背景知识
声纹识别
,也称为
说话人识别
,指把不同说话人的声音,按照说话人身份区分开来的技术。有很多英文名:
voice recognition
、
speaker recognition
、
voiceprint recognition
、
talker recognition
。
声纹技术的一些细分方向:
Speaker Diarization
,可翻译为
声纹分割聚类、说话人分割聚类、说话人日志,
解决的问题是“who spoke when”。给定一个包含多人交替说话的语音,声纹分割聚类需要判断每个时间点是谁在说话。声纹分割聚类问题是声纹领域中仅次于声纹识别的第二大课题,其难度远大于声纹识别。单词diarization来自diary。
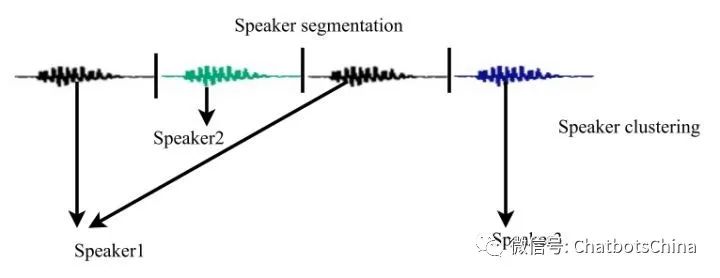 声纹分割聚类(Speaker Diarization)
声纹分割聚类(Speaker Diarization)
Speaker Diarization I:传统方法
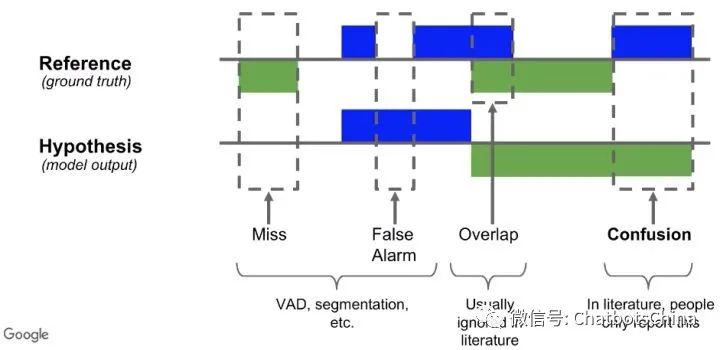
评估指标
Diarization Error Rate (DER)
对模型输出结果尝试各种说话人的排列,最后选效果最好的说话人分配方法计算DER。

