问题
上次跟好基 黄东旭 在咖啡厅撩天的时候谈笑风生地探讨了一个 TiDB 使用 Raft 时遇到的问题:
TiKV 层的 Raft 实现, 使用的是 Raft 单步变更 算法(每次添加或删除一个节点), 例如副本由
abc
变成
bcd
过程中, 先加入
d
, 变成
abcd
, 再去掉
a
变成最终配置
bcd
.
这中间经历的4节点的状态
abcd
, 有可能在出现二分的网络割裂(
ad | bc
)时导致整个集群无法选出leader. 这种网络割裂在跨机房部署时容易出现, 例如 a, b, c 三个节点部署在3个机房:
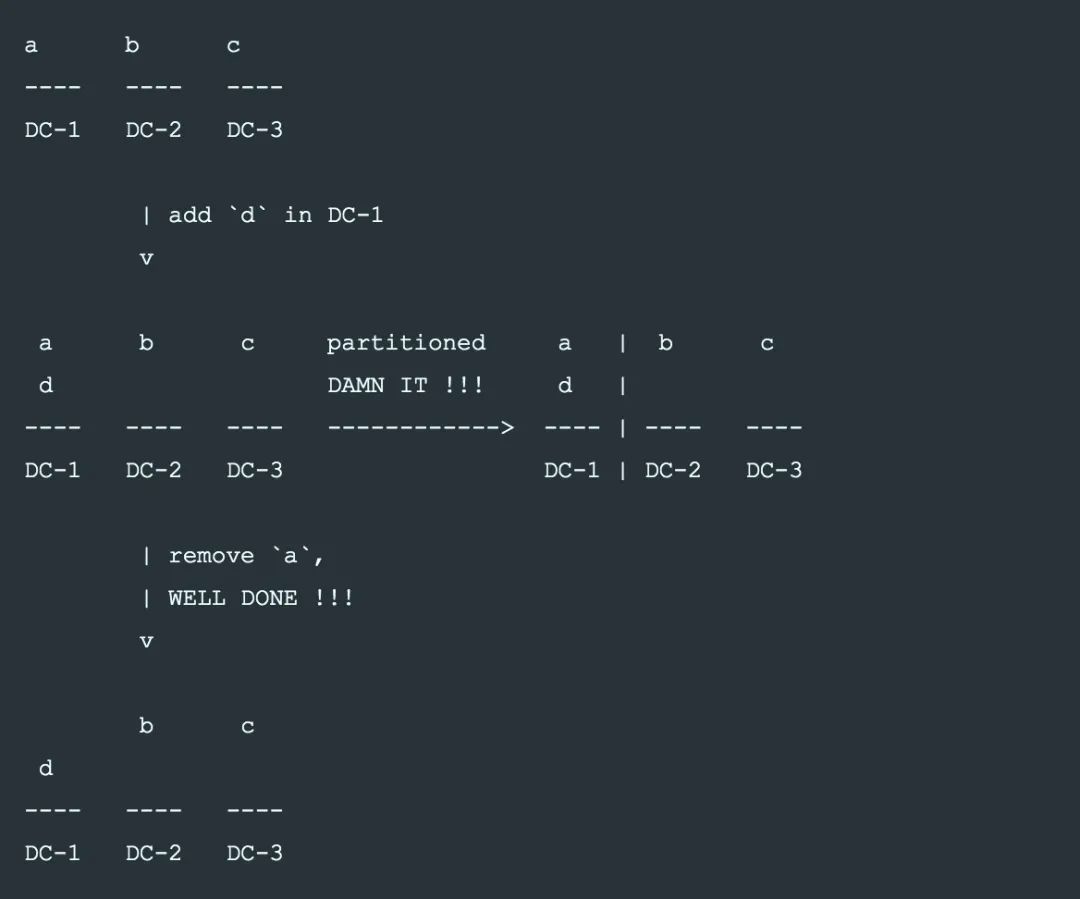
-
正常情况下, 任意一个机房和外界连接中断, 都可以用剩下的2个机房选出leader继续工作.
-
在成员变更过程中, 例如上面需要将DC-1中的 a 节点迁移到 d 节点, 中间状态 DC-1 有 ad 2个节点. 这时如果 DC-1 跟外界联系中断, 由于4节点的 majority 需要至少3个节点, 导致 DC-1 内部无法选出 leader, DC-2 和 DC-3 也不能一起选出一个leader.
