语义分割一直是计算机视觉中十分重要的领域,随着深度学习的流行,语义分割任务也得到了大量的进步。本文首先阐释何为语义分割,然后再从论文出发概述多种解决方案。本文由浅层模型到深度模型,简要介绍了语义分割各种技术,虽然本文并没有深入讲解语义分割的具体实现,但本文简要地概述了每一篇重要论文的精要和亮点,希望能给读者一些指南。
什么是语义分割?
语义分割指像素级地识别图像,即标注出图像中每个像素所属的对象类别。如下图:

左:输入图像,右:该图像的语义分割
除了识别车和骑车的人,我们还需要描绘出每个物体的边界。因此,与图像分类不同,语义分割需要根据模型进行密集的像素级分类。
VOC2012 和 MSCOCO 是语义分割领域最重要的数据集。
有哪些不同的解决方案?
在深度学习应用到计算机视觉领域之前,人们使用 TextonForest 和 随机森林分类器进行语义分割。卷积神经网络(CNN)不仅对图像识别有所帮助,也对语义分割领域的发展起到巨大的促进作用。
语义分割任务最初流行的深度学习方法是图像块分类(patch classification),即利用像素周围的图像块对每一个像素进行独立的分类。使用图像块分类的主要原因是分类网络通常是全连接层(full connected layer),且要求固定尺寸的图像。
2014 年,加州大学伯克利分校的 Long 等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN 从而得到普及。使用这种方法可生成任意大小的图像分割图,且该方法比图像块分类法要快上许多。之后,语义分割领域几乎所有先进方法都采用了该模型。
除了全连接层,使用卷积神经网络进行语义分割存在的另一个大问题是池化层。池化层不仅扩大感受野、聚合语境从而造成了位置信息的丢失。但是,语义分割要求类别图完全贴合,因此需要保留位置信息。本文将介绍两种不同结构来解决该问题。
第一个是编码器-解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。U-Net 是这种方法中最常用的结构。
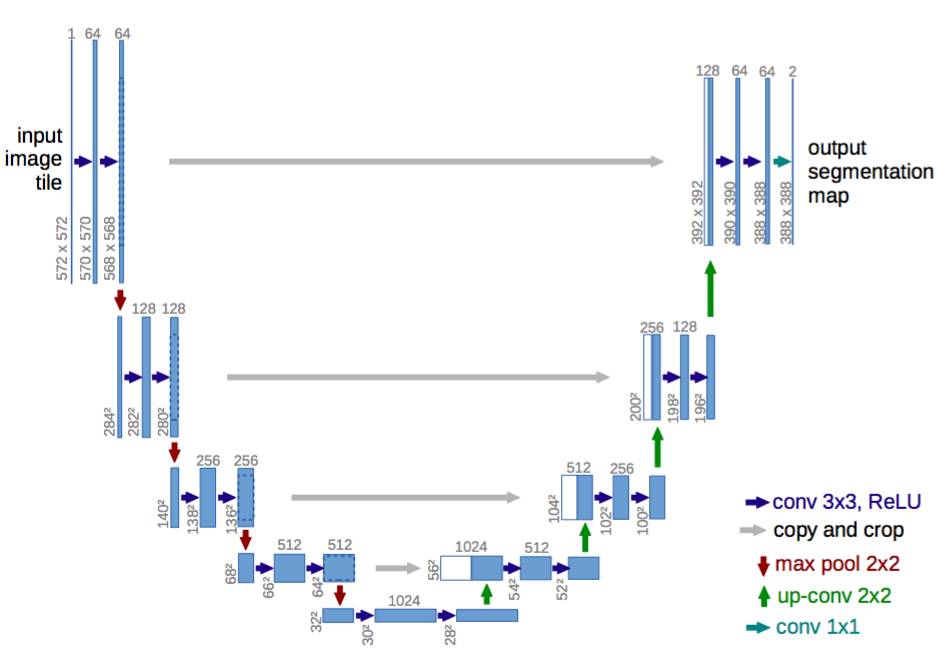
U-Net:一种编码器-解码器结构
