大数据与人地系统 ———————
数据应用
Data Applications
空气污染降低了中国城市居民在社交媒体上表达的幸福感
空气污染已成为城市生活质量恶化的主要原因。持续的研究表明,空气污染对健康(Ebenstein et al.2017)、认知表现(Chen et al.2017)、劳动生产率以及日后教育成果(Currie et al.2014)有不利影响。人们通过选择居住在污染较少的城市和绿色建筑,购买自我保护产品以及在高污染日减少户外活动时间来进行
规避行为
。中国空气污染可能导致城市居民的幸福感水平较低,为了验证这一说法,基于微博2.1亿条带有地理标签的推文中的情绪,构建了一个每日城市级别的表达幸福感指标,并研究了其与每日当地空气质量指数和PM2.5浓度的动态关系。利用2014年中国144个城市的每日数据,发现PM2.5浓度(或空气质量指数)每增加一个标准差,幸福感指数就会减少0.043(或0.046)个标准差。人们在周末、节假日和极端天气条件下会遭受更多的痛苦。女性以及最干净和最脏城市的居民对空气污染的表达幸福感更敏感。社交媒体数据为中国的政府提供了关于生活质量上升问题的实时反馈。本期数据应用专栏,给大家带来2019年发表在《Nature Human Behaviour》期刊上的《Air pollution lowers Chinese urbanites’ expressed happiness on social media》,让我们一起学习思考如何基于社交媒体数据,来量化城市空气污染对居民幸福感行为的影响。
本文核心方法为
基线回归模型、工具变量估计策略、机器训练的语义分析
,对每日空气质量指数 (AQI)和 PM 2.5 表达出的幸福感的影响进行分类估计。
提出三个研究假设。首先,空气污染是否会影响中国城市居民的实时幸福感?其次,污染对幸福感的影响在不同日子(如周末、节假日和非常炎热的日子)以及不同人口群体(男性与女性)中是否有所不同?最后,测试污染对幸福感的负面影响是否会因城市人均收入和典型污染水平的不同而有所差异。最后一个研究问题使得能够探究污染城市中污染的小幅增加对当地幸福感的影响,与清洁城市中相同污染增加的影响是否不同。
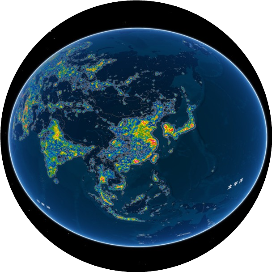
图1
微博帖子的地理分布以及PM2.5 浓度与幸福指数之间的关系
2.荐读文章
(1)
空气污染对幸福指数的影响
实证策略和变量定义在方法论的“基准回归模型”部分提供。表1报告的结果表明,污染(AQI和PM 2.5 ))与幸福指数之间存在负相关关系。在“所有城市”和“北京、上海和广州”下的四个列中,分别报告了“基准回归模型”(方法)中方程(1)的普通最小二乘(OLS)估计值。在这四个列中,包括了城市和日期固定效应,以及天气状况控制变量。第一列和第二列(“所有城市”)报告了基准回归结果。由于PM 2.5 是在研究期间,主要污染物在大约60%的污染日(AQI>100)中占主导地位,AQI和PM 2.5 的相关系数高达0.942(n=39529,P<0.001)。这些系数表明,AQI和PM 2.5 浓度的标准偏差减少一个单位,与幸福指数的标准偏差增加0.046和0.043个单位有关。这种幸福指数的增加量相当于五一劳动节期间的十分之一,因为五一劳动节期间人们有三天的假期。在第三和第四列中,将样本范围缩小到包括三个一线城市(北京、上海和广州),这些城市也有来自美国大使馆和领事馆的PM 2.5 数据。第三列使用来自中国环境保护部(MEP)的PM 2.5 数据,这种负面影响几乎增加了两倍(-0.142对比-0.043),表明大城市和富裕城市的人们可能对空气污染更加敏感。在第四列中,将来自MEP的PM 2.5 变量替换为来自美国大使馆和领事馆的变量,标准化系数(-0.147)与第三列使用MEP数据的系数(-0.142)非常相似。这两个指标具有高度的相关性,相关系数为 0.960(n = 812,P < 0.001)。
表1 污染对表达出的幸福感的影响
(2)
AQI 和 PM 2.5 对表达出的幸福感影响的分类估计
市级层面的污染对表达幸福感的影响可能反映了一种构成上的变化,即那些对污染最敏感的人在污染程度较高的日子里更多地参与社交媒体。为了解决这个问题,在用户日层面估计模型,并加入用户层面的固定效应。计算了一个相对频繁发帖的用户子样本中每个用户-城市-日的中位幸福感得分。这个子样本包含了约 5890 万用户的3300万条帖子。呈现出相同的模式,并且大小也与市级层面的回归结果相似。PM 2.5浓度与人们表达的幸福感之间的负相关关系可能是由于在个体城市层面上随时间变化的遗漏因素所产生的。例如,交通拥堵可能导致空气污染的变化以及人们表达的幸福感的变化。在这种情况下,估计会偏向于污染在导致幸福感低下的直接作用。采用两种策略来解决这种潜在的内生性问题。首先,纳入城市-月份固定效应。使用城市-月份单元格内的变化来识别污染对幸福感的影响。这组丰富的固定效应控制了当地的商业周期动态。其次,采用工具变量(IV)方法。由于风将空气污染物排放从邻近地区吹向目的地城市,这引入了目的地城市空气污染的外生变化。这种外生排放变量不太可能通过其他渠道影响目的地城市的本地社会和经济活动,因此是一个理想的工具变量。为了减少由于集聚效应导致相邻城市地方经济可能的相关性或共同运动,排除了距离目的地城市 120 公里范围内的所有相邻网格。这种工具变量(IV)方法还有助于解决PM2.5 中的测量误差问题。工具变量回归中估计的 PM 2.5 系数仍然为负,且具有统计学意义。这一发现支持了关于已确定空气污染对人们表达的幸福感具有因果影响的主张(表2)
