点击上方“
朱小厮的博客
”,选择“
设为星标
”
后台回复”
加群
“加入公众号专属技术群

大数据发展至今,数据呈指数倍的增长,对实效性的要求也越来越高,于是像上面这种需求也变得越来越多了。
那这些场景对应着什么业务需求呢?我们来总结下,大概如下:
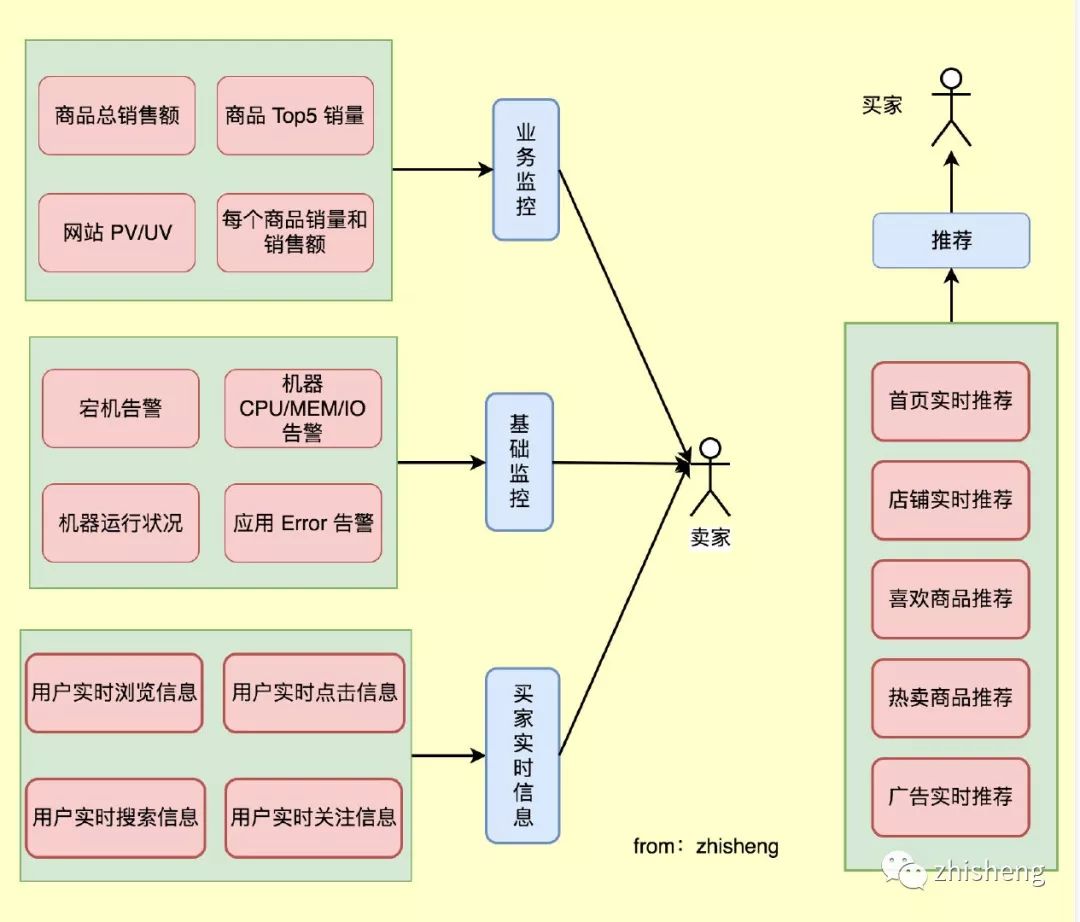
初看这些需求,是不是感觉很难?
那么我们接下来来分析一下该怎么去实现?
