“大数据”成为2012年的关键词汇,被认为将会带来生活、工作与思维的重大变革。谷歌、亚马逊等互联网企业在利用大数据方面所做的工作使数据行业看到了新的发展路径。大数据在教育、医疗、汽车、服务性行业的应用所彰显的能量使企业、研究者对大数据的未来充满信心。《连线》杂志主编克里斯·安德森甚至早在2008年就断言数据洪流将会带来理论的终结,科学方法将会过时,其原话是“面对大规模数据,科学家“假设、模型、检验”的方法变得过时了”。
技术的变迁在任何行业都是值得欢欣鼓舞的,但不妨在此处借用苏珊·朗格在《哲学新视野》中的论述表达一点谨慎:
某些观念有时会以惊人的力量给知识状况带来巨大的冲击。由于这些观念能一下子解决许多问题,所以,它们似乎有希望解决所有基本问题,澄清所有不明了的疑点。每个人都想迅速的抓住它们,作为进入某种新实证科学的法宝,作为可用来建构一个综合分析体系的概念轴心。这种‘宏大概念’突然流行起来,一时间把所有东西都挤到了一边。
苏珊·朗格认为这是由于“所有敏感而活跃的人都立即致力于对它进行开发这个事实造成的”,这一论述放置在今日对大数据的狂热崇拜之中也极为恰当,大数据的流行并不意味着其它的理解与思考方式就不再适合存在,正如微软的Mundie先生所说,“以数据为中心的经济还处于发展初期,你可以看到它的轮廓,但它的技术上的、基础结构的、甚至商业模型的影响还没有被完全理解。”但不可否认的是人们确实将更多的学术兴趣转移到这一领域,而一旦人们能够以审慎的思路开始清晰的阐述它们,即便一时不能提供完美的解决方案,至少也是能让人有所获益的途径。
人们在谈论大数据的美好图景时当然没有完全忘记它可能带来的风险,但担忧多集中于大数据的后果,如信息安全,而没有集中于如何看待大数据本身。本文将就当前尤其国内技术环境下,进入大数据时代所面临的风险和存在的问题做简要分析,以希望能厘清概念,澄清一些误解。
大数据的面临的风险主要表现在以下几方面:
零售业巨头沃尔玛每小时处理超过一百万客户交易,输入数据库中的数据预计超过2.5PB(拍字节,2的50次方)——相当于美国国会图书馆书籍存量的167倍,通信系统制造商思科预计,到2013年因特网上流动的数据量每年将达到667EB(艾字节,2的60次方,数据增长的速度将持续超过承载其传送的网络发展速度。
来自淘宝的数据统计显示,他们一天产生的数据量即可达到甚至超过30TB,这仅仅是一家互联网公司一日之内的数据量,处理如此体量的数据,首先面临的就是技术方面的问题。海量的交易数据、交互数据使得大数据在规模和复杂程度上超出了常用技术按照合理的成本和时限抓取、存储及分析这些数据集的能力。
现在谈到大数据,难以避免言必称美国的倾向,那么美国究竟如何应对这这方面的问题呢?
美国政府六个部门启动的大数据研究计划中,包括:
• DARPA的大数据研究项目:多尺度异常检测项目,旨在解决大规模数据集的异常检测和特征化;网络内部威胁计划,旨在通过分析传感器和其他来源的信息,进行网络威胁和非常规战争行为的自动识别; Machine Reading项目,旨在实现人工智能的应用和发展学习系统,对自然文本进行知识插入。
• NSF的大数据研究内容:从大量、多样、分散和异构的数据集中提取有用信息的核心技术;开发一种以统一的理论框架为原则的统计方法和可伸缩的网络模型算法,以区别适合随机性网络的方法。
• 国家人文基金会(NEH)项目包括:分析大数据的变化对人文社会科学的影响,如数字化的书籍和报纸数据库,从网络搜索,传感器和手机记录交易数据。
• 能源部(DOE)的大数据研究项目包括:机器学习、数据流的实时分析、非线性随机的数据缩减技术和可扩展的统计分析技术。
从这份研究计划可以看出,绝大多数研究项目都是应对大数据带来的技术挑战,目前我们所使用的数据库技术诞生于上世纪70年代,大数据时代首先需要解决的是整个IT结构的重新架构,提升对不断增长的海量数据的存储、处理能力。
笔者最早进入数据分析领域是在1986年,使用的机器是长城,520,小的IBM机器,在完成数据输入、问卷输入之后,做一个最简单的命令操作,需要等三个小时之后才能出结果,我们现在面对大数据时的处理能力,形象化来讲就是当年PC机对小数据的处理能力。
这也就是大数据常和云计算联系在一起的原因,实时的大型数据集分析至少需要使用像MapReduce和Hadoop那样的分析技术并有数千台电脑同时工作,因为想做到实时分析,需要在数据库中空出分析工作空间,控制对资源和数据的访问,同时不影响生产系统。在现有的技术条件下谈大数据需要充分考虑到硬件设施和分析技术的不足,因为这是前提,这也正是数据中心成为谷歌、亚马逊最高机密的原因,Facebook的开源硬件计划得到众多企业包括国内的腾讯响应的积极响应也是基于这方面的现实需要。
 二、海量数据带来的风险是处处都是假规律
二、海量数据带来的风险是处处都是假规律

“如果只就人类的认识是零星、细小的而言,小之中蕴含着智慧,因为人类的认识更多的是依靠实验,而不是依靠了解。最大的危险必然是不顾后果的运用局部知识。”舒马赫在《小的是美好的》一书中用这段话来表达对核能、农业化学物、运输技术大规模运用的担忧,也适用于今日调查行业、企业、研究者对全数据的迷信、忽视抽样所带来的风险。
对于海量数据数据的计算能力随着分布式缓存、基于MPP的分布式数据库、分布式文件系统、各种NoSQL分布式存储方案等新技术的普及可以解决,但这只是关于数据处理的第一步(甚至这种处理方式本身都存在很大风险),还并不是最大的风险,大数据最为严重的风险存在于数据分析层面。
(一)数据量的增大,会带来规律的丧失和严重失真
维克托·迈尔-舍恩伯格在其著作《大数据的时代》中也指出这一点,“数据量的大幅增加会造成结果的不准确,一些错误的数据会混进数据库,”此外,大数据的另外一层定义,多样性,即来源不同的各种信息混杂在一起会加大数据的混乱程度,统计学者和计算机科学家指出,巨量数据集和细颗粒度的测量会导致出现“错误发现”的风险增加。那种认为假设、检验、验证的科学方法已经过时的论调,正是出于面对大数据时的混乱与迷茫,因为无法处理非结构化的海量数据,从中找出确定性的结论,索性拥抱凯文凯利所称的混乱。这种想法在某些领域是有效地,比如它可以解释生物的选择性,东非草原上植物的选择过程,但是未必能解释人,解释事件过程和背后的规律。
大数据意味着更多的信息,但同时也意味着更多的虚假关系信息,斯坦福大学Trevor Hastie教授用‘在一堆稻草里面找一根针’来比喻大数据时代的数据挖掘,问题是很多稻草长得像针一样,‘如何找到一根针’是现在数据挖掘的问题上面临的最大问题,海量数据带来显著性检验的问题,将使我们很难找到真正的关联。
我们以一个实际的案例来看一下样本量不断增大之后,会出现的问题:
表1 数据量增大之后带来的显著性检验问题
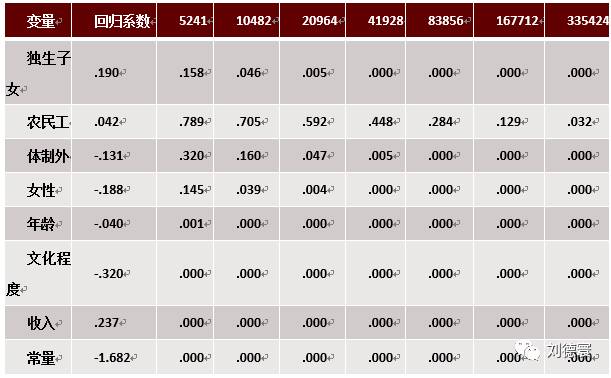
上表是关于2006年网络游戏历程扩散的回归分析,当样本量是5241个的时候,你会发现用一个简单的线性回归拟合这个数据,年龄、文化程度、收入这三个变量显著,当我们把样本量增加到10482个的时候,发现独生子女和女性开始显著,增加到20964个的时候,体制外这个变量也开始显著,当样本增加到33万的时候,所有变量都具有显著性,这意味着世间万物都是有联系的。那么在这个时候,如果说上亿个人呢?样本大到一定程度的时候,很多结果自然就会变得显著,会无法进行推论,或者得出虚假的统计学关系。此外,断裂数据、缺失数据(下文将会进行分析)的存在将会使这种虚假关系随着数据量的增长而增长,我们将很难再接触到真相。
事实上,真实的规律是这样的:
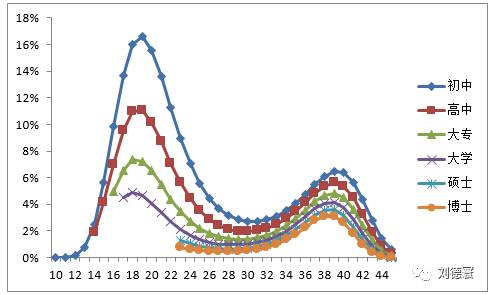
体制外
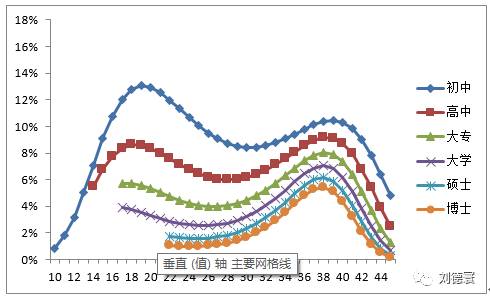
体制内
图1 2006年网络游戏扩散的Logistic回归
(数据来源:第一象限)
这是网络游戏2006年历程扩散的结果,实际模型是这样的,通过这个模型我们可以看到:
1. 分文化程度、体制内外不同年龄的人群在游戏使用上存在显著差异,可以清晰的看到在2006年网络游戏呈现出文化程度主导下的创新扩散规律。
2.在高文化程度人群中,开始向34岁-40岁扩散,呈现大幅增长,并形成一个峰值。
3.在低文化程度群体中,比如高中、初中在年轻群体中迅速扩散,形成一个峰值。
4.在2006年,网络游戏从文化程度的几个角度开始扩散,年龄不再只是高低之分,而是与文化程度变量综合形成的效果。我们看到网络游戏这种波浪式的扩散过程,不仅可以找到2006年是谁在使用网络游戏,也可以用生命周期、家庭周期来解释原因,而通过对体制内与体制外人群的使用差异分析,又可以展现出工作空间不同所带来的人的行为差异。当我们把2006年的结果放回网络游戏的整个扩散历程中时,所能看到就已经不再是网络游戏本身,而是新技术带来的社会变迁过程。