整体框架
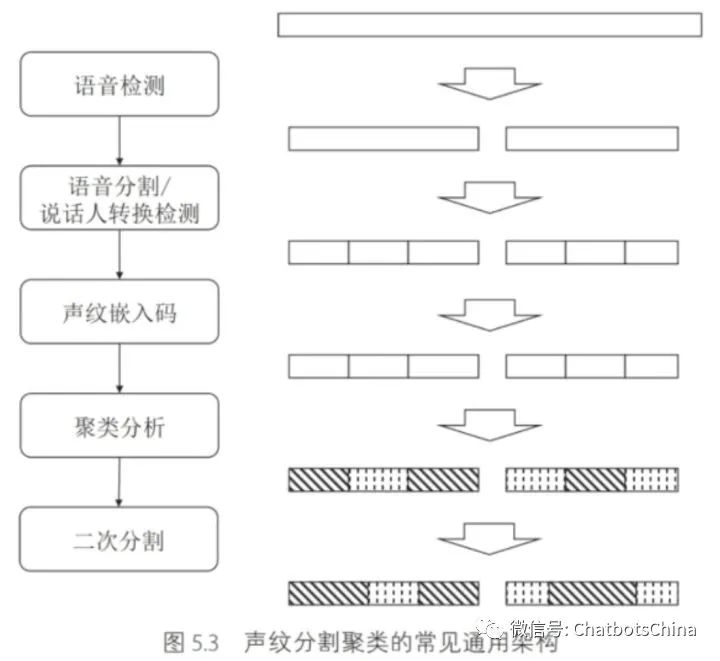
语音检测
利用语音检测模型,将音频帧逐帧分为
语音
(
speech
,即有人说话)和
非语音
(
non-speech
,即无人说话)两个类别。非语音可能是
纯静音(silence)
,也可能是
环境噪音(ambient noise)
、或者
音乐(music)、
音效等其他信号。
常用的语音检测框架有:
可以把语音检测当成标准的序列标注问题求解。
语音分割/说话人转换检测
分割的目标是
分割后的每段音频只有一个说话人
。有两种方法可以把整段语音切分为多个小段:
-
固定长度切分
。比如每段1秒,临近段之间可以有些重叠。好处显然是简单,完全不用模型。
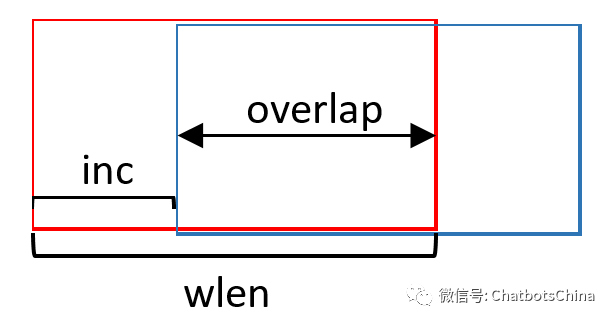
存在的问题:
一般可以把每段长度设为
0.5秒 ~ 2秒
之间。
2. 训练
说话人转换检测模型
(
Speaker Change Detection
,
SCD
),以SCD预测的转换点进行切分。
注
:
SCD只判断转换点,但并不知道转换后的说话人是哪个(说话人数量>2时)。所以SCD后还是需要聚类那个步骤。
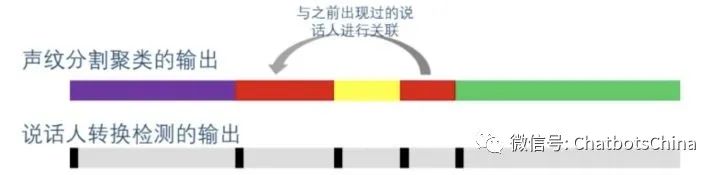
存在的问题:
说话人转换检测模型
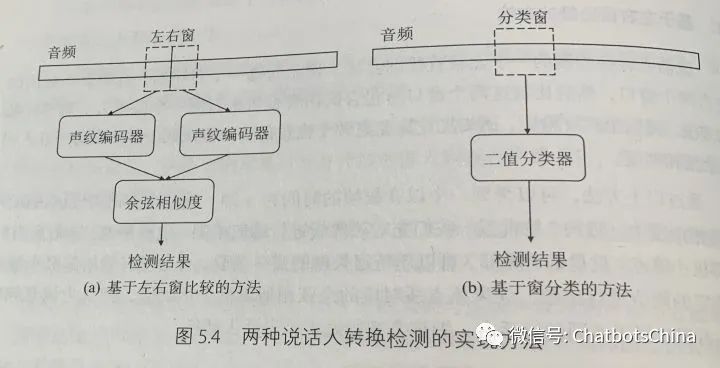
基于左右窗比较的方法
对比左右窗嵌入码的差异性。
基于窗分类的方法
当成标准的序列标注问题求解。
转换点label为1,非转换点label为0。所以两个类别很不平衡。通常会把转换点附近
K
帧(如 K=9)的label都标为1,这样可以缓解类别不平衡问题。另一个缓解类别不平衡问题的方法是使用针对不平衡问题的loss函数,比如
Focal Loss
,亲测有效,通常准确率能提升几个百分点。
声纹嵌入码
训练数据准备
期望训练数据有以下特性:
数据增强
方法:
-
模拟房间的
混响(reverberation)
效果,可使用 pyroomacoustics 包;
-
改变音量;
-
改变音速;
-
改变基频;
-
添加各类噪音;
-
随机子序列法
:在已有的训练数据中,从较长的序列中随机截取较短的序列;
-
随机输入向量法
:保留标签序列,但是将输入序列中的每个嵌入码,替换为从相应说话人的所有嵌入码集合中随机选取一个;
-
嵌入码旋转法
:通过余弦相似度训练得到的声纹嵌入码都位于高维空间的单位球面上,可以通过某个旋转矩阵,将某个输入序列中的所有嵌入码映射到单位球面上的另一些点,且任何两个嵌入码在映射前与映射后其余弦相似度保持不变。
特征
MFCC等。
模型
传统模型:GMM-UBM
利用GMM拟合每个说话人的嵌入码。假设某个说话人的音频特征序列为
 ,利用GMM模拟这些数据。最终学习得到的GMM参数为:
,利用GMM模拟这些数据。最终学习得到的GMM参数为:
 。每个协方差矩阵限定为对角阵,不同说话人使用不同的对角阵,这种设定效果较优。
。每个协方差矩阵限定为对角阵,不同说话人使用不同的对角阵,这种设定效果较优。
对每个说话人都训练好了各自的GMM后(每个GMM的参数为
 ,共 S 个说话人),对于待识别的音频序列
,只需要看看 S 个说话人中谁的概率最高,就认为
,共 S 个说话人),对于待识别的音频序列
,只需要看看 S 个说话人中谁的概率最高,就认为
 来自于此人:
来自于此人:

在很多应用场景,待识别的音频可能来自已知的 S 个说话人之外(集外说话人),也就是模型需要懂得何时拒识。2000年提出的
通用背景模型(universal background model,UBM)
使用一个与说话人无关的GMM来建模集外说话人。UBM的训练数据可以是很多说话人的诸多音频一起构成。
从假设检验的角度分析,如果用
 表示验证音频来自 S 位集内说话人,用
表示验证音频来自 S 位集内说话人,用
 表示验证音频来自集外说话人,用
表示验证音频来自集外说话人,用
 表示通用背景模型的参数,则可以通过对数似然比作为判别的依据(类似使用
BIC
/
AIC
做模型选择,确定样本更可能来自哪个模型,具体可参考 “模型选择的一些基本思想和方法” 和 “贝叶斯因子”):
表示通用背景模型的参数,则可以通过对数似然比作为判别的依据(类似使用
BIC
/
AIC
做模型选择,确定样本更可能来自哪个模型,具体可参考 “模型选择的一些基本思想和方法” 和 “贝叶斯因子”):

引入UBM的另一个好处是集内说话人各自的GMM模型可由UBM模型自适应(以UBM参数值为初始值继续训练)获得,这样对语音数据少的集内说话人模型效果显著。自适应过程也可限定只调整均值向量
 ,而不更改
,而不更改
 和
和
 。
。
把一个说话人的
 个均值向量
个均值向量
 拼接起来,获得的向量称之为
GMM超向量(supervector)
。每个说话人的GMM超向量
拼接起来,获得的向量称之为
GMM超向量(supervector)
。每个说话人的GMM超向量
 可以代表此说话人的音频特征,只是
的维度为
可以代表此说话人的音频特征,只是
的维度为
 ,通常较大。所以会利用因子分析方法对其进行降维:
,通常较大。所以会利用因子分析方法对其进行降维:

这里
 是与说话人和信道都无关的超向量,可以取值为UBM中获得的超向量。而
是与说话人和信道都无关的超向量,可以取值为UBM中获得的超向量。而
 是一个服从高斯分别的随机向量,其维度通常在
是一个服从高斯分别的随机向量,其维度通常在
400~600
之间。
被称为
身份向量
(
identity vector
),简写为
i-vector
。i-vector可以作为说话人的声纹嵌入码。
DL模型
可以利用CNN或RNN等DL模型获得每个音频的定长嵌入向量(称为
d-vector
),每个说话人的嵌入码可以是他所有音频嵌入向量的均值。
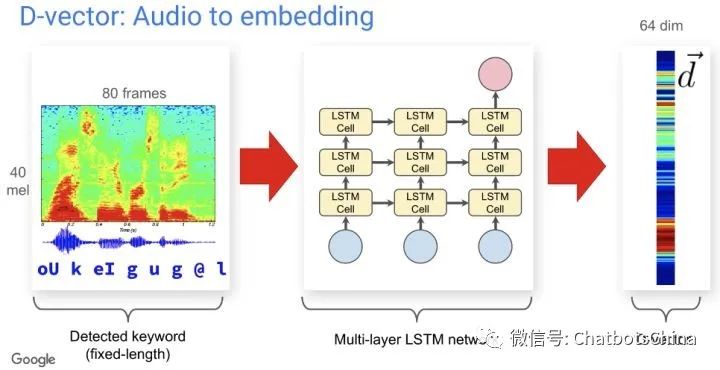
那么,如何训练这种DL模拟呢?逻辑类似度量学习和对比学习,我们期望通过训练让同一个说话人下的音频嵌入向量尽可能靠近,而不同说话人下的音频嵌入向量尽可能远离。以下是声纹识别场景下常用的训练loss。
x-vector
聚类分析
一般的步骤是先构建相似度矩阵,然后再做聚类(很多聚类算法的输入是相似度矩阵)。
常用聚类算法:K-Means、层次聚类、谱聚类。
说话人数量已知的情况下K-Means用的多,未知的情况下谱聚类用的多。
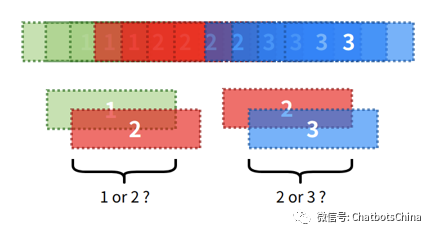
二次分割(re-segmentation)
基于聚类结果获得的分割结果在分界线附近会有歧义。两个类重叠的区域应该划分到哪个类?简单的做法是每个分割片段以其中心点位置作为代表位置。分割在时间维度的精度,称为
时间分辨率(temporal resolution)
。分割片段越长,时间分辨率越低。但分割片段过短,又会导致声纹嵌入码的计算不够准确。
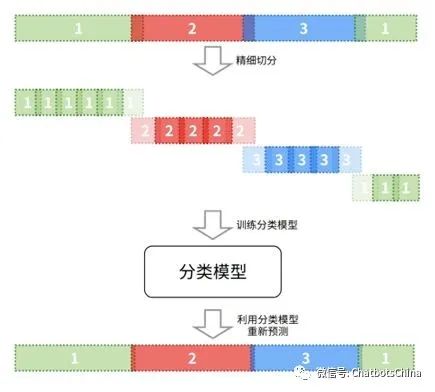
基于分类的二次分割
利用前面的聚类算法,可以得到说话人的数量
 ,以及初始的分割聚类结果
,以及初始的分割聚类结果
 。之后,我们可以对每个音频做更精细化的切分,比如切成更精细的
段(
。之后,我们可以对每个音频做更精细化的切分,比如切成更精细的
段(
 )。对这些新的
段抽取其声纹嵌入码
)。对这些新的
段抽取其声纹嵌入码
 ,找到它们对应的说话人标签
,找到它们对应的说话人标签
 。这样就可以利用
。这样就可以利用
 训练一个新的分类模型。训练好的分类模型可以用来预测$$M$$段音频的标签,最后获得歧义更小的新分割结果。流程如下图:
训练一个新的分类模型。训练好的分类模型可以用来预测$$M$$段音频的标签,最后获得歧义更小的新分割结果。流程如下图:
当然,
要避免新训练的分类模型过拟合
。对于
个数据中有歧义(重叠部分)的样本,可以考虑降低其权重或者直接扔掉。
此外,也可以在二次分割时,额外增加一个新的类表示非语音信号,例如静音或者纯噪音或者音乐等。
基于HMM的二次分割
前面介绍的模型在对每小段做分类时,临近小段之间的分类预测是相互独立的。但语音是具有连续性的,相邻小段的说话人有较大概率是同一个人。例如下面这种情况,模型只把中间一个小段以较低置信度分类为说话人2,此时如果考虑到临近小段的分类是相关的,更合理的分类方式是把这个2调整为1。