(3)
污染对表达的幸福感产生的异质性影响
通过扩充方程(1)中报告的基准模型,并纳入几个关于PM 2.5 与工作日/周末/节假日指标之间的交互项,来检验污染对表达的幸福感产生的异质性影响。图2a中的每个柱状图表示如果特定类型的一天出现PM 2.5 ,幸福指数会受到的影响。人们在周末(分别周六和周日的-0.569和-0.537)和节假日(-0.860)中比在工作日(从周一到周五分别为-0.265、-0.201、-0.416、-0.483、-0.410)中更受空气污染的影响。空气污染和云量对人们表达的幸福感有协同作用。补充表11中第(i)至(iv)列的估计系数表明,在多云的日子里,当空气污染水平较高时,人们会感到更不舒服(图2b)。在补充表11的第(v)和(vi)列中,如果城市的温度落在城市25%至75%的分位数之间,则将其定义为“理想”温度。结果表明,在其他所有变量不变的情况下,当天气太热或太冷时,空气污染对幸福感的影响更大(图2b)。分别为每个城市的男性和女性构建了幸福感指标,并重新运行了公式(1)。这些结果表明,女性对空气污染的反应比男性更敏感(图2c)
图2 PM 2.5 对不同日子和天气状况以及性别群体中表达的幸福感的影响
(4)
空气污染对不同城市中表达的幸福感的影响
将整个样本分为144个城市子样本,并为每个城市估计方程(1)。这个过程产生了关于PM 2.5 的幸福感边际城市特定偏导数。将这个估计值定义为响应敏感度,RESPONSE(图3a)。ln(PM 2.5 ) 与 RESPONSE 之间的关系呈 U 形(图 3b),这意味着在最干净和最脏的城市中的人们对空气污染都更敏感。其潜在机制可能是,最不喜欢空气污染的人会搬到更清洁的城市并生活在那里,同时,在更脏的城市中的人们逐渐意识到长期暴露于污染所带来的健康风险。城市收入与特定城市的幸福函数斜率(RESPONSE)之间的关系单调递减(图 3b)。
图3 PM 2.5 对各城市所表达的幸福感的影响因城市而异
首先使用综合空气质量指标——中国环境保护部发布的每日空气质量指数(AQI)来研究这种关联,该指数是根据每个城市每日的主要污染物计算得出的。然后使用每日的实际浓度数据PM 2.5(空气动力学等效直径小于2.5微米的颗粒物)进行详细分析。通过应用机器训练的语义分析工具,对发布在中国最大的微博平台新浪微博(相当于推特)上的2.1亿条带有地理标签的微博帖子进行分析,来衡量每个城市的每日公众表达的幸福感。数据涵盖了2014年3月1日至2014年11月30日期间的144个中国城市(图1)。由于关于污染的讨论可能并不一定反映个人潜在情绪状态的变化,使用污染术语词典来过滤掉那些包含对空气质量合理参考的微博帖子,并使用不含污染相关术语的微博帖子来构建城市/日幸福感指数。大约0.047%的帖子包含一个或多个污染术语。对于每条微博帖子,使用“腾讯”自然语言处理(NLP)平台,这是一种来自计算语言学的机器训练的情感分析算法,来测量情感。一个城市在特定日期的总体幸福感指数是通过计算该城市/日的中位情感值来构建的。该指数的范围从0到100,0表示强烈负面情绪,100表示强烈积极情绪。使用另一个自然语言处理平台“Boson”构建了第二个版本的幸福指数,以进行稳健性检验,基于这个新指数的所有结果都呈现出相同的模式。将幸福数据集与城市级别的每日AQI、PM2.5浓度数据和天气数据合并。
(1)
基线回归模型。
为了研究空气污染对人们表达的幸福感的主要影响,使用固定效应面板回归方法来估计方程(1):
HAPPINESS it 和 POLLUTION it 分别表示第 t 天城市 i 的幸福度量和污染水平。在基准回归中(表 1),分别将 AQI 和 PM 2.5 浓度作为污染变量。X it 表示天气状况,T t 用于控制日期固定效应,其中 T 指一组日期指示变量。为了控制在不同城市中随时间不变但不可观测的变化因素,纳入了城市或地区固定效应 γ i。系数α 1 反映了人们对污染的反应,预期为负。
(2)工具变量估计策略
为了解决最小二乘法(OLS)对公式(1)的估计会得出有偏差的结论这一内生性问题,引入了一种工具变量策略。工具变量应该与城市的空气污染水平相关,但与公式(1)中的误差项不相关。跨境空气污染流动提供了一种构建此类工具变量的方法。
为了创建本地污染的跨境溢出度量,使用来自清华大学地球系统科学中心的数据,该中心已经实施了一系列改进的、基于技术的方法,以建立中国的排放清单。排放量按月估算,并以0.25°×0.25°的空间分辨率捕获。该清单仅包括人类排放的PM 2.5,不包括其他污染物的二次排放,但对于研究来说,这是可以接受的。使用2013年的数据构建工具变量NEIGHBOUR。在这里,假设2013年和2014年之间污染物排放的空间变化及其每月变化是稳定的。这个NEIGHBOUR变量衡量的是城市i在m个月第t天的PM 2.5 浓度如何受到m个月附近网格的工业污染物排放的影响。根据主导风向相对于非主导风向的网格分配不同的权重。具体来说,NEIGHBOUR的定义如下: