,就是说,这些工作是无差别的,一台服务器出问题,我换一台服务器来处理就是了,较容易实现多机房多活。但是数据不一样,多中心交易本质上是一个更大的分布式系统,必然涉及到数据分区、路由、复制、读写一致性、延迟等分布式领域的常见问题。
另外,交易流程中依赖和产生的数据和服务有不同的特点。比如商品、促销和价格、库存的读服务,我们可以将之称为基础主数据,它们在用户下单流程中是无法分区的,否则无法实现单机房内流量闭环,也就是说,不能因为分区数据的不一致,导致同一用户在单一流程中看到不同的数据(假如你加入购物车时是促销20块,结账是25块,你会不会表情扭曲?)而商品、促销和价格的写服务,是给采销、第三方POP商家应用调用的,这种业务场景的可用性目标,主机房部署和冷备模式即可满足,而且业务人员的操作流程会抵消写复制延迟。
简单来说,数据的问题表现在以下几个方面:一、 如何保证数据的即时性和准确性,多中心之间需要同步卖家数据和商品数据,如果同步的延时太长,买家、卖家都不可接受,由于是异地部署,最好延时能控制在1秒内。比如,卖家改了价格或库存,用户不能过很久才看到。同样,数据正确性也是很大的挑战,因为数据故障跟应用层故障不一样,应用出故障了,可能只影响用户访问;数据写错了无法恢复。2、如何保证路由规则的一致性,要保障这个用户从进来到访问服务,到访问数据库,全链路的路由规则都是完全一致的;如果路由错误,看到的数据不正确。
从同城双机房的分布转变为异地多机房的分布,给数据同步带来了新的挑战,因此如何设计数据总线也是项目能否实现的关键因素。京东的多中心交易系统通过数据总线JingoBus进行快速数据交换,同步性能是mysql的3倍以上,而且可用性高,架构灵活。其中,全新的总线设计解决了多中心交易跨机房的数据库复制和多数据源间的数据异构同步等难题,实现了高性能、低延时、健壮的数据同步机制。

如图所示,数据总线主要分Relay、Snapshot和Replicator三部分构成,其中Relay从来源数据库抽取事务日志,并对Replicator提供日志订阅服务,角色上相当于Mysql Slave IO Thread。Snapshot从Relay订阅所有事务日志,写入持久存储作为快照,同时向Replicator提供批量日志订阅服务,角色上相当于Mysql Slave Relay Log。Replicator:事务日志的消费端,从Relay或Snapshot拉取事务日志将事务日志按配置的一致性应用到目标数据库,角色上相当于Mysql Slave SQL Thread。(参考下面MySQL主备复制原理图)
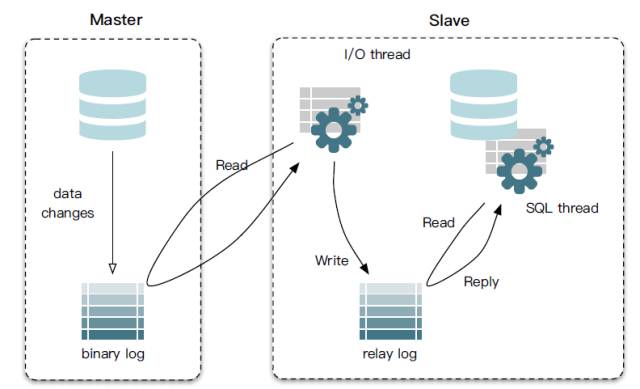
正常情况下,Replicator直接连接Relay,消费Relay内存队列中的事务日志。但有些情况下,因为网络抖动、目标库的负载过高等因素,可能导致Replicator相对Relay落后很多。另外,当新的消费端加入同一数据源的订阅者时,新消费端有冷启动的问题。为了避免重新从数据源做全量快照,Snapshot作为Relay的一个特殊消费端,通过一种高吞吐的消费方式,从Relay源源不断的消费在线事务日志,通过对事务日志的有效处理,最终保存了数据源的一份一致快照(Consistent Snapshot),即包括了数据源库表中每一行的最新状态的快照,同时保留了一段比Relay buffer更旧的事务日志(Log Store)。由此看来,数据总线作为一个数据层的通用CDC组件,对于多中心交易项目以及异步复制场景提供了整体解决方案,奠定了项目的核心内容。
跨数据库(数据源)迁移
yugong
去Oracle数据迁移同步工具。定位:数据库迁移(目前主要支持Oracle->mysql/DRDS)
08年左右,阿里巴巴开始尝试MySQL的相关研究,并开发了基于MySQL分库分表技术的相关产品,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机Oracle无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上,完成去IOE的第一步.
概述
整个数据迁移过程,分为两个部分:

过程描述:
-
增量数据收集(创建Oracle表的增量物化视图)
-
进行全量复制
-
进行增量复制(可并行进行数据校验)
-
原库停写,切换到新库
Oracle全量基于JDBC拉取数据,增量基于物化视图来实现。
架构
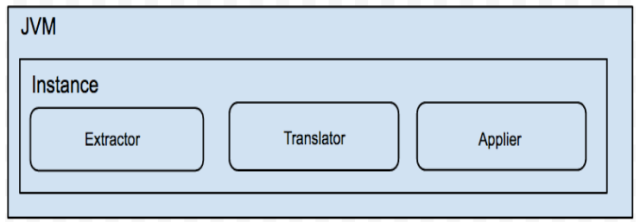
说明:
-
一个JVM Container 对应多个instance,每个instance对应于一张表的迁移任务
-
instance分为三部分
-
extractor (从数据源库上提取数据,可分为全量/增量实现)
-
translator (将源库上的数据按照目标库的需求进行自定义转化)
-
applier(将数据更新到目标库,可分为全量/增量/对比的实现)
自定义数据转换
如果要迁移的Oracle和mysql的表结构不同,比如表名,字段名有差异,字段类型不兼容,需要使用自定义数据转换。如果完全相同则可以跳过。
整个数据流为:DB->Extractor->DataTranslator->Applier->DB, 本程序预留DataTranslator接口(仅支持Java),允许外部用户自定义数据处理逻辑。比如:
-
表名不同
-
字段名不同
-
字段类型不同
-
字段个数不同
-
运行过程join其他表的数据做计算等
运行模式介绍
1.MARK模式(MARK)
开启增量日志模式,如果是Oracle就是创建物化视图(materialized view)。










