王小新 编译自 Medium
量子位 出品 | 公众号 QbitAI
Alexandre Attia是《辛普森一家》的狂热粉丝。他看了一系列辛普森剧集,想建立一个能识别其中人物的神经网络。
接下来让我们跟着他的文章来了解下该如何建立一个用于识别《辛普森一家》中各个角色的神经网络。

要实现这个项目不是很困难,可能会比较耗时,因为需要手动标注每个人物的多张照片。
目前在网上没有《辛普森一家》人物的训练数据集,所以我正在标注各类图片来构建训练数据集。这个数据集的第一个版本已经挂在Kaggle上了,将持续进行更新,希望这个数据集能帮到大家。
在学了用TensorFlow构建不同项目后,我决定用Keras,因为它比TensorFlow更为简单易上手,而且以TensorFlow作为后端,具有很强的兼容性。Keras是Francois Chollet用Python语言编写的一个深度学习库。
本文基于卷积神经网络(CNN)来完成此项目,CNN网络是一种能够学习许多特征的多层前馈神经网络。
准备数据集
该数据集目前有18类,有以下人物:Homer,Marge,Lisa,Bart,Burns,Grampa,Flanders,Moe,Krusty,Sideshow Bob,Skinner,Milhouse等。
我的目标是达到20类,当然类别越多越好。各类样本的大小不一,图片背景也不尽相同,主要是从第4至24季的剧集中提取出来的。
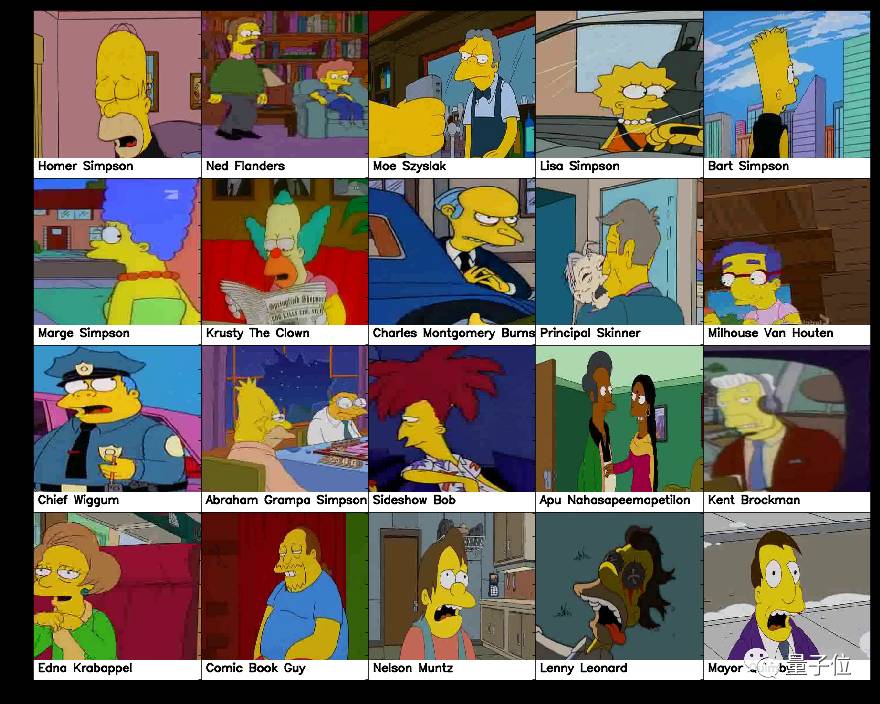
△ 部分人物的图片
在训练集中,每个人物各大约包括1000个样本(还在标注数据来达到这个数量)。每个人物不一定处于图像中间,有时周围还带有其他人物。
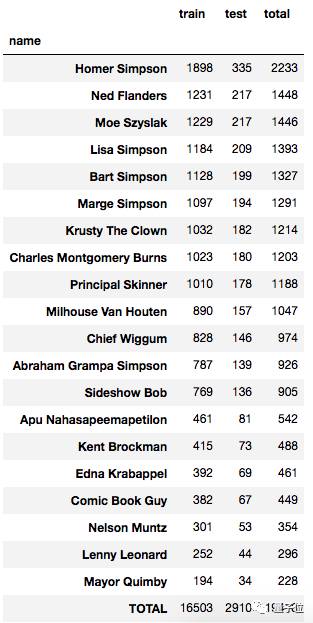
△ 人物的样本量分布
通过label_data.py函数,我们可以从AVI电影中标注数据:得到裁剪后的图片(左部分或右部分),或者完整版,然后仅需输入人物名称的一部分,如对Charles Montgomery Burns输入burns。
添加数据时,我也使用了Keras模型。对视频进行截图,每一帧可转化得到3张图片,分别是左部分、右部分和完整版,然后通过编写算法来分类每张图片。
