半导体制造(有文章也称为“制程”)的工艺节点,可以看作是摩尔定律下的集成电路芯片集成度大小的一个指标。在读半导体文章时,我们常常可以看到这样一组数字:180nm、90nm、65nm、45nm、28nm、14nm、7nm(nm纳米,1微米=1000纳米)等。这些数字就是表示半导体工艺的“技术节点(technology node)”,也称作“工艺节点”。这些节点对半导体制造有哪些意义,是什么因素形成了这些节点,又是哪些因素推动了这些节点的不断进步呢?我们来做个梳理。
1958年,美国德州仪器公司的工程师杰克•基尔比制成了世界上第一片集成电路,1962年,德州仪器公司建成世界上第一条商业化集成电路生产线。此后,在市场需求的驱动下,集成电路发展成为一个庞大的产业,从小规模集成电路(SSI)到中规模集成电路(MSI)、再到大规模集成电路(LSI),一直到现在的超大规模集成电路(VLSI)。集成度被看作是描述集成电路工艺先进程度的一个重要指标,通常用晶体管数目来表示集成度高低,一个芯片里含有的晶体管数目越多,芯片的功能也就越强。因此,集成电路的规模反映了集成电路的先进程度。
集成度的提高,不仅意味着单个晶体管的尺寸缩小了,同时也意味着采用了更加先进的制造工艺,因为晶体管尺寸与制造工艺之间有着密切的联系。可以说,集成电路技术的发展过程,就是把晶体管尺寸做得越来越小的过程。九十年代的大规模集成电路普遍采用的是微米级工艺,笔者在上世纪90年代初做设计时就是采用5微米和3微米标准单元库,这也是那个年代的主流工艺(晶圆尺寸是3英寸和4英寸)。二十多年过去了,现在已经发展到纳米级工艺了,中芯国际去年实现量产的28纳米工艺,比起3微米工艺,尺寸缩小了100多倍。
这些工艺演进的背后,是更多金钱的投入。因为更小的尺寸意味着对设计和制造设备以及芯片材料等都有更为苛刻的要求,为了克服技术门槛,芯片企业每年需要投入数亿、数十亿美元的研发经费,不知有多少世界一流的科学家和工程师都参与了这一耗资巨大的芯片微缩化工程。
那么5微米、3微米、以及90纳米、28纳米等等这些“节点”是怎样形成的呢?可以说这是描述摩尔定律进程的一个指标。摩尔定律说,半导体芯片每一年半(后来改为两年),其集成度翻一番,并伴随着性能的增长和成本的下降。怎样描述这个集成度呢?这就有了工艺“节点”的说法。即工艺节点数值越小,表征芯片的集成度就越高。这些数值也被《国际半导体技术蓝图(ITRS)》用来划分半导体工艺的阶段(也称工艺代),或描述芯片的先进性。
这里有必要解释这些数值表示的是什么尺寸。例如28nm工艺,这里的28nm是指晶体管栅极的最小线宽(栅宽)。实际设计中除了栅极,其他的设计尺寸一般都大于工艺节点的尺寸,例如晶体管之间的金属连线宽度、有源区宽度等。
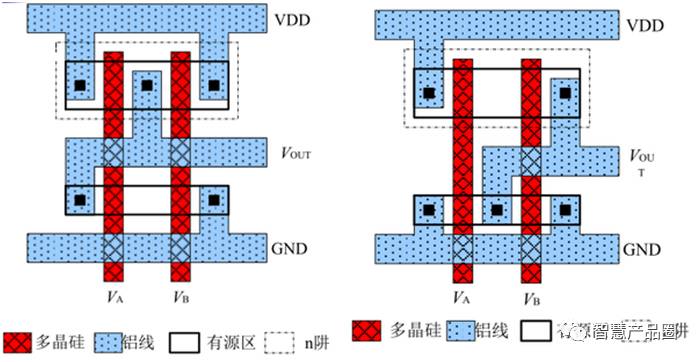
▲ 图一 与非门、或门的版图
图一是个例子。在这个与非门和或非门的版图里,白的是衬底层,红的是多晶硅层,蓝的是金属层。这其中只有红的多晶硅栅极的最小线宽是可以达到28nm的,其他一切尺寸都是要大于28nm。具体各层线宽的最小值需要看该工艺的设计规则(Design Rull)。
为什么用栅极线宽而不是其他的线宽来表征工艺节点,这是因为栅极宽度一般是整个设计中最重要的参数。在CMOS电路中,MOS晶体管最主要的功能就是通过栅极控制源漏之间的电流。这个电流受很多因素影响,例如晶体管迁移率、绝缘层电容,还有各种效应等,这些都与半导体工艺有关,工艺定了设计很难改变。一般情况下唯一可以设计的参数就是沟道宽长比,沟道宽长比就是晶体管栅极的长宽比(长沟器件可以直接近似,短沟器件要加修正项)。也就是说在电压一样的情况下,栅极越宽,沟道就越长,源漏电流就越小。
所以在设计中,沟道越短,意味着晶体管的尺寸越小,单位面积可以存放的晶体管数量就越多,芯片集成度就越高;换一种说法是设计出来的芯片面积就越小,芯片的价格就越便宜。当然这是在只考虑生产成本,不考虑NRE费用的前提下。
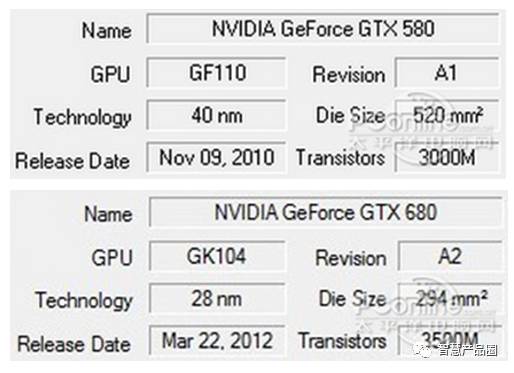
▲ 图二 NVIDIA GTX580(40nm工艺) 与 GTX680(28nm工艺)的对比
从图二,我们看到Geforce GTX 680虽然晶体管数目比GTX 580多,但是芯片面积却只有后者的一半多一点,这就是从40nm制程工艺进化到28nm的好处。