从这些需求来看,最根本的业务都是需要
实时查看数据信息
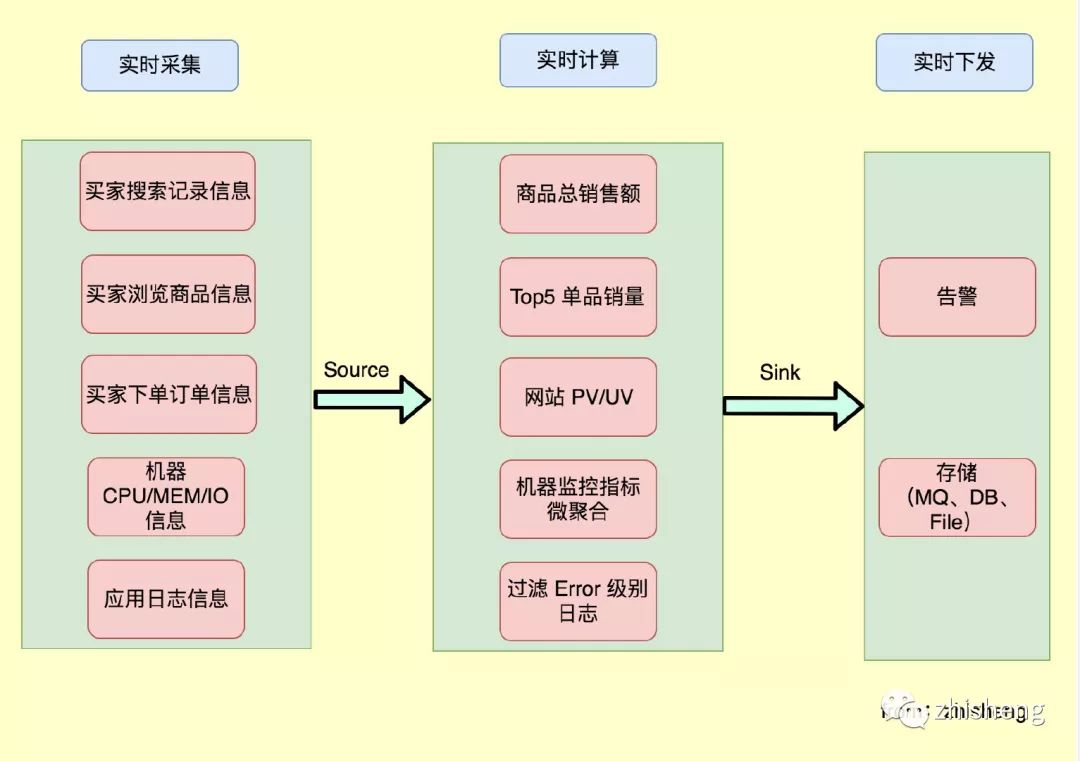
,那么首先我们得想想如何去采集这些实时数据,然后将采集的实时数据进行实时的计算,最后将计算后的结果下发到第三方。
数据实时采集
就上面这些需求,我们需要采集些什么数据呢?
-
买家搜索记录信息
-
买家浏览的商品信息
-
买家下单订单信息
-
网站的所有浏览记录
-
机器 CPU/MEM/IO 信息
-
应用日志信息
数据实时计算
采集后的数据实时上报后,需要做实时的计算,那我们怎么实现计算呢?
数据实时下发
实时计算后的数据,需要及时的下发到下游,这里说的下游代表可能是:
1、告警方式(邮件、短信、钉钉、微信)
在计算层会将计算结果与阈值进行比较,超过阈值触发告警,让运维提前收到通知,及时做好应对措施,减少故障的损失大小。
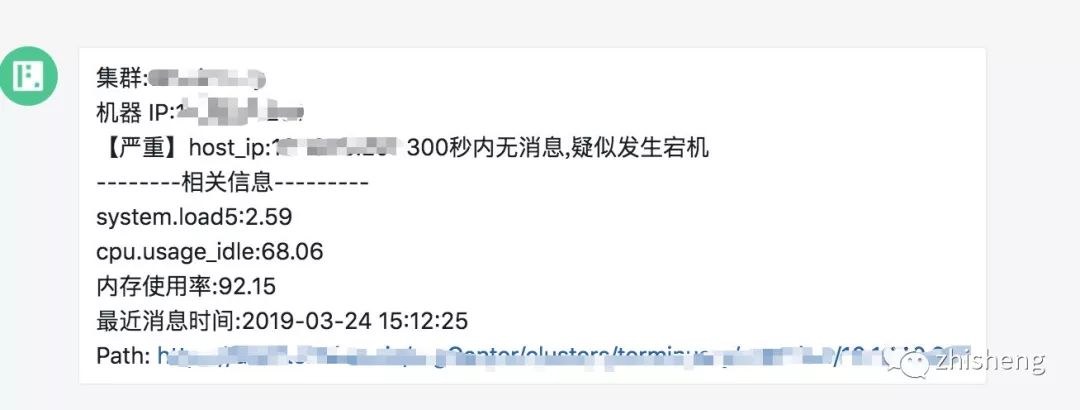
2、存储(消息队列、DB、文件系统等)
数据存储后,监控大盘(Dashboard)从存储(ElasticSearch、HBase 等)里面查询对应指标的数据就可以查看实时的监控信息,做到对促销活动的商品销量、销售额,机器 CPU、MEM 等有实时监控,运营、运维、开发、领导都可以实时查看并作出对应的措施。

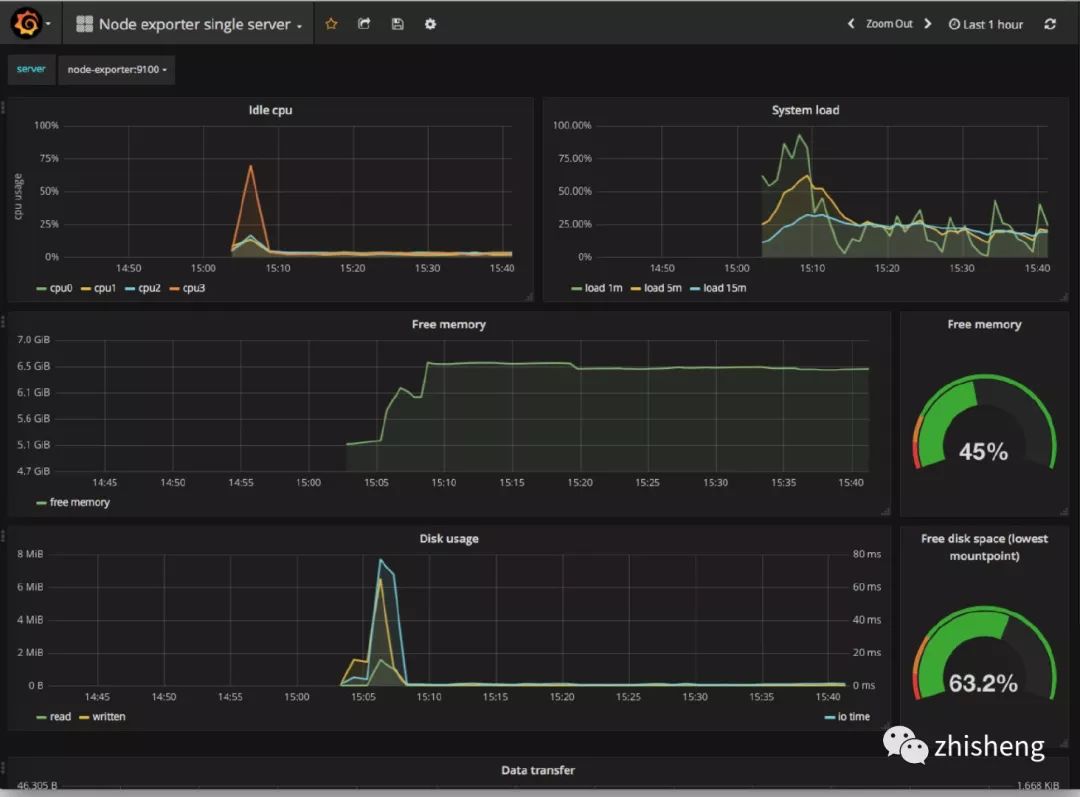
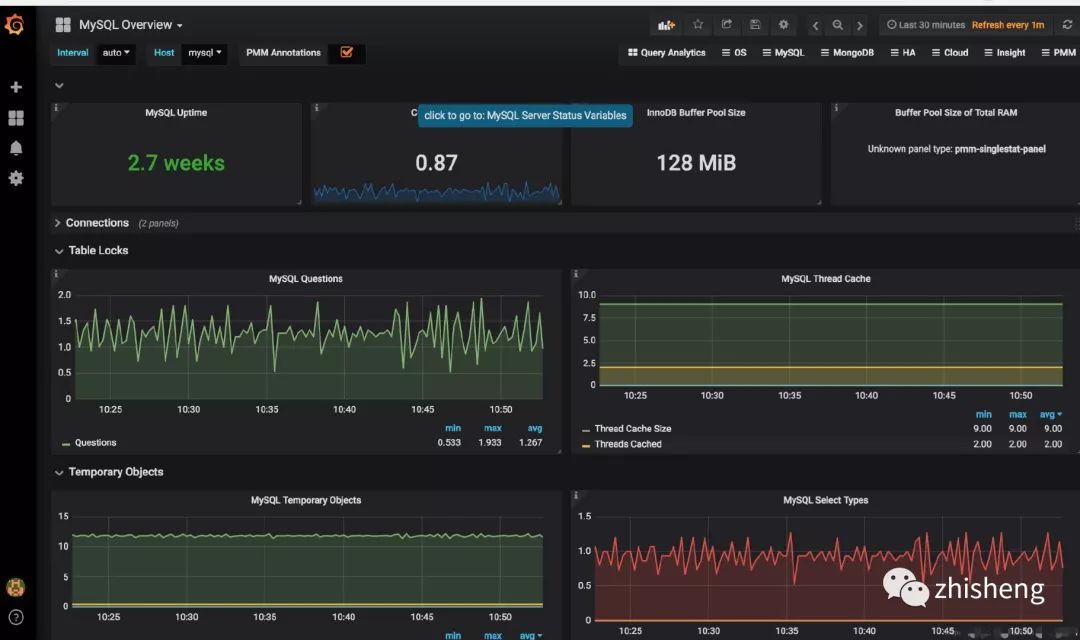
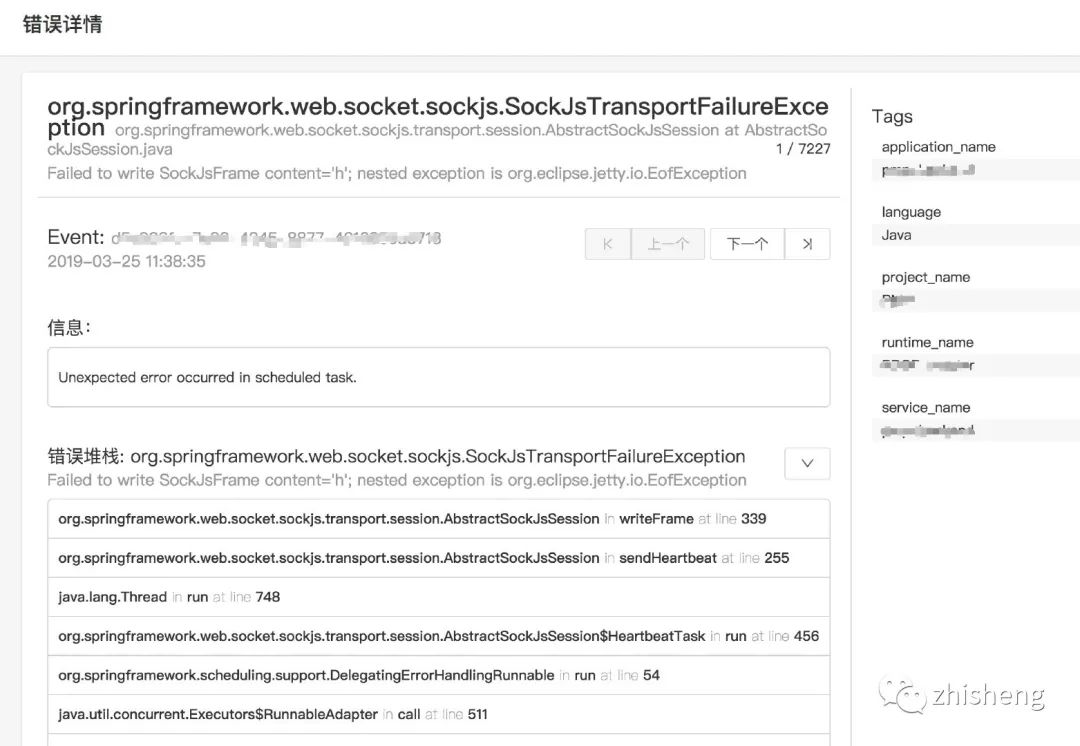

从数据采集到数据计算再到数据下发,整个流程在上面的场景对实时性要求还是很高的,任何一个地方出现问题都将影响最后的效果!
实时计算场景
前面说了这么多场景,这里我们总结一下实时计算常用的场景有哪些呢?
-
交通信号灯数据
-
道路上车流量统计(拥堵状况)
-
公安视频监控
-
服务器运行状态监控
-
金融证券公司实时跟踪股市波动,计算风险价值
-
数据实时 ETL
-
银行或者支付公司涉及金融盗窃的预警
……
另外我自己在我的群里也有做过调研(不完全统计),他们在公司 Flink(一个实时计算框架)使用场景有这些:
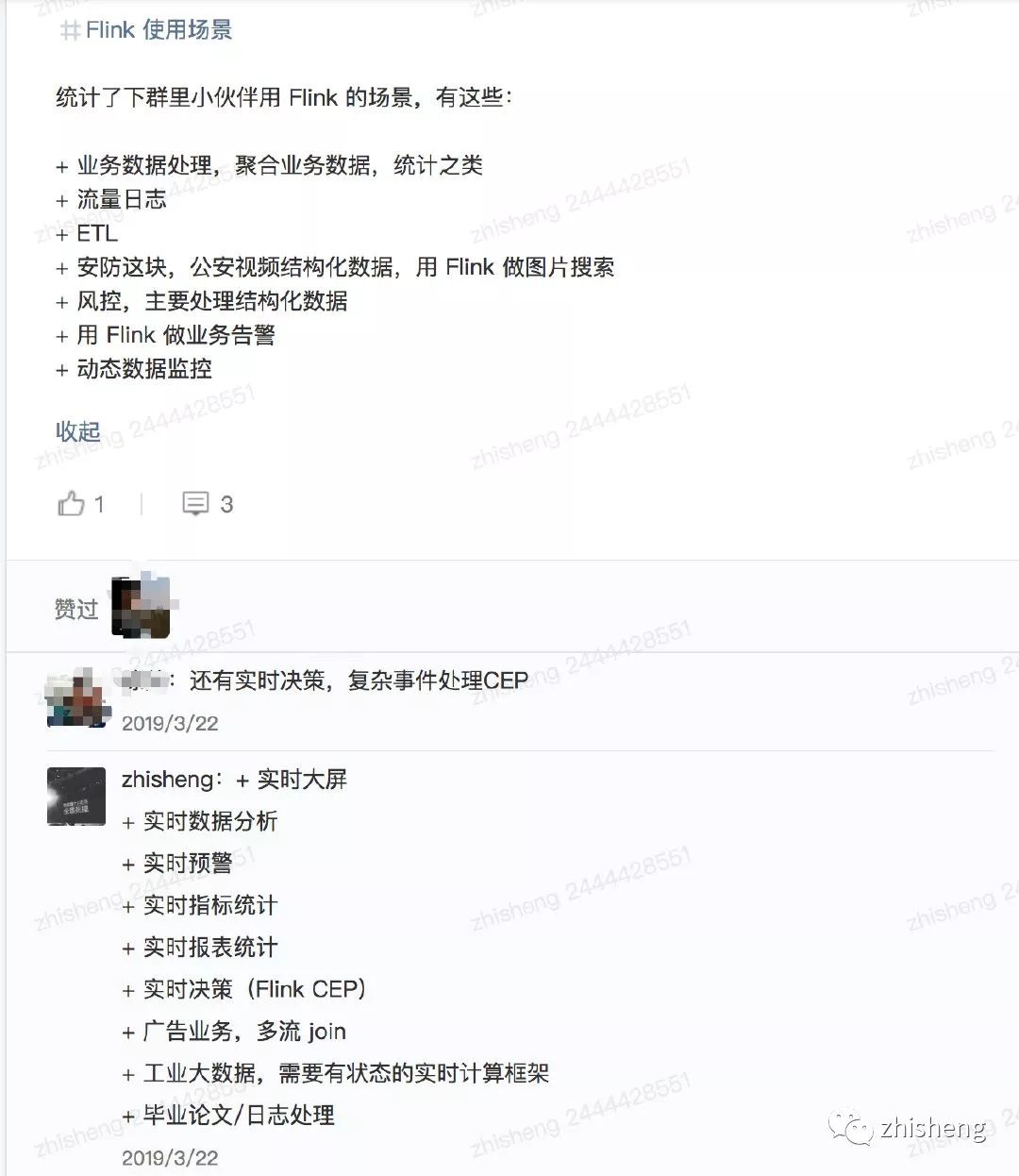
总结一下大概有下面这四类:
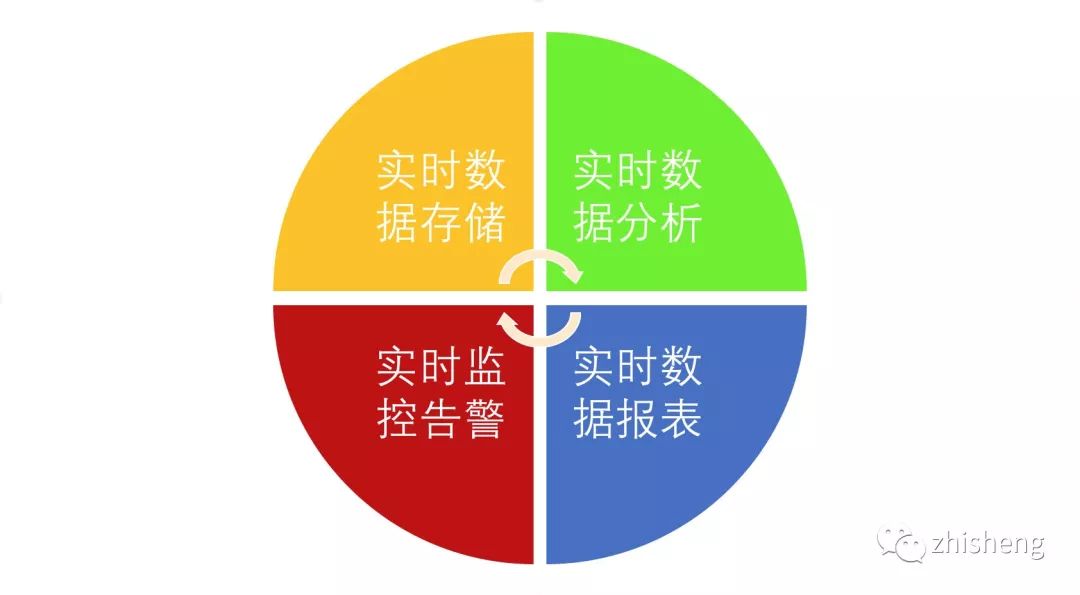
1、实时数据存储
实时数据存储的时候做一些微聚合、过滤某些字段、数据脱敏,组建数据仓库,实时 ETL。
2、实时数据分析
实时数据接入机器学习框架(TensorFlow)或者一些算法进行数据建模、分析,然后动态的给出商品推荐、广告推荐
3、实时监控告警
金融相关涉及交易、实时风控、车流量预警、服务器监控告警、应用日志告警
4、实时数据报表
活动营销时销售额/销售量大屏,TopN 商品
说到实时计算,这里不得不讲一下和传统的离线计算的区别!
实时计算 VS 离线计算
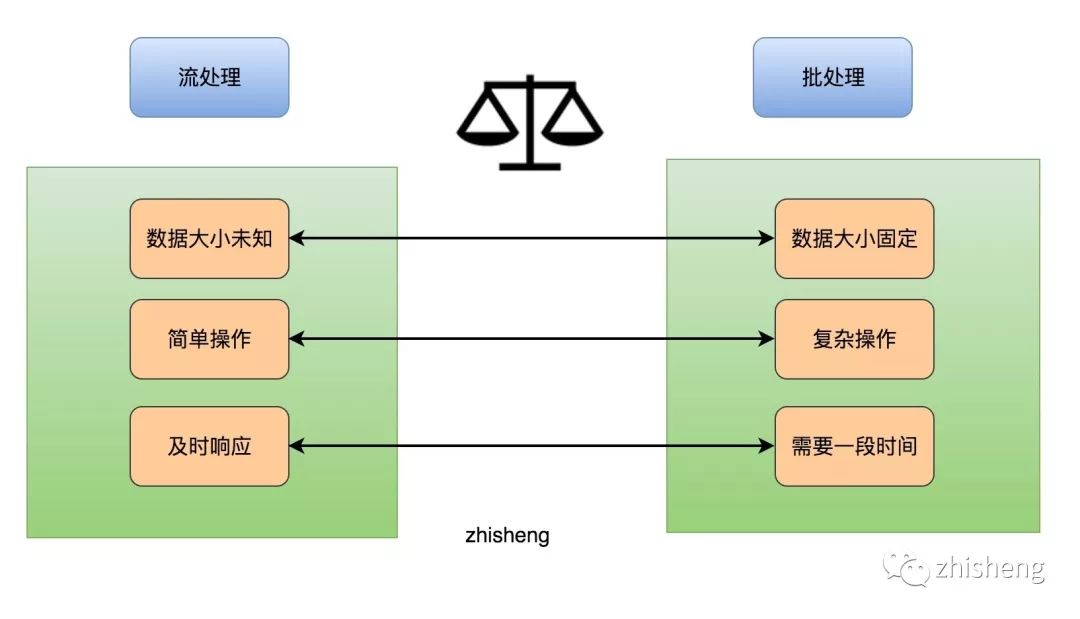
再讲这两个区别之前,我们先来看看流处理和批处理的区别:
流处理与批处理
看完流处理与批处理这两者的区别之后,我们来抽象一下前面文章的场景需求(
实时计算
):
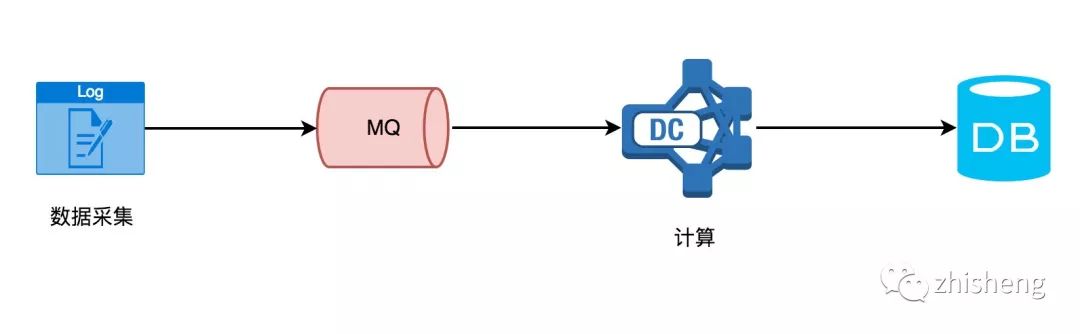
实时计算需要不断的从 MQ 中读取采集的数据,然后处理计算后往 DB 里存储,在计算这层你无法感知到会有多少数据量过来、要做一些简单的操作(过滤、聚合等)、及时将数据下发。
相比传统的
离线计算
,它却是这样的:
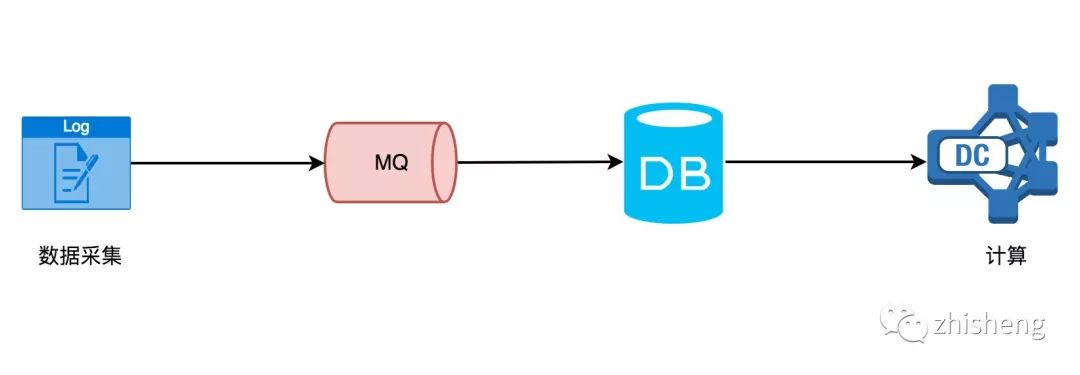
在计算这层,它从 DB(不限 MySQL,还有其他的存储介质)里面读取数据,该数据一般就是固定的(前一天、前一星期、前一个月),然后再做一些复杂的计算或者统计分析,最后生成可供直观查看的报表(dashboard)。
离线计算的特点
实时计算的特点







