柯洁和 AlphaGo 的人机大战第一局已经宣告结束。经过近四个多小时的比赛,由Deepmind团队研发的围棋人工智能执白1/4子战胜了目前等级分排名世界第一的中国棋手柯洁九段,暂时以1比0领先。
面对这个结果,大家都已经不再惊讶,但是我们看到的比赛背后的一些东西,远比结果更加重要和有趣。
AlphaGo v2.0
但少有人注意到的是,昨天和柯洁对战的 AlphaGo,已经不是去年和李世乭对战的那个 AlphaGo。
在一年的时间里,AlphaGo 的架构已经发生了重大的变化。你可以称其为 AlphaGo 2.0 版本。

李世乭九段在韩国迎战AlphaGo
第一个重大变化在于硬件。具体来说,从 CPU+GPU 的组合,变为采用 TPU。
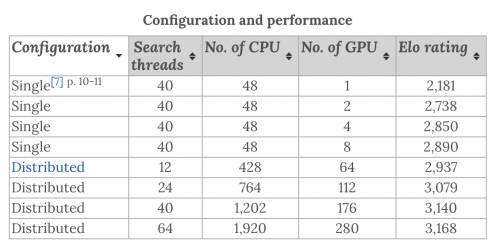
发表在《自然》的论文里明确显示,一开始在 2014 年,AlphaGo 采用的是一个单机箱的异步计算架构,可以用 48 个 CPU(中央处理器)核心搭配 1、2、4、8 个 GPU(图形处理器)来组合出几种不同的配置。
但到了 2015 年 10 月,DeepMind 已经为 AlphaGo 新设计了一个分布式的计算架构:还是用 CPU 和 GPU,只是这次数量多到惊人,可以用到多达 1920 个 CPU 核心和 280 个 GPU,你可以理解为 DeepMind 为了让 AlphaGo 的性能更好配了一台超级计算机。然而,即便在最高配置上,AlphaGo 的围棋等级分 (Elo Rating) 只能达到 3168,在现在世界围棋选手排名中勉强挤进前 260 名。
为什么要从单机箱改成分布式计算?这是因为在围棋对弈中时间是非常重要的因素,你用的时间比对手少,对手就可能比你提前进入读秒的紧张阶段,被迫在思考不足的前提下落子,而你却有更多时间地靠。AlphaGo 采用一种名叫蒙特卡洛树搜索的技术,不停地对下一步的棋盘、再下一步和再再下一步的棋盘可能出现的状况进行大量的计算,从而找到结果最优的下一步落子位置。而这个搜索进程需要时间,因此每一手之间给 AlphaGo 越多的时间,它能计算出越好的结果(当然,时间对结果优劣程度的帮助是递减的)。
在最早的 AlphaGo 论文中我们可以看到,从单机箱向分布式计算演进,在树形搜索进程数量在 40 不变的前提下,AlphaGo 的等级分获得了一次非常不错提升,从 2890 提升到了 3140。

但如果继续增加 CPU 核心 和 GPU 数量呢?在前面第一个图表里我们看到,搜索进程数增加到了 64,等级分继续提高到 3168:
CPU 和 GPU 所用的数量暴增了 60%,等级分却只提升了 28。
显然堆 CPU 和 GPU 不是一个完美的解决方案,接下来怎么办?
在去年 3 月和李世乭的交战中,AlphaGo 首次用到了一个名叫 TPU 的东西。TPU 全名 Tensor Processing Unit(张量处理单元),专门用于机器学习训练和推理深度神经网络的处理器,非常适合 TensorFlow 开源机器学习框架。

Cloud TPU
而 AlphaGo 就是用 TensorFlow 训练出来的,跑在 TPU 上性能提升巨大,可以说跟之前基于 CPU+GPU 的分布式计算系统相比,获得了一次重大的升级。从李世乭比赛之后,AlphaGo 都迁移运行在 TPU 上了。
但这还不是 AlphaGo 的 2.0 时代,更像 1.3。
真正让 AlphaGo 升级到 2.0 的是它的学习思路变化。
在和李世乭交战之前,AlphaGo 的训练方式就是学习人类的棋谱。然而人类的对弈思路相对来说已经比较固定,在相当长的一段时间内已经没有太多充满创造力的新招式出现了,因此 DeepMind 给 AlphaGo 设定了一个新的学习方式,让它摒弃人类的思维定式自己跟自己下棋,左右互搏。
关于这个新的学习方式,去年韩国比赛期间社交网络上流传一个笑话:跟 AlphaGo 下完棋,李世乭回家睡了一觉,舒缓压力整理思路,AlphaGo 却连夜又自己跟自己下了一万局……玩笑之余,这也是为什么我们在 AlphaGo 和李世乭、后来的 Master,以及昨天和柯洁的对弈中,总能看到一些让人搞不清到底是程序出了 bug 还是真的颇具新意的招式。就好比神仙打架,人又怎么理解的了呢?
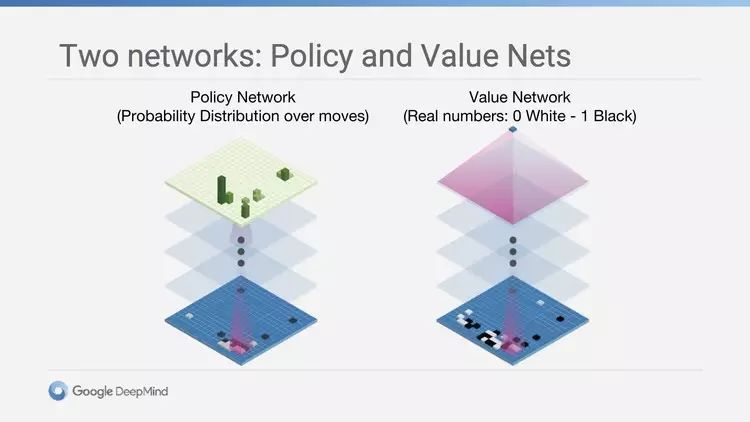
效用函数和策略函数,分别对应 AlphaGo 的两个思考维度:目前棋盘的现状,和自己/对手下一步的走向
更重要的是,通过自己跟自己下棋,AlphaGo 产生了大量的新棋谱数据。这些左右互搏的棋谱和最一开始训练输入的人类棋谱并没有太大不同,也意味着 AlphaGo 已经能自己生产继续进化下去所需要的数据了。
AlphaGo 的思维方式也特别。它不考虑赢面的大小,因为它只关注一件事情:下一步落在哪里,获胜的几率最高。对此,OpenAI 的科学家安德烈·卡帕西 (Andrej Karpathy) 的评论





