
10.1 典型的 O2O 推荐场景
美团移动端推荐展位是一个典型的 O2O 推荐场景,包括首页猜你喜欢和商家详情页附近团购、团购详情页看了又看等多个展位。首页猜你喜欢展位图如图 10-1 所示。
图 10-1 美团移动端——猜你喜欢展位图
猜你喜欢展位是美团移动端首页的推荐展位,也是美团移动端流量最大的推荐展位。推荐内容包括团购单、酒店商家、外卖商家、电影院等,是一个混合形态的推荐。
详情页推荐展位包括商家详情页的附近团购和团购详情页的相关团购等。附近团购主要是附近商家的推荐(见图 10-2),相关团购主要是团购的推荐(见图 10-3),推荐形态相比猜你喜欢更单一一些。
猜你喜欢展位中,用户意图并不是太明确,推荐结果包括美食团购、外卖、酒店、旅游等多种类型的结果。详情页中,用户已经有了比较明确的意图,比较倾向于推相关品类的结果或者关联品类的结果。
10.2 O2O 推荐场景特点
以美团移动端推荐为例,O2O 推荐场景与其他推荐的区别具体包括如下三点:
-
地理位置因素:
特别是对于美食、酒店、外卖等业务,用户倾向于使用附近商家的服务。
-
用户历史行为:
新闻或者资讯推荐,用户看一次了解这些信息之后,就不会再去读第二遍。与新闻推荐不同,一家味道好的店,用户可能会反复光顾。从具体的数据来看,大量用户会产生重复点击和重复购买的行为。
-
实时推荐:
一是地理位置,推荐需要考虑用户的实时位置。二是 O2O 场景的即时消费性,例如美食、外卖、电影等都是高频消费,用户从考虑到最终下单之间间隔时间非常短,所以推荐必须要实时,并且根据用户的实时反馈调整推荐的内容。
下面我们就这三个特点进行展开阐述:
10.2.1 O2O 场景的地理位置因素
地理位置因素分为若干个层次:KD-Tree 实时索引、GeoHash 索引、热门商圈索引、城市维度索引等。我们一般通过建立基于地理位置的索引来检索周边的商家和服务。在推荐时根据用户的实时地理位置实时地查询附近的商家和服务。对于与地理位置不太相关的内容,可以单独以城市维度或者商圈维度来建立索引,例如景点等。
常用的地理位置索引可以是 KD-Tree 索引,它能达到很好的实时检索性能。
下面分别讲解不同层次索引的异同点和优缺点。
-
KD-Tree 索引:
以当前位置为圆心,可以快速检索出指定距离范围内的商家和服务。
优点是精度最高。
-
GeoHash 索引:
对区域进行正方形和六边形的划分,快速找出 GeoHash 范围内的商家和服务。
缺点是精度不太高,如果当前实时位置在区域边沿,这个位置可能与另一个邻接 GeoHash 内商家和服务的距离会更近。
-
热门商圈索引:
商圈索引检索的粒度相对粗一些,但是比较符合人生活中的实际经验,比如北京的五道口商圈、国贸商圈等。将商家和服务按照商圈的维度组织起来,可以使得我们能够给用户推荐感兴趣的同商圈的内容。
-
城市维度索引:
它可以用来索引一些与地理位置关系不大的内容,例如景点等。另外,用户没有地理位置信息时,只能通过城市维度索引去检索出相关内容。
10.2.2 O2O 场景的用户历史行为
因为 O2O 场景用户有重复点击和购买的情况,所以我们需要用到用户的历史行为信息,包括用户的点击、下单、购买、支付、收藏、退款、评价等行为。在实际使用过程中会根据用户历史行为距离当前的时间进行相应的时间衰减,目的是加强最近行为的权重,减少久远行为的权重。
由于美团的用户量巨大,将用户所有行为全部存储下来供线上使用不太现实。实际应用会结合用户的活跃度和行为的类别来做相应的截断。例如,较活跃的用户会保留时间较短的行为,不太活跃的用户保留时间更长一些的行为。常用的方法有两个:
另外,可以结合行为的类别区分保留的数量,例如高频的行为可以保留时间短一些,低频的行为可以保留时间长一些。用户强意图的行为,例如收藏、下单等行为可以保留时间长一些,点击行为可以保留短一些。
截断时会综合考虑线上存储空间的占用和实际效果优化需求来折中考虑,并选择一个性价比较高的方案。
10.2.3 O2O 场景的实时推荐
由于 O2O 场景的地理位置重要性和消费的及时性,我们需要做实时的推荐。相比非实时的推荐,实时推荐在数据、系统和算法方面的要求会更高。
实时推荐需要用到最新的实时数据,美团利用了流数据处理,实时将从线上日志中解析得到用户行为用于线上,线上行为反馈的延时在
秒级别
。也就是说,用户在美团上行为操作,1 秒以内推荐系统就可以捕捉到,并且及时做出相应的推荐调整。
线上使用的推荐的实时性主要有召回的实时性、特征的实时性、排序模型的实时性(后面会详细介绍)。
-
召回的实时性:
用户有过行为的内容会实时反馈到推荐系统中,与之相似的内容都会加入到新的推荐中去。
-
特征的实时性:
用户对相关商家和服务的行为,除了用于召回,也会用于更新用户排序特征。排序特征中有一些关于相关行为的统计量,会在线实时更新,直接影响排序的得分。
-
排序模型的实时性:
反馈可以形成正样本 / 负样本,用于模型未来的批量更新和实时更新。
下面将以猜你喜欢为例,详细介绍推荐系统及推荐算法。
10.3 美团推荐实践——推荐框架
从框架的角度看,推荐系统基本可以分为
数据层、候选集触发层、候选集融合规则过滤层
和
重排序层
,如图 10-4 所示。
数据层
包括数据生产和数据存储,主要是利用各种数据处理工具对原始日志进行清洗并处理成格式化的数据,将数据落地到不同类型的存储系统中,供下游的算法和模型使用。
候选集触发层
主要是从用户的历史行为、实时行为、地理位置等角度利用各种召回策略产生推荐的候选集。候选集融合和过滤层有两个功能:
排序层
主要是利用机器学习的模型对召回层筛选出来的候选集进行重排序。
候选集召回和重排序是在优化推荐的效果时最频繁迭代的两个环节,因此需要支持 A/B 测试
。为了支持高效率的迭代,我们对候选集召回和重排序两层进行了解耦,这两层的结果是正交的,因此可以分别进行对比试验,不会相互影响。同时在每一层的内部,我们会根据用户将流量划分为多份,支持多个策略同时在线对比。
数据乃算法、模型之本。美团作为一个交易平台,它拥有快速增长的用户量,产生了海量丰富的用户行为数据。当然,不同类型用户行为数据的价值和对用户意图的反映强弱也不太一样。
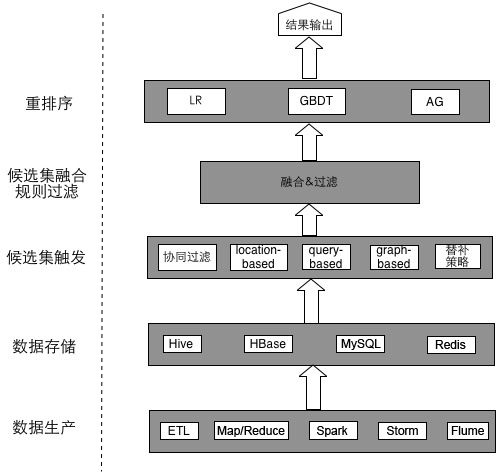
图 10-4 推荐系统框架图
用户主动行为数据记录了用户在美团平台上不同环节的各种行为。一方面,这些行为用于候选集触发算法(下一部分介绍)中的离线计算(主要是浏览、下单);另一方面,这些行为代表的意图强弱是不同的,因此在训练重排序模型时可以针对不同的行为设定不同的回归目标值,以更细地刻画用户的行为强弱程度。
此外,用户对 Item 的这些行为还可以作为重排序模型的交叉特征,用于模型的离线训练和在线预测。
负反馈数据反映了当前的结果可能在某些方面不能满足用户的需求,因此在后续的候选集触发过程中需要考虑对特定的因素进行过滤或者降权,降低负面因素再次出现的概率,提高用户体验。
同时,在重排序的模型训练中,负反馈数据可以作为不可多得的负例参与模型训练,这些负例要比那些展示后未点击、未下单的样本显著得多。用户画像是刻画用户属性的基础数据,其中有些是直接获取的原始数据,有些是经过挖掘的二次加工数据。
这些属性一方面可以用于
候选集触发过程中对 Deal 进行加权或降权
,另一方面可以作为
重排序模型中的用户维度特征
。通过对 UGC 数据的挖掘,我们可以提取出一些关键词,然后使用这些关键词给 Deal 打标签,用于 Deal 的个性化展示。
上面简单地介绍了推荐系统框架中的数据层。推荐系统框架中数据层之上的召回和排序层是非常重要的两部分,我们会在后面两节内容中详细介绍。
10.4 美团推荐实践——推荐召回
个性化推荐的成功应用需要两个条件。
第一是信息过载
,因为用户如果可以很容易地从所有物品中找到喜欢的物品,就不需要个性化推荐了。
第二是用户大部分时候没有特别明确的需求
,因为用户如果有明确的需求,可以直接通过搜索引擎找到感兴趣的物品。
上文中我们提到了数据的重要性,但是数据的落脚点还是算法和模型。单纯的数据只是一些字节的堆积,我们必须通过对数据的清洗去除数据中的噪声,然后通过算法和模型学习其中的规律,才能将数据的价值最大化。接下来,本节将介绍推荐候选集触发过程中用到的相关算法。
10.4.1 基于协同过滤的召回
提到推荐,就不得不说协同过滤,它几乎在每一个推荐系统中都会用到。协同过滤的基本算法非常简单,但是要获得更好的效果,往往需要根据具体的业务做一些差异化处理。清除作弊、刷单、代购等噪声数据,这些数据会严重影响算法的效果。
合理选取训练数据,选取的训练数据的时间窗口不宜过长,当然也不能过短,具体的窗口期数值需要经过多次的实验来确定。
同时可以考虑引入时间衰减,因为近期的用户行为更能反映用户接下来的行为动作。User-Based 与 Item-Based 相结合。
美团的用户量巨大,最终用于协同过滤的矩阵也非常大,这些无法通过单机进行处理。为了进行大规模的协同过滤计算,我们基于 Hadoop 实现了分布式的协同过滤算法。在具体实现时,采用了基于列分块的方法
(Scalable Similarity-Based Neighborhood Methods with MapReduce)
,如图 10-5 所示。对于数据量更大的情况,可以考虑进一步分行分列划块的方法。
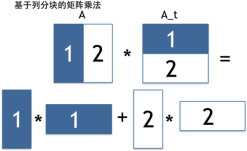
图 10-5 基于列分块的矩阵乘法示意图
10.4.2 基于位置的召回
移动设备与 PC 端最大的区别之一是,移动设备的位置是经常发生变化的。不同的地理位置反映了不同的用户场景,在具体的业务中我们可以充分利用用户所处的地理位置。在推荐的候选集触发中,我们也会根据用户的实时地理位置、工作地、居住地等地理位置触发相应的策略。
根据地理位置的粒度不同,召回策略又可以分为附近召回、当前商圈召回、当前城市召回等。
实际的应用场景中常常会遇到获取不到用户实时地理位置的情况,例如用户出于隐私考虑禁止 App 获取实时位置。这种情况下,只能推荐用户所在城市,比如推荐该城市热门商圈的内容,或者推荐旅游景点等信息。
能获取用户地理位置又可以进一步细分成两种情况:周边资源比较丰富;周边资源不太丰富。在周边资源不太丰富的情况下(例如用户所在的区域比较偏僻,周边商家和服务较少),可以扩大限制的距离,或者扩大 GeoHash 的范围。在周边资源较丰富的情况下,可以加强对距离的限制,并对候选按照一定因素进行排序,例如热度、销量等,选出 TopN 的结果。
10.4.3 基于搜索查询的召回
搜索是一种强用户意图,比较明确地反映了用户的意愿
。
但是在很多情况下,因为各种各样的原因,用户没有形成最终的成交。尽管如此,我们认为,这种情景还是代表了一定的用户意愿,可以加以利用,具体做法如下:
-
对用户过去一段时间的搜索无转换行为进行挖掘,计算每一个用户对不同查询的权重。
-
计算每个查询下不同 Item 的权重。 根据查询下 Item 的展现次数和点击次数计算权重。
-
当用户再次请求时,根据用户对不同查询的权重及查询下不同 Item 的权重进行加权,取出权重最大的 TopN 进行推荐。
10.4.4 基于图的召回
对于协同过滤而言,用户之间或者 Item 之间的图距离是两跳,更远距离的关系则不能考虑在内。
而图算法可以打破这一限制,将用户与 Item 的关系视作一个二部图,相互间的关系可以在图上传播。
Simrank 是一种衡量对等实体相似度的图算法。它的基本思想是,如果两个实体与另外的相似实体有相关关系,那它们也是相似的,即相似性是可以传播的。
10.4.5 基于实时用户行为的召回
前面介绍过,我们的推荐系统是一个实时的推荐,用户的实时行为在整个推荐环节都非常重要。目前我们的业务会产生包括搜索、筛选、收藏、浏览、下单等丰富的用户行为,这些是我们进行效果优化的重要基础。我们当然希望每一个用户行为流都能到达转化的环节,但是事实并非如此。
当用户产生了下单行为上游的某些行为时,会有相当一部分用户因为各种原因没有最终达成交易。
但是,用户的这些上游行为对我们而言是非常重要的先验知识。
很多情况下,用户当时没有转化并不代表用户对当前的 Item 不感兴趣。当用户再次到达推荐展位时,我们根据用户之前产生的先验行为理解并识别用户的真正意图,将符合用户意图的相关 Deal 再次展现给用户,引导用户沿着行为流向下游行进,最终达到下单这个终极目标。
目前引入的实时用户行为包括实时浏览、实时收藏。
10.4.6 替补策略
虽然我们有一系列基于用户历史行为的候选集触发算法,但对于部分新用户或者历史行为不太丰富的用户,上述算法触发的候选集太小,因此需要使用一些替补策略进行填充。
-
热销单:
即在一定时间内销量最多的 Item,可以考虑时间衰减的影响等。
-
好评单:
即用户产生的评价中,评分较高的 Item。
-
城市单:
即满足基本的限定条件,在用户的请求城市内的单。
为了结合不同触发算法的优点,同时提高候选集的多样性和覆盖率,需要将不同的触发算法融合在一起。常见的融合方法有以下 4 种:
-
加权型:
最简单的融合方法就是根据经验值对不同算法赋给不同的权重,对各个算法产生的候选集按照给定的权重进行加权,然后再按照权重排序。
-
分级型:
优先采用效果好的算法,当产生的候选集大小不足以满足目标值时,再使用效果次好的算法,依此类推。
-
调制型:
不同的算法按照不同的比例产生一定量的候选集,这些候选集取并集产生最终总的候选集。
-
过滤型:
当前的算法对前一级算法产生的候选集进行过滤,依此类推,候选集被逐级过滤,最终产生一个小而精的候选集合。
目前我们使用的方法集成了分级和调制两种融合方法,不同的算法根据历史效果表现给定不同的候选集构成比例,同时优先采用效果好的算法触发,如果候选集不够大,再采用效果次之的算法触发,依此类推。
10.5 美团推荐实践——推荐排序
如上所述,对于不同算法触发出来的候选集,只是根据算法的历史效果决定算法产生的 Item 的位置显得有些简单粗暴。同时,在每个算法的内部,不同 Item 的顺序也只是简单由一个或者几个因素决定,这些排序的方法只能用于第一步的初选过程,最终的排序结果需要借助机器学习的方法,使用相关的排序模型,综合多方面的因素来确定。在美团的推荐排序中,我们用到了 LTR 技术,使用机器学习来训练得到线上的排序模型。
10.5.1 排序特征
排序特征在排序的效果中起到非常重要的作用。在选择排序特征时,需要综合考虑特征的覆盖率、区分度等,同时需要结合业务的特点,来做特征选择。目前的排序特征大概分为以下几类特征,如图 10-6 所示。
图 10-6 排序特征