之后,我检查了此算法的分类效果,虽然是手动的,但这是一个渐进的过程,速度将会不断提升,特别是对出现频率较低的小类别人物。
数据预处理
在预处理图片时,第一步是调整样本大小。为了节省数据内存,先将样本转换为float32类型,并除以255进行归一化。
然后,使用Keras的自带函数,将各类人物的标签从名字转换为数字,再利用one-hot编码转换成矢量:
import keras
import cv2
pic_size = 64num_classes = 10img = cv2.resize(img, (pic_size, pic_size)).astype('float32') / 255. ...
y = keras.utils.to_categorical(y, num_classes)
进而,使用sklearn库的train_test_split函数,将数据集分成训练集和测试集。
构建模型

现在让我们开始进入最有趣的部分:定义网络模型。
首先,我们构建了一个前馈网络,包括4个带有ReLU激活函数的卷积层和一个全连接的隐藏层(随着数据量的增大,可能会进一步加深网络)。
这个模型与Keras文档中的CIFAR示例模型比较相近,接下来还会使用更多数据对其他模型进行测试。我还在模型中加入了Dropout层来防止网络过拟合。在输出层中,使用softmax函数来输出各类的所属概率。
损失函数为分类交叉熵(Categorical Cross Entropy)。优化器optimizer使用了随机梯度下降中的RMS Prop方法,通过该权重临近窗口的梯度平均值来确定该点的学习率。
训练模型
这个模型在训练集上迭代训练了200次,其中批次大小为32。
由于目前的数据集样本不多,我还用了数据增强操作,使用Keras库可以很快地实现。
这实际上是对图片进行一些随机变化,如小角度旋转和加噪声等,所以输入模型的样本都不大相同。这有助于防止模型过拟合,提高模型的泛化能力。
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
rotation_range=0,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
vertical_flip=False)
在CPU上训练模型时会耗费较长时间,所以我使用AWS EC2上的GPU资源:每次迭代需要8秒钟,一共使用了20分钟。在训练深度学习模型时,这已经是较快了。
在200次迭代后,我们画出了模型指标,可以看出性能已经较为稳定,没有明显的过拟合现象,且实际正确率较高。
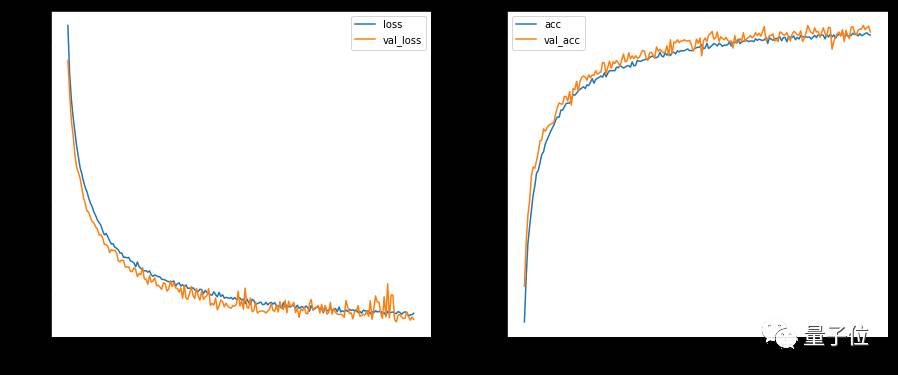
△ 训练时验证集和训练集的损失值和正确率
评估模型
由于当前样本量较小,所以很难得到准确的模型精度。但随着训练集样本的增多,这将更贴近实际的模型性能。我们使用sklearn库很快地输出了各类的识别效果。
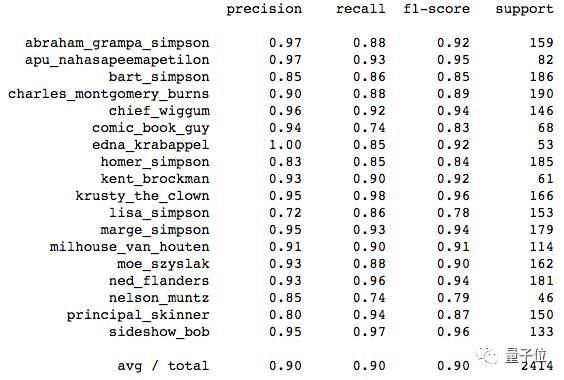
△ 各类别的识别效果
从上图可以看出,模型的正确率(f1-score)较高:除了Lisa,其余各类的正确率都超过了80%。Lisa类的平均正确率为82%,可能是在样本中Lisa与其他人物混在一起。

△ 各类别的交叉关系图
的确,Lisa样本中经常带有Bart,所以正确率较低可能受到Bart的影响。
添加阈值来提高正确率
为了提高模型正确率和减少召回率,我添加了一个阈值。
在讨论阈值之前,先介绍下关于召回和正确率的关系图。
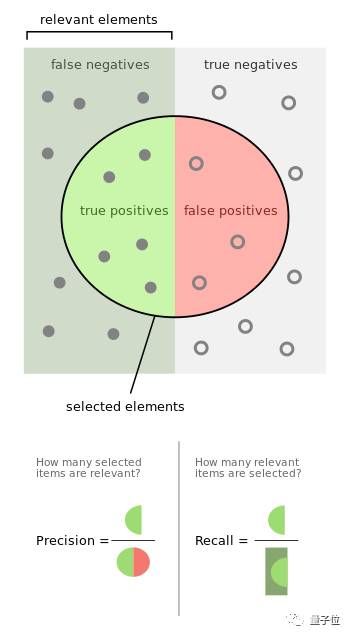
△ 召回和正确率的关系图
现在统计下正确预测和错误预测的相关数据:最佳概率预测,两个最相似人物的概率差和标准偏差STD。
如果人物1的预测正确率太低,预测人物2时标准偏差太高或是两个最相似人物间的概率差太低,那么可以认为网络没有学习到这个人物。
因此,对两个类别,绘制测试集的3个指标,希望找到一个超平面来分离正确预测和错误预测。
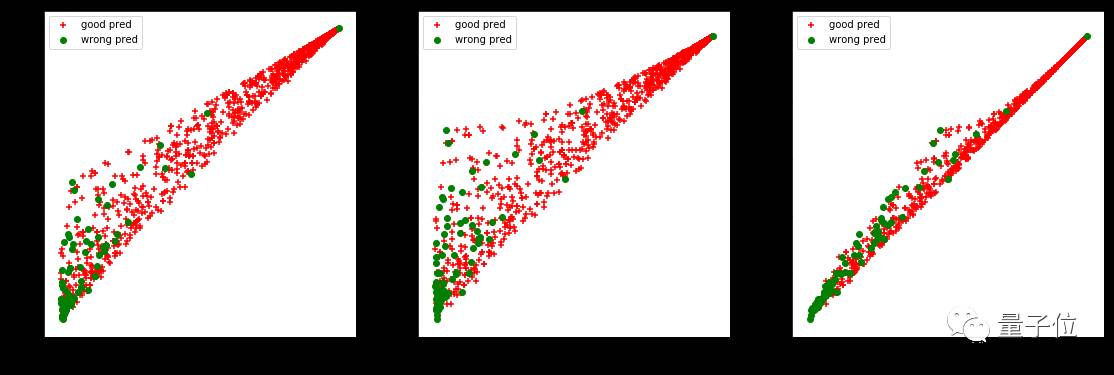
△ 测试集中多个指标的散点图
上图中,想要通过直线或是设置阈值,来分离出正确预测和错误预测,这是不容易实现的。当然还可以看出,错误预测的样本一般在图表的左下方,但在这个位置也分布了很多正确预测样本。如果设置了一个阈值(关于最相似人物间的概率差和概率),则实际召回率也会降低。