有一个例外是DRAM 电路,在DRAM存储单元中,该特征尺寸不是指栅宽,而是指金属连线所允许的最小间距的一半。概括来说,它描述了该工艺代下加工尺寸的精确度。它并非一定指半导体器件中某一具体结构的特征尺寸,而是一类可以反映出加工精度的尺寸的平均值。它最直观地反映出:集成电路通过微电子制造工艺加工生产能达到更大的集成密度。
工艺节点的进步也带来了理论上功耗的降低。因为晶体管缩小可以降低单个晶体管的功耗,因为按照等比例缩小的规则,栅压(Vds)会减小,栅压减小会降低整体芯片的供电电压,进而降低功耗。
但是从物理原理上说,随着工艺节点的进步芯片的单位面积功耗并不跟着降低。因此这成为了晶体管缩小的一个严重障碍,因为理论上的计算是理想情况,实际上,芯片的功耗会随着集成度的提高而提高。在2000年左右的时候,人们已经预测,根据摩尔定律的发展(晶体管)继续缩小下去,假如没有什么技术进步的话,10多年后,其功耗密度可以达到火箭发动机的水平,这样的芯片是不可能正常工作的。即使达不到这个水平,温度太高也会影响晶体管的性能。
事实上,业界现在也没有找到真正彻底解决晶体管功耗问题的方案,现在的做法是一方面降低电压(功耗与电压的平方成正比),一方面不再追求时钟频率。因此在2005年以后,CPU频率不再增长,性能的提升主要依靠多核架构。这个被称作“功耗墙”。“功耗墙”的存在使得晶体管的缩小不能再任意下去。
在微米时代,工艺节点可以看作是与晶体管的栅宽(沟道长度)划等号。工艺节点的数字越小,沟道长度也越小,晶体管的尺寸也越小。但是在22nm节点之后,情况有了变化。晶体管的实际尺寸,或者说沟道的实际长度,不一定与这个节点相等。比方说,英特尔的14nm工艺的晶体管,沟道长度其实是20nm。这是为什么呢?
这要从硅原子谈起。硅原子直径是纳米级的,硅原子半径为110皮米,也就是0.11纳米,直径0.22nm。如果把晶体管的沟道缩小到10nm,就意味着大约是45个硅原子排在一起的长度(不考虑原子间距的情况下),这时在经典物理理论下的晶体管的电流模型已不再适用。用经典的电流理论计算电子的传输,电子在分布确定之后,仍然被当作一个粒子来对待,而不考虑它的量子效应。因为尺寸大不需要。但是越小就不行了,就需要考虑它的各种复杂的物理效应。
其次,一种叫做“短沟道效应”的现象也会对晶体管的性能带来影响,“短沟道效应”带来的直接损害是栅极电压不能有效关闭晶体管,导致漏电流产生,浪费大量功耗。这部分漏电不能小看,“短沟道效应”引起的这部分漏电流导致的能耗,可以占到总能耗的一半。
另一个制造工艺的极限是由制造设备带来的,具体来说就是光刻机的分辨率制约。光刻机的分辨率与光源有关系,光源的聚焦性能越好,分辨率越高,能够刻出的线条就越细。 在250nm工艺以前的光刻工艺使用的是汞灯光源,为了提高分辨率,从180nm开始采用波长为248nm的KrF激光作为曝光光源,130nm和90nm工艺采用波长为193nm的ArF激光光源,从65nm工艺开始采用波长更短的激光光源。
我们知道,谈起光的使用都有一个本质的问题,就是衍射,光刻机也不例外。任何一台光刻机所能刻制的最小尺寸,基本上与它所用的光源的波长成正比。波长越小,尺寸也就越小。目前的主流生产工艺采用的是荷兰艾斯摩尔生产的步进式光刻机,所使用的光源是193nm的氟化氩(ArF),被用于最精细的尺寸的光刻步骤。与目前已量产的最小晶体管尺寸20nm (14nm 工艺节点)相比,已经有了10倍以上的差距。
怎么克服光的衍射效应?业界十多年来投入了巨资,先后开发了各种先进光刻技术,诸如浸入式光刻(把光程放在某种液体里,光的折射率更高,而最小尺寸反比于折射率)、相位掩模(通过180度反向的方式来让产生的衍射互相抵消,提高精确度),等等,这些技术一直撑到了60nm以来的所有工艺节点的进步。为何不用更小波长的光源呢?答案是工艺上难度很大。高端光刻机的光源,一直是世界级的工业难题。
以上介绍的主流光刻技术是深紫外曝光技术(DUV)。业界普遍认为,到了7nm工艺节点就是它的极限。下一代技术是被称为极紫外(EUV)的光刻技术,其光源降到了13nm。这个技术也带来了其他的一系列难题,例如没有合适的介质可以用来折射光,构成必要的光路,因此这个技术里面的光学设计全部是反射。在如此高的精度下,设计如此复杂的反射光路,难度之大可想而知。
最后一点,随着工艺节点的特征尺寸越来越小,栅极和有源区(D/S)之间的绝缘层也会越来越薄,会导致很容易被电压击穿。所以沟道越短越好是针对数字电路而言,对模拟电路来说目前0.13um、0.15um、0.18um工艺制程是足够用了。