在4节点的中间状态, 任一 majority 都必须包含 DC-1, 从而 DC-1 就成了系统的
故障单点
.
当时给东旭一个提权重的方式解决这个问题. 后来想来这可能是一个分布式生产环境中比较常见的问题, 于是做下整理, 这个版本比当时给东旭的解决方案简化了一下, 加了一些简单的证明.
这个问题的根本原因在于, Raft 单步变更算法对 quorum 定义得过于死板, 仅用了 majority. 解决问题的关键就在于打破这个限制, 我们将从 quorum 的视角解释为何 Raft 的单步变更是一个
看起来很香的鸡肋
. 然后再从工程的角度找一个简单又容易的实现方案, 也就是joint consensus.
从 quorum 的视角分析系统的方法, 可以参考我之前这篇文章:
后分布式时代: 多数派读写的’少数派’实现
.
分析和尝试
先看看在这个问题中, 整个系统的 quorum 集合都有哪些:
-
初始状态 abc 的 quorum 的集合是 abc 所有的 majority: M(abc) = {ab, ac, bc}, (abc虽然也是一个quorum, 但可用ab ∪ bc得到, 就不必列出了, 我们只需要列出 quorum 集合中无法由并集求出的那些集合);
-
最终状态 bcd 的 quorum 的集合 M(bcd) = {bc, cd, bd};
-
单步变更的中间状态 abcd 的 quorum 集合也是一个 majority 集合: M(abcd) = {abc, abd, acd, bcd};
单步变更的过程是也就是 quorum 集合变化的过程:
M(abc) → M(abcd) → M(bcd)
在我们这个网络割裂造成的可用性问题中, 直接原因是中间状态的 quorum 要求至少3个节点, 如果网络割裂成
ad | bc
时, ad 或 bc 都不是一个 quorum. 导致无法选主.
那么要解决这个问题似乎也很简单: 在4节点的中间状态中, 试试也
允许 bc 作为一个合法的 quorum
看行不行? 重新定义4节点 abcd 的 quorum 集合是:
Q(abcd) = M(abcd) ∪ {bc}
即,
如果一条日志复制到 bc 或 abcd 的一个 majority, 都可以commit.
因为 bc 和 M(abcd) 中每个 quorum 都有交集, 加入 bc 后的 Q(abcd) 还是一个完整的 quorum 集合, 那就可以在新的中间状态安全的运行 paxos 或 Raft. 一致性仍然得到了保证!
而整个变更过程也变成了: M(abc) → M(abcd) ∪ {bc} → M(bcd).
另外,
如果 Raft 保证 M(abc) → M(abcd) 的单步变更正确性, 那它也可以保证 M(abc) → M(abcd) ∪ {bc} 的正确性
.
这是因为 Raft 单步变更的正确性保证是: 两个节点集合 C₁ 到 C₂ 的变更中, C₁ 的一个 quorum 跟 C₂ 的一个 quorum 都有交集.
同理 M(abcd) ∪ {bc} → M(bcd) 也能保证正确.
这样我们就从治标的层面上解决了变更过程中的网络割裂造成的可用性问题.
然后再深入一点, 4节点的中间状态的 majority 具有这种可用性缺陷的原因在于,
majority 集合 M(abcd) 不是 4节点的最大的 quorum 集合
, majority 在节点数是
奇数
的情况下还算勉强可以用, 解决了大多数问题. 而在节点数是
偶数
的时候,
majority 没有能力描述系统最大的 quorum 集合
.
majority 是 Raft 设计上的第一个不足
. Raft 选择 majority 的同时, 就自宫的降低了自己的可用性.
4节点系统的 majority 的缺陷
4节点系统中, 除了4个3节点的 quorum, 还可以至多包含3个2节点的quorum:
我们可以为4节点系统设计一个改进版的 quorum 集合 Q’(abcd) = M(abcd) ∪
{ab, bc, ac}
, 可以看到 Q’(abcd) 中任意2个元素都有交集, 运行 paxos 或 Raft 是完全没有问题的.
很多分布式系统的论文描述都以奇数个节点作为前提假设. 因为奇数节点可用性的性价比更高, 而忽略了偶数节点数的情况的介绍.
majority 的扩张
综上, 我们可以改进下集群的 quorum 配置, 来提升系统的可用性(解决二分网络割裂问题). 假设节点集合是C, 例如 C = {a,b,c}
-
对奇数节点, n = 2k+1, 还是沿用
多数派
节点的集合, 大部分场合都可以很好的工作:

-
对偶数节点, n = 2k,
因为n/2个节点跟n/2+1个节点一定有交集
, 我们可以向 M(C) 中加入几个大小为 n/2 的节点集合, 再保证所有加入的 n/2 个节点的集合都有交集, 就可以构建一个扩张的 quorum 集合了.
以本文的场景为例,
要找到一个更好的偶节点的 quorum 集合, 一个方法是可以把偶数节点的集群看做是一个奇数节点集群加上一个节点x:

于是偶数节点的 quorum 集合就可以是 M(D) 的一个扩张:

当然这个x可以随意选择, 例如在abcd的例子中, 如果选x = d, 那么 Q’ = M(abcd) ∪ {ab, bc, ca}; 如果选x = a, 那么 Q’ = M(abcd) ∪ {bc, cd, bd}. 这2个4节点 quorum 集合比 M(abcd) 包含更多的 quorum, 因此都可以提供比 M(abcd) 更好的可用性, 在本文开始提出的问题中, 都可以解决本文开头提到的网络割裂的问题.
-
可以设置 Q’ = M(abcd) ∪ {ab, bc, ca}, Q’中任意2个元素都有交集;
-
也可以是 Q’ = M(abcd) ∪ {bc, cd, bd};
-
但不能是 Q’ = M(abcd) ∪ {ab, bc, cd}, 因为 ab 和 cd 没有交集;
解决方案
看了这几个例子之后, 我们发现, 成员变更的中间状态不需要必须是 majority 的 quorum 集合, 只要满足某些变更的正确性条件, 并包含bc就可以了.
例如, 在变更的中间状态,
-
可以不选 M(abcd) ∪ {ab, bc, ac},
-
选 {abc, abd, acd, bcd, bc} 也可以,
-
去掉abc, 选{abd, acd, bcd, bc} 也可以.
而且, 似乎那个看起来复杂(实则更简单的) joint consensus 也可以.
成员变更的正确性条件
我们都用 quorum 集合的方式, 替代节点集合方式来描述系统. 就像
多数派读写的少数派实现
中描述的. 例如:
-
3节点 {abc}, 选择 majority 作为 quorum 集合, 则可以定义这个系统是 Q(abc) = {ab,bc,ca}
-
4节点 {abcd}, 选择 majority 作为 quorum 集合, 则定义这个系统是 Q(abcd) = {abc,abd,acd,bcd},
-
4节点 {abcd}, 选择 majority 的一个扩张作为 quorum 集合, 可以被定义为 Q’(abcd) = {abc,abd,acd,bcd,ab,bc,ac},
要选择一个正确且高效的成员变更算法, 需要满足几个条件. 假设系统要从 Q₁ 变更到 Q₂:
-
提交的变更必须可见, 换句话说, 如果系统中有一个已提交的变更, 未提交的变更必须能被识别出来.
-
并发的变更只有一个能成功, 因此多个变更进程必须选择一个相同的 Q 作为提交变更的 quorum 集合. 多个进程共识的数据只有 Q₁, 因此变更必须提交到 Q₁ 或 Q₁ 的一个确定的扩张.
-
变更必须提交到 Q₂ 中的一个 quorum 中.
然鹅, Raft 最初的单步变更算法没有满足上面的第1条, 后来作者做了修正, 我们最后来聊.
一定要用joint consensus
joint consensus 完全满足上面的正确性保证, 且我们将看到, 它刚好在网络割裂的问题上有很好的表现.
从abc变更到bcd的过程中, joint consensus的中间状态 是通过 M(abc) 和 M(bcd) 的乘积构建的: Q = M(abc) x M(bcd); 即, 一个joint quorum 同时包含 M(abc) 的一个 quorum 也同时包含 M(bcd) 的 quorum.
在我们的例子里, M(abc) = {ab,bc,ca}, M(bcd) = {bc, cd, bd}, 因此:
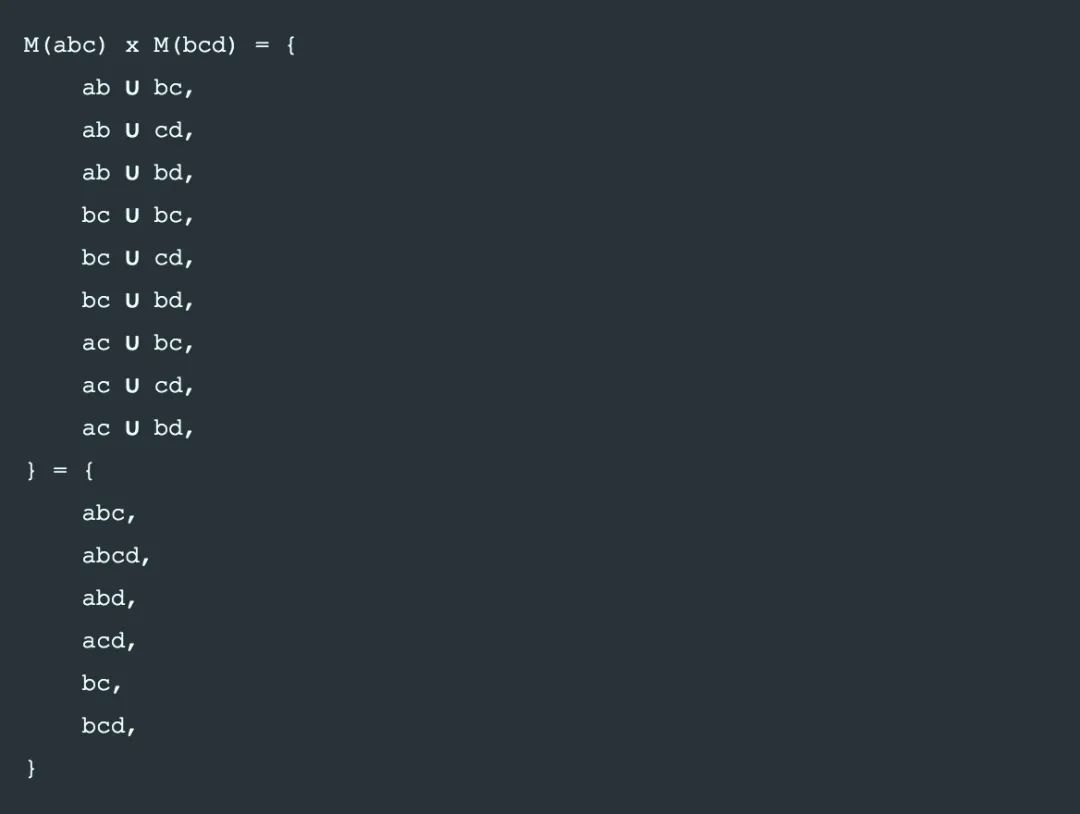
刚好就是M(abcd) ∪ {bc}
太优秀了有木有!!!
容易看出, joint consensus 不仅满足了成员变更的正确性条件, 而且刚好满足了我们的所有要求:
-
容忍1个节点宕机;
-
一定包含{bc}, 容忍
ad | bc
的网络隔离.
-
另外, 整个变更过程, 不论有没有切换leader, 都可以通过2条日志的commit来完成.
太优秀了有木有!!!
太优秀了有木有!!!
Raft 单步变更的bug
不仅 Raft 的单步变更无法更详细的指定偶数节点集群的 quorum 集合, 更严重的是, 它在最初提出时是有 bug 的. 看似巧妙实则幼稚的单步变更, 在修正后就跟 joint consensus 相比没有任何优势了.
单步变更在 leader 切换和成员变更同时进行时会出现bug. 这个 bug 在2015年就已经被作者指出了:
Unfortunately, I need to announce a bug in the dissertation version of membership changes (the single-server changes, not joint consensus). The bug is potentially severe, but the fix I’m proposing is easy to implement.
以下是一个单步变更出 bug 的例子, 原成员是4节点abcd, 2个进程分别要加入u和加入v, 如果中间出现换主, 就会丢失一个已提交的变更:
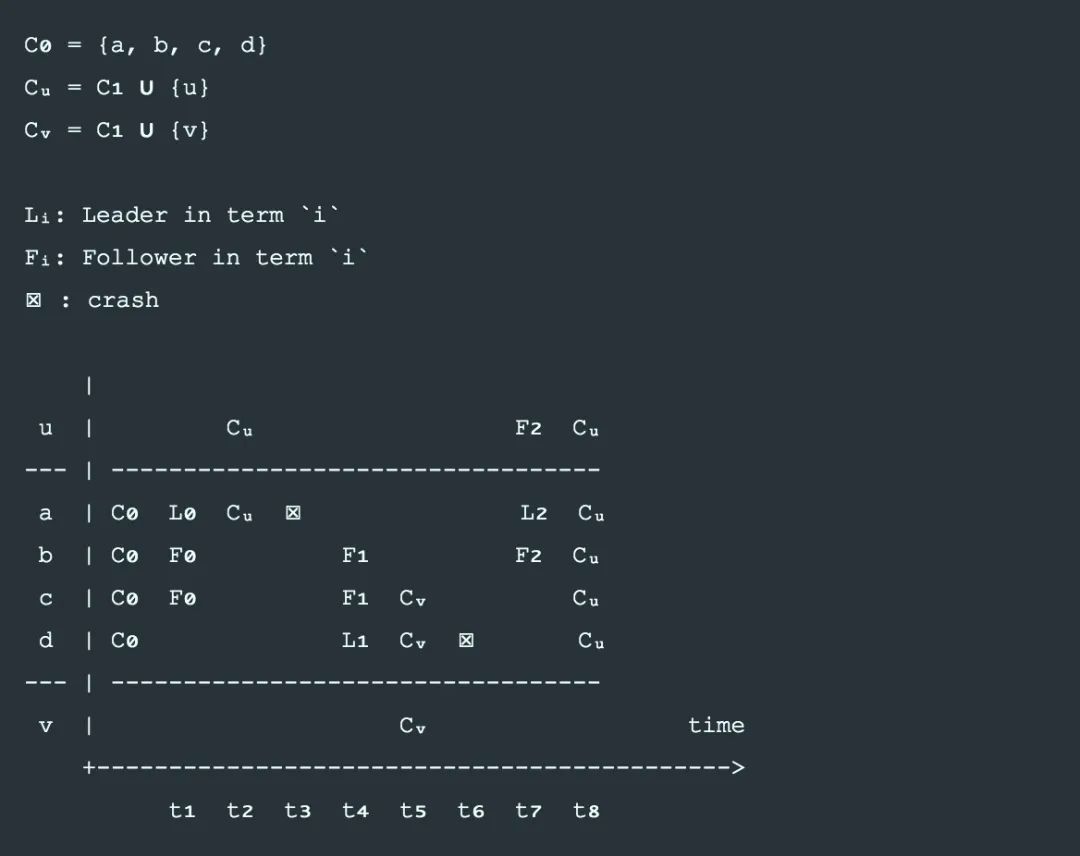
-
t₁:
abcd
4节点在 term 0 选出leader=
a
, 和2个follower
b
,
c
;
-
t₂:
a
广播一个变更日志
Cᵤ
, 使用新配置
Cᵤ
, 只发送到
a
和
u
, 未成功提交;
-
t₃:
a
宕机
-
t₄:
d
在 term 1 被选为leader, 2个follower是
b
,
c
;
-
t₅:
d
广播另一个变更日志
Cᵥ
, 使用新配置
Cᵥ
, 成功提交到
c
,
d
,
v
;
-
t₆:
d
宕机
-
t₇:
a
在term 2 重新选为leader, 通过它本地看到的新配置
Cᵤ
, 和2个follower
u
,
b
;
-
t₈:
a
同步本地的日志给所有人, 造成已提交的
Cᵥ
丢失.
作者给出了这个问题的修正方法, 修正步骤很简单, 跟Raft的commit条件如出一辙:
新leader必须提交一条自己的term的日志, 才允许接变更日志
:
The solution I’m proposing is exactly like the dissertation describes except that a leader may not append a new configuration entry until it has committed an entry from its current term.
在上面这个例子中, 对应的就是L₁必须提交一条NoOp的日志: 以便L₂能发现自己的日志是旧的, 阻止L₂选为leader.