我们希望在提高准确性的同时,而不会很大程度上影响召回率,因此要为每个人物或是低正确率的人物(如Lisa Simpson)来绘制这些散点图。
此外,对于没有主角或是不存在人物的样本,加入阈值后效果很好。目前我在模型中添加了一个“无人物”的类别,可以添加阈值来处理。我认为很难在最佳概率预测、概率差和标准偏差之间找到平衡点,所以我重点关注最佳预测概率。
关于最佳预测概率的召回率和正确率
在模型中,很难平衡好召回率与正确率之间的关系,同时也无法同时提高召回率和正确率。所以往往根据实际目标,来提高单个值。
对于预测类别的概率最小值,画出F1-score、召回率和正确率来比较效果。
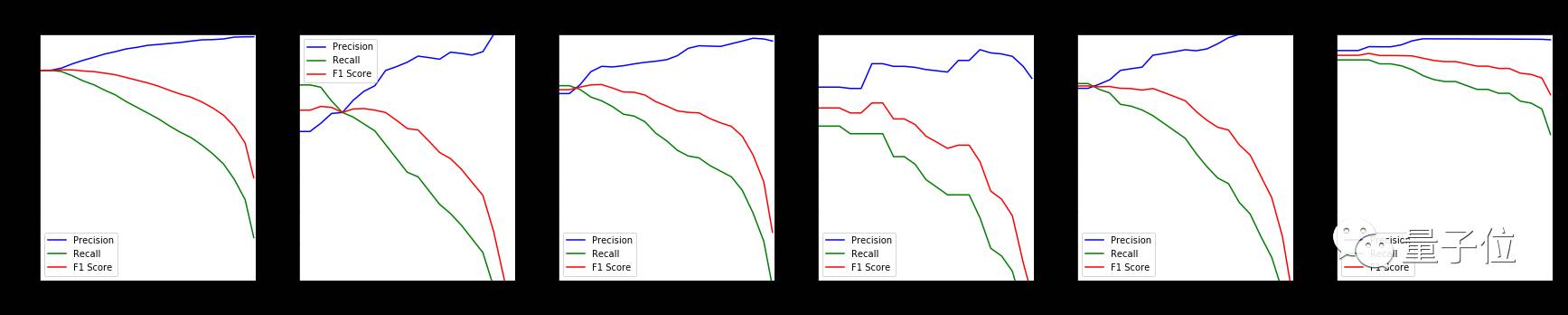
△ 对于所有类别或特定类别,正确率、召回率和F1-score与预测类别概率最小值的关系
从图10中看出,模型效果取决于不同人物。重点研究Lisa Simpson类别,为该类添加概率最小值0.2可能会提高效果,但是组合所有类别后,这个阈值并不完全适用。
所以考虑全局效果,对于预测类别的概率最小值,应该增加一个合适的阈值,且不能位于区间[0.2,0.4]内。
可视化预测人物

△ 12个不同人物的实际类别和预测类别
在图11中,用于分类人物的神经网络效果很好,故应用到视频中实时预测。在实际中,每张图片的预测时间不超过0.1s,可以做到每秒预测多帧。
相关链接
1. 辛普森一家的人物数据集:
https://www.kaggle.com/alexattia/the-simpsons-characters-dataset
2. 完整项目代码:
https://github.com/alexattia/SimpsonRecognition
【完】
一则通知
量子位正在组建自动驾驶技术群,面向研究自动驾驶相关领域的在校学生或一线工程师。李开复、王咏刚、王乃岩等大牛都在群里。欢迎大家加量子位微信(qbitbot),备注“自动驾驶”申请加入哈~
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容