第二种方法使用空洞/带孔卷积(dilated/atrous convolutions)结构,来去除池化层。
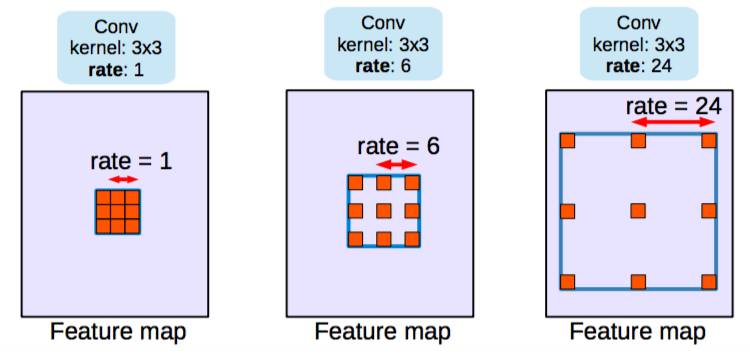
Dilated/atrous 卷积,rate=1 是典型的卷积结构
条件随机场(CRF)预处理通常用于改善分割效果。CRF 是一种基于底层图像像素强度进行「平滑」分割的图模型。它的工作原理是灰度相近的像素易被标注为同一类别。CRF 可令分值提高 1-2%。
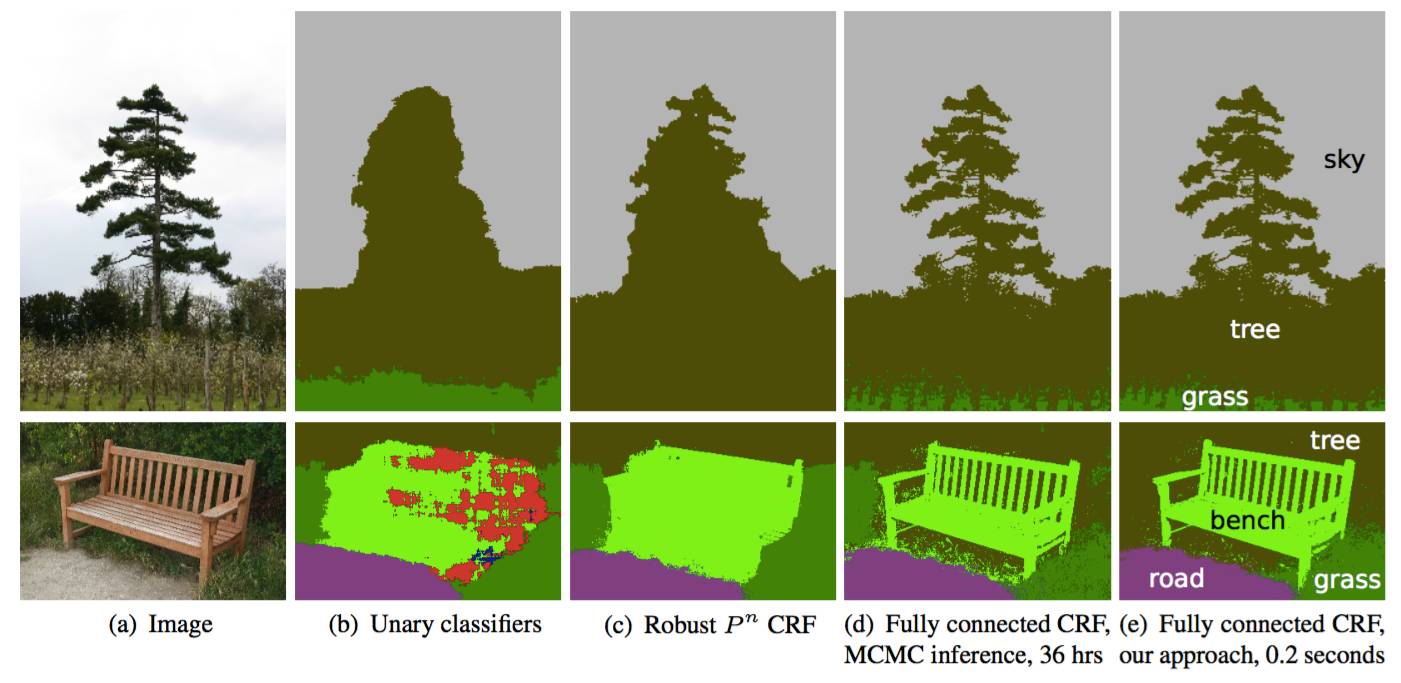
CRF 示意图。(b)一元分类器作为 CRF 的分割输入。(c、d、e)是 CRF 的变体,其中(e)是广泛使用的一种 CRF
下面,我将总结几篇论文,介绍分割结构从 FCN 以来的发展变化。所有这些架构都使用 VOC2012 评估服务器进行基准测试。
论文概述
下列论文按照时间顺序进行介绍:
-
FCN
-
SegNet
-
Dilated Convolutions
-
DeepLab (v1 & v2)
-
RefineNet
-
PSPNet
-
Large Kernel Matters
-
DeepLab v3
我列出了每篇论文的主要贡献,并稍加解释。同时我还展示了这些论文在 VOC2012 测试数据集上的基准测试分数(IOU 均值)。
FCN
主要贡献:
相关解释:
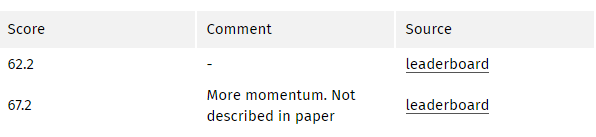
本论文的关键点是分类网络中的全连接层可视为使用卷积核覆盖整个输入区域的卷积操作。这相当于根据重叠的输入图像块评估原始分类网络,但由于计算过程由图像块的重叠部分共同分担,这种方法比之前更加高效。尽管该结论并非独一无二,但它显著提高了 VOC2012 数据集上模型的最佳效果。
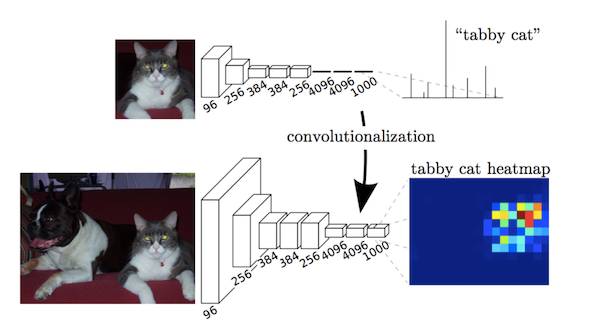
全连接层作为卷积操作
将全连接层在 VGG 等 Imagenet 预训练网络中进行卷积操作后,由于 CNN 中的池化操作,特征图仍旧需要上采样。解卷积层不使用简单的双线性插值,而是学习所进行的插值。解卷积层又被称为上卷积(upconvolution)、完全卷积、转置卷积或微步卷积(fractionally-strided convolution)。
