
作者介绍:王青,JFrog 中国首席架构师,之前在IBM、爱奇艺、新浪、VIPKID做研发架构,目前专注于 DevOps 和微服务的落地。
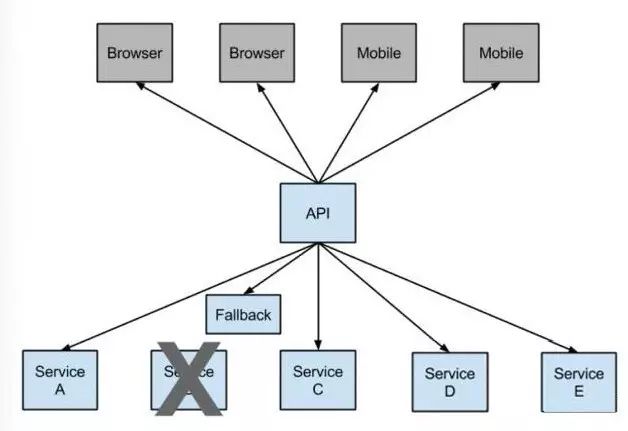
任何一个普通的服务,放到 Netflix 的大规模集群(上万台机器)里运行,如果不做特别处理,会发生各种各样的问题,以实现一个电影推荐的服务为例,传统方案:
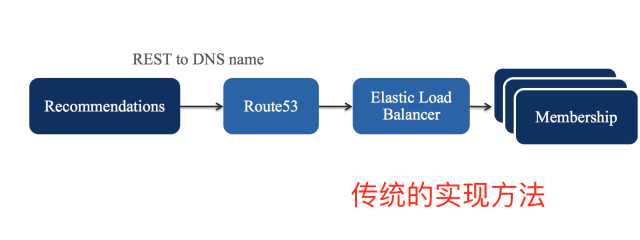
在传统的方案里,你会使用固定 DNS 域名解析服务,将一组固定的 IP 放在负载均衡的列表里。服务注册和发现都是写在配置文件里,一旦服务挂掉了,依赖于这个服务的其他服务都会受到影响,传统的办法只能新起一台服务器,然后去改变其他机器的配置文件,并重启关联的服务。
在小的集群里这种方式或许可以忍受,但在上万台服务器的集群里,管理500多种服务的时候,情况将变得非常复杂,Netflix 通过多年的实践,贡献出了很多开源项目,例如:Eureka、Hystrix、Feign、Ribbon 等等,来解决大规模集群里服务管理的问题。

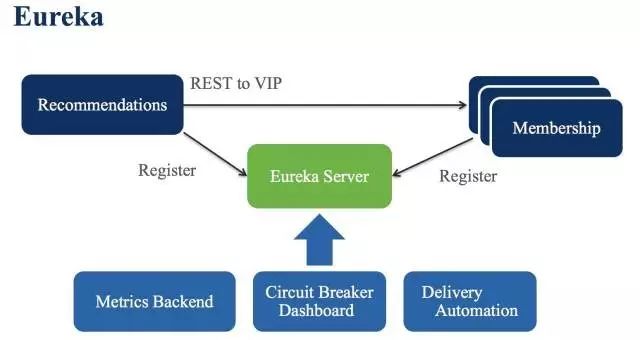
Eureka 是什么?
Eureka 是 Netflix 贡献出来的开源中间层负载均衡和服务发现的工具。Eureka 基于 Java 实现,可以非常方便的在 Spring 应用程序里声明 Server 和 Client 进行服务注册。
Eureka 解决的问题
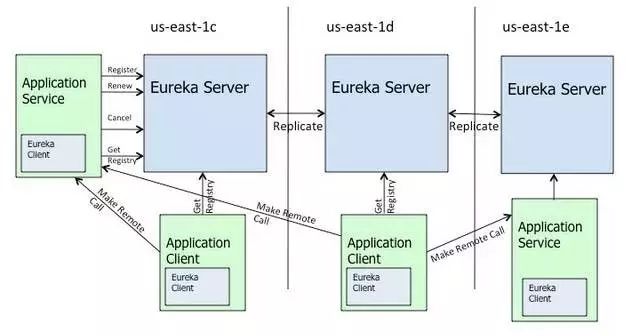
Eureka 服务器是服务的注册中心,它能提高大规模集群环境里服务发现的容错性和可用性。并且可以解决跨数据中心之间的服务注册和发现的问题。
Netflix 推荐在每个 Region 搭建一个 Eureka 集群,每个 Region 里的可用区至少有一个 Eureka Server,这样可以保证任意一个可用区的服务注册信息都会被复制到各个可用区,实现服务信息的高可用。在任意可用区的客户端都可以访问到服务的注册信息。客户端在访问服务器之后会在本地缓存服务的信息,并且定期(30秒)刷新服务的状态。
如果在集群内有大面积的网络故障时(例如由于交换机故障导致子网之间无法通信),Eureka 会进入自我保护模式,每个Eureka节点会持续的对外提供服务(注:ZooKeeper不会):接收新的服务注册同时将它们提供给下游的服务发现请求。这样就可以实现在同一个子网中(Same side of partition),新发布的服务仍然可以被发现与访问。
在 Eureka V1.0的版本里,Eureka 之间的数据同步是全量同步,每个客户端都有 Eureka 集群里所有服务的信息,在 V2.0的版本里,将支持客户端偏好的服务信息同步。同时也会增强 Eureka 的读写分离和高可用性。
有了 Eureka,Netflix 如何做红黑发布?