HMM可以把这种临近分类相关性的特性考虑进来。将每小段的声纹嵌入码
 作为我们的观察变量,将每小段的标签
作为我们的观察变量,将每小段的标签
 作为隐藏状态。HMM希望获得一组隐藏状态的值
作为隐藏状态。HMM希望获得一组隐藏状态的值
 ,使得如下概率最大:
,使得如下概率最大:

其中
 可以用前面描述的训练好的分类模型获得。
可以用前面描述的训练好的分类模型获得。
 可以把标签的时间连续性考虑进来。求解会用到维特比(Viterbi)算法,所以这种方法也被称为
维特比二次分割
。
可以把标签的时间连续性考虑进来。求解会用到维特比(Viterbi)算法,所以这种方法也被称为
维特比二次分割
。
Speaker Diarization II:监督式聚类
无界交织态RNN(UIS-RNN)
英文:
Unbounded Interleaved-State
Recurrent Neural Network (
UIS-RNN
),是一个贝叶斯非参数(Bayesian nonparametric,BNP)模型。

已知一段音频中的T个声纹嵌入码所组成的观察序列
 ,以及这些嵌入码对应的说话人标签序列
,以及这些嵌入码对应的说话人标签序列
 。序列
。序列
 是一个二值序列,表示每个
是一个二值序列,表示每个
 是否与前一个说话人标签不同,即
是否与前一个说话人标签不同,即
 。可见给定
。可见给定
 的取值时
的取值时
 的取值就完全确定了。
的取值就完全确定了。
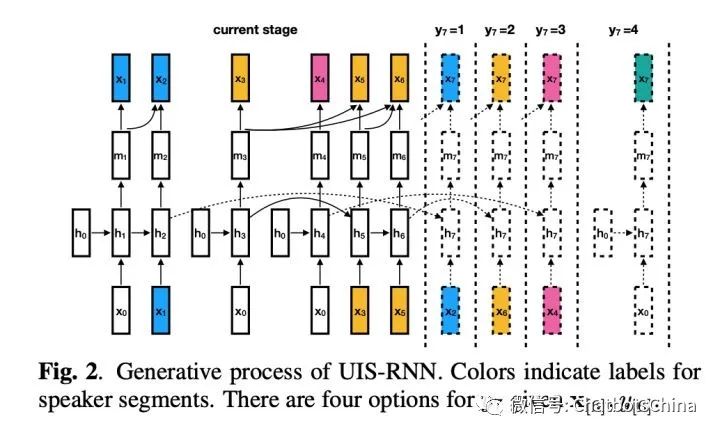
UIS-RNN 期望估计出一组模型参数,使得以下分布的概率值最大化:

其中下标
 用来表示从
用来表示从
 到
到
 的整个子序列。所以
的整个子序列。所以
 ,
,
 ,以及
,以及
 。可见整个模型包括三个部分:
说话人转换模型、说话人分配模型、序列生成模型
。
。可见整个模型包括三个部分:
说话人转换模型、说话人分配模型、序列生成模型
。
通过最大似然估计训练得到模型的参数:

说话人转换模型
说话人转换模型采用了最简单的形式,将每一个
 看做相互独立的0-1二值分布:
看做相互独立的0-1二值分布:

其中,参数
 是模型中的唯一参数。
是模型中的唯一参数。
说话人分配模型
如果在时刻 t-1,已经出现了
 位说话人,且在时刻 t,由于
位说话人,且在时刻 t,由于
 ,我们认为说话人发生了转换,那么
的概率满足:
,我们认为说话人发生了转换,那么
的概率满足:




