2017年是移动直播的一个分水岭,花椒直播也从去年的洗牌中脱颖而出,杀出重围的关键不仅仅是直播平台上优质的内容,流程的视频播放体验更是吸引用户们的关键。今天小主就为大家奉献上一篇来自花椒直播团队总结的一篇视频直播质量监控体系的经验分享。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
影响视频质量的因素是多样和复杂的。从主播端到看播端整条路径上,任何一环出问题,比如码率降低,分辨率降低,帧率降低,光源使用不当,滤镜使用不当,传输层丢包,播放端网络质量差,播放端解码能力弱等等,都可能导致视频质量下降。
检测视频质量一直以来有两种方式,分别是客观评价和主观评价。
无论是哪一种方式,在大规模全民互动直播场景下,都显得捉襟见肘。这里我们建立了一个通过主观评价方式对一个相对小的视频集合进行分类标注,然后用机器学习的办法提取出模型,再扩展到对所有视频对象进行自动评价打分的方案,相应的建立了一个采样和分析的服务器集群,对花椒全网的频道进行自动画质监控。

视频本质上是由一帧一帧的连续图片组成的,所以通过提取场景关键帧的方式来代表某个时间段内的视频是一种普适的视频分析方法。我们也采用定期的方式(2~4s)从视频流里获取关键帧截图。然后将其交给分析层做进一步处理。
预先通过机器学习的办法,得到一个训练过的模型,针对每一个输入的图片,套用模型分析处理,可以得到分类结果,这就是我们的自动评分。将评分结果交给业务处理层做进一步处理。
由于分析层给出的只是某一小段时间的静止的场景判断结果,而实际情况下,视频又是一个由连续和不断变化的场景组成的集合,所以只靠一两次的识别结果进行判断,会有较大的误差。通过在业务层为每个视频流增加一个历次结果cache滑动窗口,缓存最近一段时间的结果,然后每收到一个新的分析结果,就按照预设算法,重新计算一次整个视频的质量判别结果,得到一个新的基于本视频流的评分。从而平滑了机器学习算法的误差,得到一个更为稳定的输出。
通过接口API的方式,将视频的判别结果提供给第三方,由其进行业务相关的扩展使用。
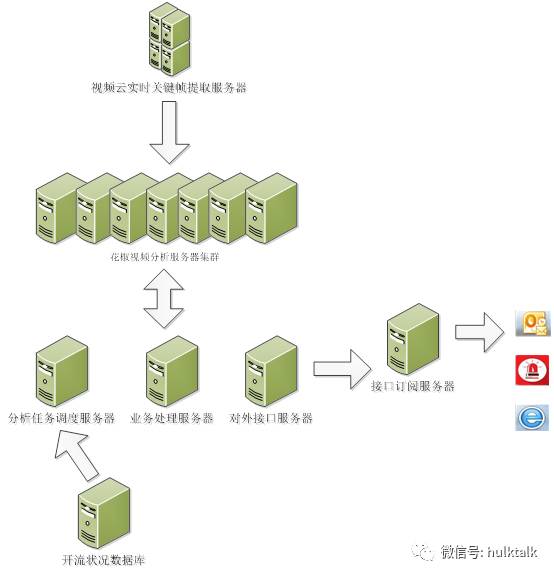
整个系统架构依托于花椒已有的视频实时截图服务以及花椒业务接口服务
视频分析系统首先从花椒业务接口获取到线上直播视频基本信息;
根据这些信息做一定的负载均衡,把监控任务分发到制定的worker机;
worker机会按照一定间隔从截图服务中获取截图,做一定预处理生成向量;
由训练好的模型进行预测分析;
分析结果入库后会提供web展示页、接口订阅服务、已经通过报警app、邮件等的统计和报警服务;
当前视频云默认是每2s更新一张直播间截图,高峰期平均每秒需要处理的流的量级为数万(流的路数/2)。正常情况每张图的大小在100kB~200kB之间,以平均150kB计算。在带宽需求上,约有几十G。如果单台机器使用千兆网卡,则至少需要几十台机器。线上机器单核提取一张截图的维度信息时间大概是30ms左右,然后进行分类所需时间大概是20ms左右,平均下来,单核1s时间可以处理的图片数量大致是20张。目前采用机器是32核,即理论上1s时间可以处理640路流,从计算实时性上来分析,也需要几十台机器。
系统结构说明:这里使用了N台视频分析服务器,其工作就是从视频云请求关键帧,分析提取向量信息,归类得到质量好坏结果,然后存入共享的数据库中。另外使用了其中1台服务器作任务调度,并兼做分析结果存储。另外为了节省设备,目前的中间业务服务器,对外接口服务器是和一台视频服务器公用同一物理机。以15s和1min作为cache窗口,每15s对live/latest/school三个大项做一次整体评价,每1min对所有流做一次整体评价,然后由对外接口层生成一个评价结果的html网页以及一个json格式的文件。
当前采用的svm是浅层学习方案,特点是只需要较少的样本就可以生成有一定效果的模型,但是还存在一些场景的不适应。目前基于神经网络的深度学习已经十分成熟,其外部框架如caffe,tensorflow, thera都逐渐流行起来,下一步可以结合这些框架,并同运行客服协调对视频流进行标注,增加机器学习的样本,进一步的优化识别结果。
客观评价
客观评价指的是不需要人为评价的方法,即将原视频与处理后的视频进行对比。可以进行象素级别的对比,也可以对某些特性进行提取和对比。客观评价指标常见的有PSNR(峰值信噪比),MSE(均值方差),SSIM(结构相似度)等。
主观评价
主观评价是指由评测人员参与,对视频质量进行评估,相应的有一些主观评价工具,供评测者对待测视频进行打分。
此外对视频的清晰度也有一些客观评价的指标,如各类梯度函数,Brenner,Tenengrad等等。其原理是通过判断图像的象素点的灰度/RGB值等的变化程度判断图像是否清晰。
一种浅层机器学习分类方法,除了做线性分类,还可以结合核函数,将低纬度向量映射到更高维度实现线性分类的目的。在目前的系统中,采用了SVM来做图片质量分类。这种方式需要提取图片的清晰度特征,这里我们提取的是梯度特征。
通过卷积,亚采样,池化(pooling)等一层又一层的叠加操作,将图片提取出更多信息,并通过损失函数(loss)来校正处理分类参数,最后得到基于学习样本最佳的分类参数作为输出模型。理论上只要学习样本越多,最后的精度会越高。