Netflix 发布的方式是红黑发布。如果监控到线上部署的服务有问题,按传统方式回滚一个服务需要5-15分钟。而 Netflix 使用 Eureka 能够动态的下线/上线一个服务。
服务分两种:REST 服务和非 REST 服务。如果下线的服务是 REST 服务,那么情况比较简单,通过 Eureka 可以实时的实现服务的下线和上线。
如果服务是非 REST 服务,例如执行 Batching 任务或者快服务的 Transaction 等等,就不能简单的标记服务下线,借助于 Spring 提供的 EventListener (事件监听器),Eureka 可以传递EurekaStatusChangeEvent 事件,帮助开发者在这个事件监听器里去做对应的服务下线处理。
Netflix 在实现红黑发布的时候,会先将一部分的服务动态下线,如果这些服务有一些 Batching 任务,则通过事件监听器停掉这些任务。
为什么 Netflix 没有选择使用 ZooKeeper 做服务发现?
因为当 ZooKeeper 在处理上千个节点时,由于故障发生次数不高,可能可以应对,但是达到上万节点之后,ZooKeeper 的表现不如 Eureka,因为在这种体量的集群里,集群故障是时刻都在发生的,如果每次都重新进行选举的代价太大,而 Eureka 会根据 CAP 理论中的 AP 策略,采用了最终一致的方案。
其次,Eureka 提供了 REST endpoint 支持服务的注册,这样解决能 Non-Java 服务的注册问题。
Hystrix 是 Netflix 开源的组件,它能够帮助服务之间调用超时,报错时,阻止问题的扩散,避免雪崩。在用户无感知的情况下对服务进行降级处理。
举例:当你试图为你的用户进行电影推荐时,出于某种原因服务调用一直没有返回(可能依赖的 User 服务挂了),Hystrix 可以定义多种策略来判断服务是否健康。例如:为 Hystrix 预设一个 timeout 时间,如果服务调用的返回结果超过这个时间,Hystrix 会决定触发熔断机制,暂定该服务的调用,并返回一个通用的电影列表作为推荐,而不是让用户无休止的等下去,从而提高用户体验。
当然,超时时间只是 Hystrix 做熔断决策的一个条件,你可以为 Hystrix 设置多个条件来让判断某个服务调用是否正常,比如服务的 corePoolSize,maximumPoolSize and keepAliveTime 都可以作为 Hystrix 熔断的策略。
Hystrix 提供了 Circuit Break 来检测服务的健康状态,Circuit Break 解决了以下问题:
检查服务的状态。
支持线程和资源访问的隔离。当服务的并发访问特别大时(每秒上百个连接),Circuit Break 会对线程进行隔离,或者对资源访问做限制,保证服务的可用性。
下图是 Circuit Break Open/Close 的决策流程:
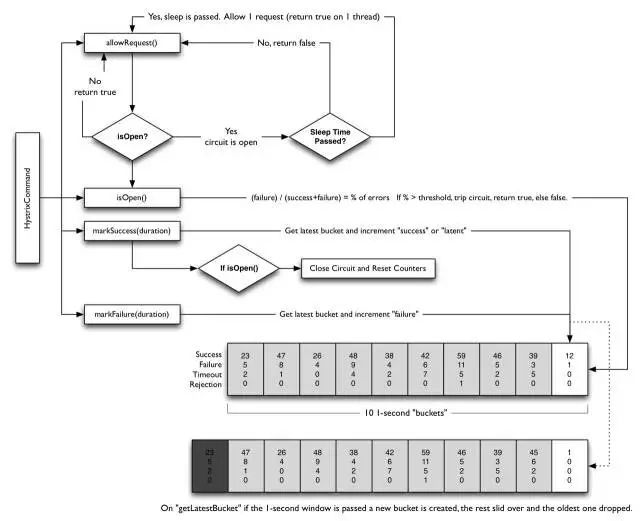
如果服务调用的错误率高于预先设置的错误率。
Circuit-breaker 的状态会从 CLOSED 变成 OPEN(熔断状态)。
当 Circuit-breaker 状态为 OPEN 时,所有进来的请求会被阻止
过一段时间,会让一些单个的请求进来(Half-Open),如果服务调用仍然失败,Circuit-breaker 会再次进入 OPEN 状态,如果请求成功,Circuit-breaker 状态变为 CLOSED 并且重新进入第一步。
目前,Hystrix 正在对跨服务事务(Transaction)处理进行优化中。
Ribbon 是 Netflix OSS 贡献的处理 RPC 调用的软负载均衡。除了传统负载均衡的能力之外,它还能解决以下问题:
当监控到集群内有9台服务器提供同一个服务,其中有三台的响应明显有问题,Ribbon 可以临时将这三台服务器从负载均衡中剔除,直到这三台机器恢复正常的响应。
可以对响应最快的服务器进行加权,将更多的流量带到响应最快的节点。
支持将多种负载均衡的策略同时启用,将负载均衡的效果调试到最好。
自定义设置重试机制。
虽然 Ribbon 项目处于维护状态,但是它的实现思路仍然值得大家借鉴。
本文主要介绍了 Netflix OSS 贡献的 Eureka,Hystrix 和 Ribbon,由于篇幅限制,其他的组件将在后续的文章中介绍, 这些开源组件和 Spring Boot/Spring Cloud 都有良好的集成,通过注解的方式配合 Properties 文件,能够解决管理大规模服务时遇到的通用问题。
本文的目的是希望通过解读 Netflix 在实现大规模扩容时遇到的问题,分析他们的解决办法,为将来自己碰到问题时提供一些思路,思路和视野有时候比工具本身更重要。
参考资料:
随着Docker技术被越来越多的人所认可,其应用的范围也越来越广泛。本次培训我们理论结合实践,从Docker应该场景、持续部署与交付、如何提升测试效率、存储、网络、监控、安全等角度进行。点击识别下方二维码加微信好友了解具体培训内容。







