*视频由“IT大咖说”提供,时长约34分钟,请在WiFi环境下观看。更多视频可在大咖说平台观看*
客户流失率是考量是业务成绩的一个非常关键的指标。根据历史数据建立模型,使用机器学习的方法预测客户流失概率,可以找出用户流失的因素,从而完善产品,减少客户流失概率。
那么,对于这样的一个问题,我们需要做哪些数据分析?特征又是如何提取?如何选择合适的机器学习模型?如何调整模型的参数?同时对于类似的这些问题,又有什么常见的套路呢?本文将基于客户流失率预测的赛题,以及个人的实战经验,对上述的问题一一做出解答。
接下来,将从以下几个方面对客户流失率预测这个问题进行阐述:首先,对现有的赛题和数据进行了一个简要的分析;然后是特征工程的介绍,着重介绍了针对现有的数据如何有效地提取特征;第三部分是模型及其原理的介绍,介绍了GBDT的原理,以及XGBoost的使用以及调参方法;第四部分介绍了常见的模型融合的方法,包括Bagging和Stacking,以及在本赛题中融合的架构;最后一部分是经验的总结,结合个人多次的参加大数据竞赛的实战经验,分享了相关经验。
问题分析
拿到一个机器学习问题,我们首先需要明白我们要解决一个什么问题。在云海竞赛平台的官方网站上给的赛题描述是非常模糊的一段话(深入了解...找到...),看完这个可能还是不明白需要干什么。没关系,继续看数据,数据如下图所示。数据上面有个label,是1表示客户最后流失了,是0的话表示最后客户没有流失。看到这里,于是明白了,这是一个分类的预测问题。

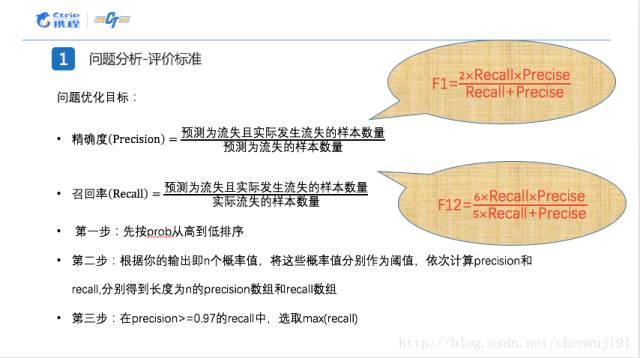
接着需要关注赛题的评价标准,对于任何比赛,评价标准一直是一个很重要的东西。评价标准即损失函数,直接决定了我们后边分类器的学习目标。对于一个分类的问题而言,最终的评价标准是准确率和召回率的一个组合,常见的就是F1值或者加权的F1值。对于这个比赛,评价标准是要求在达到97%的准确率的情况下,可以使得最后的召回率尽可能的高。这个也很好理解,和携程的业务关系密不可分。
对于客户流失概率而言,我“宁可错杀三千,也不可放过一个”。就是说,我是要尽可能地采取相关的措施,一定不能允许有客户流失的情况发生。同时,因为挽救可能流失的客户需要成本,所以我也要求尽可能高的召回率。
接下来关注的是数据的具体情况。数据的特征除了id和label以外大致可以分为三类,一种是订单本身的特征,比如订单的预定日期以及订单的入住日期等;另外一种是和用户相关的特征;还有一类特征是和酒店相关的特征,比如酒店的点评人数、酒店的星级偏好等。
同时,我们会注意到官方对于赛题数据,曾经做过这样一个解答:如果一个用户浏览了A、B、C、D四个酒店,最后选择了第四个酒店的话,那么会产生四条记录,并且这四条记录的label都会被标记为1。
从这一点我们可以看出,我们在做本地测试集划分的时候需要基于用户进行划分,也就是要保证划分前后的数据是满足独立同分布的。但是很遗憾,为了保护用户的隐私,并没有提供User ID的数据。因此,我们采取了一种近似的方法,就是看所有和用户相关的属性,如果这些属性都是相同的,那么我们就认为这是一个用户的行为。
我们基于上述原则,将原始训练数据集的三分之二划分为训练数据集,三分之一划分为本地测试集。因为这个场景下的时间序列特性不是很明显,所以没有按时间线对数据进行划分。在特征选择和调参的过程中我们主要使用线下的数据集进行的。
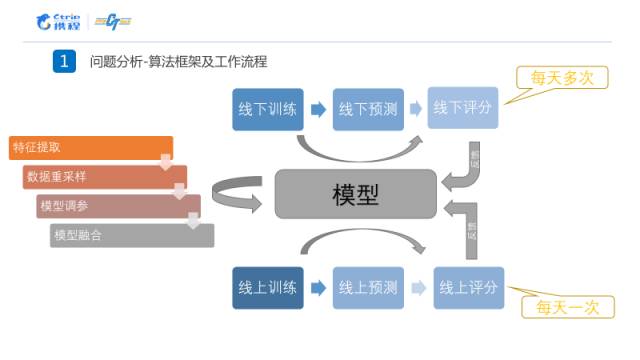
我们整个的工作流程如下图所示。线上的测评每天只有一次机会,我们在线下每天进行多次的特征选择和参数调整。整个的流程包括特征的抽取、数据集重采样、特征选择和模型的融合。
特征工程
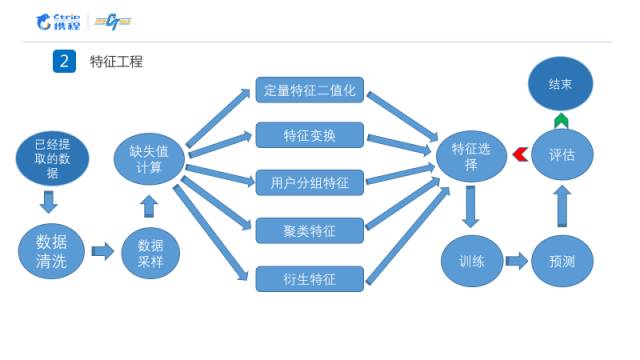
整个特征工程的总体流程如下所示,相关的数据已经由比赛的主办方提取完成。我们在本次比赛中主要进行了数据采样一直到模型评估中间的工作。在生成了所有特征之后,我们会进行特征选择,我们通过本地的测试集对特征进行评估,保留有效的特征,去除无用的特征。
首先要进行缺失值的填充工作,从下图的数据中我们看到,有大量的缺失值分布在各个特征中。一般情况下填充缺失值的方法是使用均值或者0进行填充。我们在这里用0填充。但是有些属性,比如用户年订单量这样的特征,用0填充的话会产生混淆,填充之后无法判断是本身是0还是后来填充的0。所以我们对于这类特征,在填充0的基础上,构造一列新的特征,标记原始的数据中的0是否是我们填充得到的。

然后是特征的二值化以及特征的多项式变换,二值化主要使用了one-hot。前者将一些用数字枚举的特征变换成多维的0-1编码,后者根据现有特征演化出相关的特征。这一类的特征可以直接通过调用Sklearn的相关函数实现。
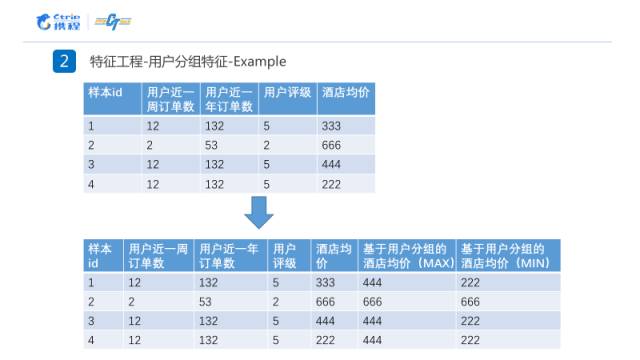
在第一部分的数据分析中,提到了这个数据跟用户是息息相关的。所以在这里在对数据进行用户分组之后,需要提出每组的最大值和最小值作为特征,如下图例子所示。
另外还有聚类特征,整个数据集中重要的两个部分,一个是用户相关的数据,一个是酒店相关的数据。因此,我们把这两类主体进行一个聚类,把类的标签号作为一个新的特征。对用户和酒店我们分别使用以下的特征进行聚类。
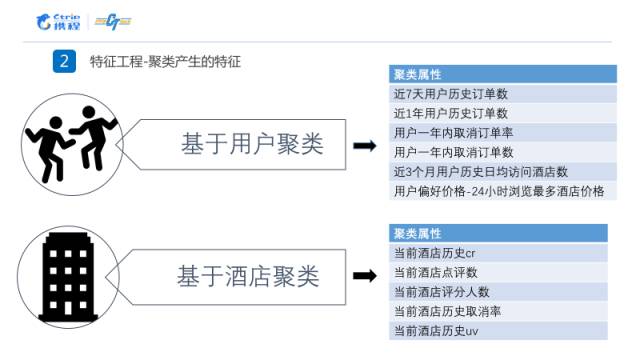
最后还有一类特征是根据现有特征衍生出来的一些特征,比如访问日期和实际入住日期之间的差值,还有访问日期和入住日期是不是周末等特征。在机器学习中,是否为周末这个特征往往是非常重要的。
原文链接:
https://mp.weixin.qq.com/s/EwQOpbOaItyvTCKRtDxlVA