但是,由于池化过程造成信息丢失,上采样(即使带有解卷积层)生成的分割图较为粗糙。因此我们可以从高分辨率的特征图中引入跳跃连接(shortcut/skip connection)来改善上采样的粗糙程度。
VOC2012 基准测试分数:
个人评价:
这是一项重要的贡献,但是当前的技术水平又有了很大发展。
SegNet
主要贡献:
将最大池化索引(Maxpooling indices)转移到解码器,从而改善分割分辨率。
相关解释:
在 FCN 网络中,尽管使用了解卷积层和一些跳跃连接,但输出的分割图仍然比较粗糙。因此,更多的跳跃连接被引入 FCN 网络。但是,SegNet 没有复制 FCN 中的编码器特征,而是复制了最大池化索引。这使得 SegNet 比 FCN 更节省内存。
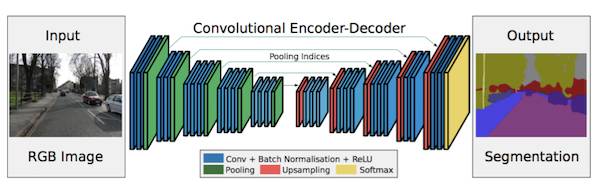
Segnet 结构
VOC2012 基准测试分数:

个人评价:
空洞卷积(Dilated Convolutions)
主要贡献:
相关解释:
池化使感受野增大,因此对分类网络有所帮助。但池化会造成分辨率下降,不是语义分割的最佳方法。因此,论文作者使用空洞卷积层(dilated convolution layer),其工作原理如图:
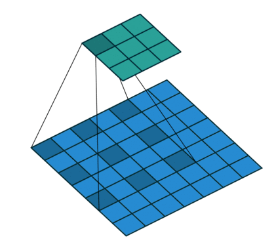
空洞/带孔卷积
空洞卷积层(DeepLab 将其称为带孔卷积)可使感受野呈指数级增长,而空间维度不至于下降。
从预训练好的分类网络(此处指 VGG)中移除最后两个池化层,之后的卷积层都使用空洞卷积。尤其是,pool-3 和 pool-4 之间的卷积是空洞卷积 2,pool-4 后面的卷积是空洞卷积 4。使用这个模块(论文中称为前端模块 frontend module)之后,无需增加参数即可实现稠密预测。另一个模块(论文中称为背景模块 context module)将使用前端模块的输出作为输入进行单独训练。该模块是多个不同扩张程度的空洞卷积级联而成,因此该模块可聚合多尺度背景,并改善前端模块获取的预测结果。
VOC2012 基准测试分数:
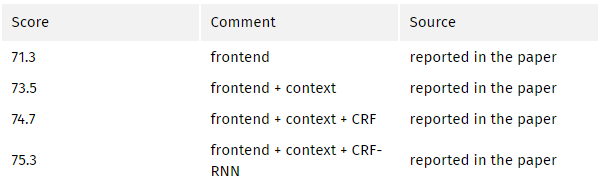
个人评价:









