 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
论文作者 | 钱桥,黄民烈,朱小燕,许静芳,赵海舟
(清华大学 & 搜狗公司)
特约记者 | 曾爱玲(厦门大学)
近年来,人工智能之火大家已经有目共睹了:从《未来简史》、《必然》等国外著作到李开复的《人工智能》、李彦宏的《智能革命》等成为畅销书,大众对于 AI 的热捧程度达到了历史高点,人机对话是人工智能领域中最重要的问题之一,聊天机器人(chatbot)顺势成为了研究的热点。
聊天机器人这一热潮可从两个角度进行解释:从学术上,机器人的智能一方面体现他能否理解人类的语言并给出合理的回复,另一方面也体现在他是否足够的类人化,即可以被当作一个人类用来交流,这对应了人工智能的终极目标—图灵测试(一种用于判断计算机是否具有人类思维能力的测试方法);从工业界看,真正的人工智能必须有一致的人格,否则任何 App 的谈话界面都会很无聊很机器人化,你真的只会把它当做个“machine”。因此,微软、Facebook、苹果、谷歌、微信和 Slack 等公司均在聊天机器人方面押了重注,依托科技巨头的资源或创业公司的热情,聊天机器人们正在努力渗透到我们生活的方方面面。
在论文访谈的第三期《“小会话,大学问” - 如何让聊天机器人读懂对话历史?》一文 中提到了聊天机器人这一话题,并且引来热议。本期论文访谈间我们将以”为聊天机器人固定一个角色/身份,使得聊天对话更加连贯、自然”为例,来向大家介绍来自清华大学智能科学与系统重点实验室的钱桥同学、黄民烈老师、朱小燕老师以及来自搜狗的赵海舟、许静芳的相关工作。
聊天机器人按照应用场景主要分为两类,任务驱动(task-oriented)和闲聊(Chatting)。任务驱动往往限定在单个或几个领域,例如在线客服或个人助手就属于此类范畴,以解决问题为目的进行对话,因此它们只需要尽可能高效地完成它们特定的任务。相比而言,闲聊往往是漫无边际的,话题的无限数量和用于产生合理回复的一定量的知识使之成为了一个难题,并且很容易聊到与 Chatbot 自身相关的话题上,他们的论文“Assigning Personality/Identity to a Chatting Machine for Coherent Conversation Generation”则主要应用在这样的场景中,为闲聊机器人定义一个固定的角色/身份,从而提升聊天机器人的类人水平。
对于 chatbot 的发展,我们给出了两个长期的研究目标:
1. 我们希望它能从任务驱动型到闲聊都能够有较好的回复:随着大数据时代的不断发展,闲聊机器人系统可以用更丰富的对话数据进行训练;并且为避免繁杂的人工定义,在大数据上可以自动聚类或抽取对话行为等信息。
2. 能够更加有一致的人格,并且能够有较高的“情商”,即聊天机器人的个性化情感抚慰、心理疏导和精神陪护等能力。
拥有“一致人格”的聊天机器人技术还十分不成熟,而对话中如果没有一致人格会出现什么问题呢?会对使用者来说产生什么困扰呢?举个例子,当你问某个 chatbot “你多大了?”,她可能会回复你“我啊……反正是九零后”,然后你接着问“你是九零后吗?”,她可能会回复“八零后”,非常直观。同样的问题想得到一致的回答,也就是将固定的只是或者人格整合进模型在目前看来其实是十分困难的,使用传统的 seq2seq 模型学习如何生成语义合理的回复,但它们没被训练如何生成一致回复的语义,因此在反复相同的语义输入时会出现不同的回复。

▲ 图1:与 chatbot 的对话测试
我们一起来看看这篇文章:首先,此文为闲聊机器人设定了固定的属性,包括但不限于姓名、性别、爱好等。这些属性被整理为
的形式,当机器人被问及与自身属性相关的问题时,应生成与自身属性相一致的回复。如下图所示:此文为 chatbot 设定为一个名叫汪仔的三岁男孩,他热爱动漫,特长是弹钢琴。
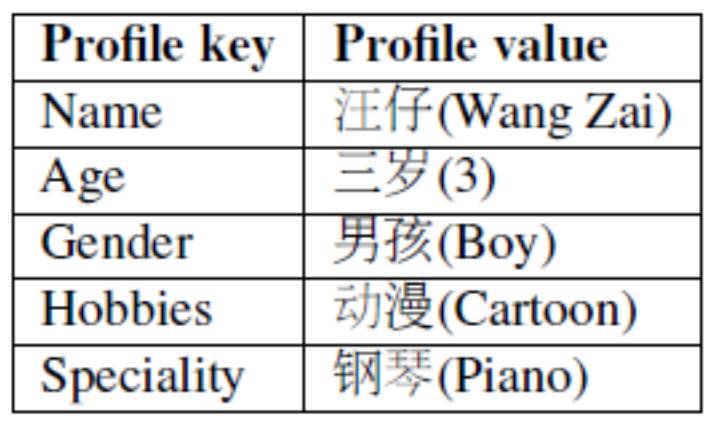
▲ 图2:定义一个固定的机器人属性(agent profile)
那么,研究面临的挑战是什么呢?实际上是主要来源于数据属性的不一致性,一方面是训练数据相互之间不一致,另一方面是训练数据与机器人不一致。例如,考虑训练数据中针 对“爱好”的回答,有喜欢篮球的,有喜欢足球的,还有喜欢羽毛球的,这些回答本身就不具有一致性;然而我们机器人的爱好可能是游泳,这与训练数据也不一致。如何使用这些不一致的数据训练模型,成为了此研究最大的挑战。
如何解决上述问题呢?本文提出了位置检测器(Position Detector),
它着眼于在训练数据中定位属性值的位置
。作者基于
词向量的相似度
实现 Position Detector 模块。例如,在“我 /喜欢”这句话中,由于“篮球”和“游泳”的词向量距离最近,所以断定“篮球”为属性值。此外,本文还将提出一种
基于语言模型的方法定位属性值的位置
,以追求更好的性能。 当 Position Detector 定位到 Reply 中的属性值后,可以通过替换的方法将消除训练数据的不一致性。
方法思路介绍:
如下图所示,本文模型包含三个重要的子模块。首先,为了判断给定的 Post 是否涉及机器人自身的属性,以及涉及了哪一条属性,属性检测器(Profile Detector)将对给定的 Post 进行分类。训练 Profile Detector 的过程中使用了带有噪音的监督数据。若分类结果不涉及机器人属性,则使用传统方法 seq2seq 解码。若分类结果涉及机器人属性,则使用双向解码器(Bidirectional Decoder)以属性值为中心进行双向解码。Bidirectional Decoder 是通过与属性相关的
数据训练的。
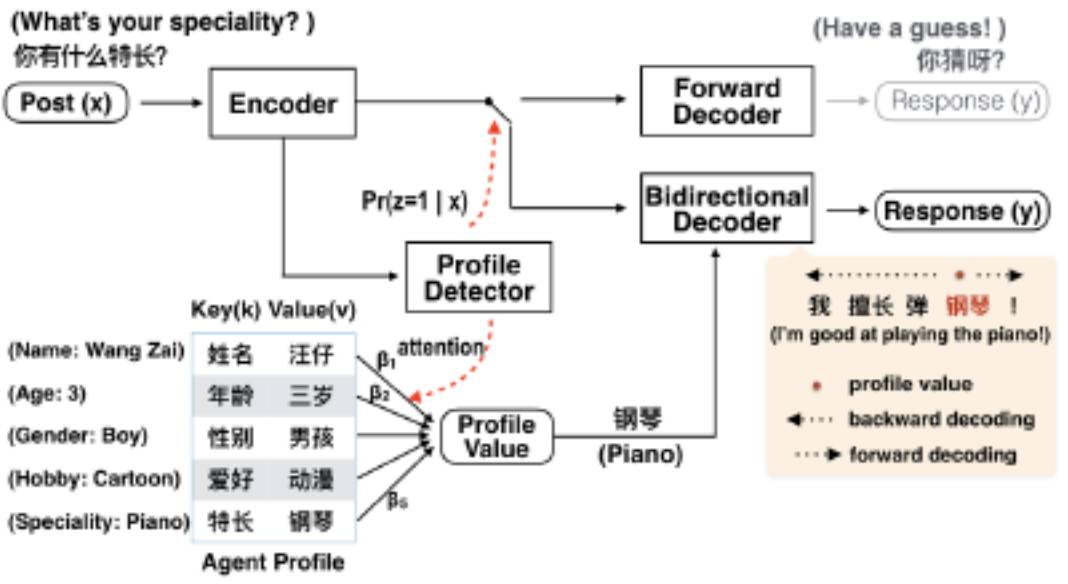
▲ 图3:
整个过程的生成图解
训练的时候因为很多训练数据里的属性都不是机器人的真实属性,于是使用机器人属性去做生成的 response 与训练数据的 response 会有不一致,所以就想到了用 position detector 替换一下消除这种不一致。因此,需要使用位置检测器(Position Detector)对训练过程做特殊的预处理,Position Detector 可以在训练数据中定位属性值的位置,从而解决在训练与测试过程中的落差。需要注意的是,Position Detector 在测试的过程中不参与生成(generation)过程。具体情况如下图所示,给定一对
,Position Detector 将会预测属性值钢琴(Piano)会被小提琴-4(violin)这一位置所替代,该位置将会被用于训练 Bidirectional Decoder。










