引言
本期PaperWeekly将带着大家来看一下ICLR 2017的六篇paper,其中包括当下非常火热的GAN在NLP中的应用,开放域聊天机器人如何生成更长更丰富的回答,如何用强化学习来构建树结构的神经网络和层次化的记忆网络等内容。六篇paper分别是:
1、A SELF-ATTENTIVE SENTENCE EMBEDDING
2、Adversarial Training Methods for Semi-Supervised Text Classification
3、GENERATING LONG AND DIVERSE RESPONSES WITH NEURAL CONVERSATION MODELS
4、Hierarchical Memory Networks
5、Mode Regularized Generative Adversarial Networks
6、Learning to compose words into sentences with reinforcement learning
A SELF-ATTENTIVE SENTENCE EMBEDDING
Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou & Yoshua Bengio
IBM Watson
Universit´e de Montr´eal
self-attention, sentence embedding, author profiling, sentiment classification, textual entailment
ICLR 2017
本文提出一种在没有额外输入的情况下如何利用attention来提高模型表现的句子表示方法。
本文提出的模型结构分为两部分,
1、BLSTM
这部分采用双向LSTM对输入的文本进行处理,最后得到BLSTM的所有隐层状态H。
2、Self-attention mechanism
同attention机制类似,我们需要计算一个权重向量a,然后通过对隐层状态H加权求和得到句子的表示向量。这个过程如下公式所示:
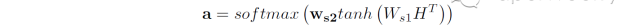
但是实际任务中,我们通常可能会对一个句子语义的多个方面感兴趣,因此我们可以通过下面的公式,获得多个权重向量组成的矩阵A。
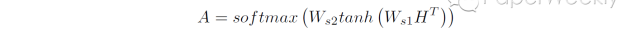
然后每一个权重向量a都可以得到一个句子表示向量v,所有句子表示向量组合在一起就可以获得句子表示矩阵M。
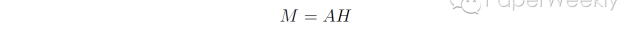
本文的模型在author profiling, sentiment classification和textual entailment三个任务上进行验证,都取得了较好的效果。
1、Yelp
2、 SNLI
1、A large annotated corpus for learning natural language inference
本文提出的self-attention方法用一个matrix表示一个句子,并且matrix中的每一个vector都是句子语义某一方面的表示,增强了sentence embedding的可解释性。
Takeru Miyato, Andrew M. Dai, Ian Goodfellow
Google Brain, Kyoto University和OpenAI
Adversarial training, text classification, semi-supervised learning
ICLR 2017
Adversarial training和virtual adversarial training都需要对输入的数字形式做小的perturbation,不适用于高维稀疏输入,比如one-hot word representations。文章扩展图像领域流行的这两种方法到文本领域,对word embedding进行perturbation来作为LSTM的输入,取代原本的输入向量。可以把这两种方法看做是正则化的方法,为输入加入噪声,可以用来实现semi-supervised的任务。
以adversarial training为例,文章对word embeddings进行adversarial perturbation,而不是直接应用在输入上。假设normalized之后的输入序列为s,给定s,y的条件概率为p(y|s;theta),其中theta为模型参数,则s上的adversarial perturbation r_adv为:
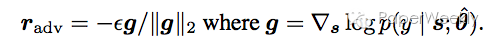
应用在LSTM上,如下图(b)所示。定义其adversarial loss如下:
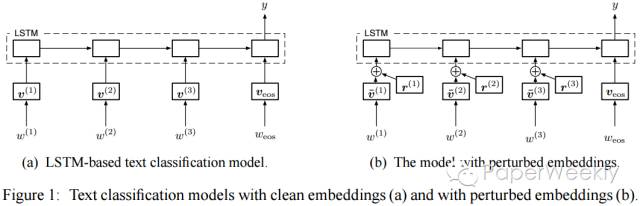
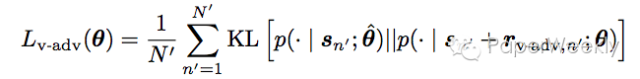
其中N为labeled的例子的数目。通过随机梯度下降来进行training。
文章也提供了virtual adversarial training的方法。
1、
IMDB
2、
Elec
3、
Rotten Tomatoes
主要列三篇work:
1、2015年NIPS, SA-LSTM。Semi-supervised sequence learning
2、2015年NIPS,One-hot CNN。Semi-supervised convolutional neural networks for text categorization via region
embedding
3、2016年ICML,One-hot bi-LSTM。Supervised and semi-supervised text categorization using LSTM for region
embeddings
作者将图像领域的adversarial training应用在了文本领域,改善了word embedding。传统的word embedding被语法结构影响,即使两个完全相反的词(比如”good”和”bad”)在表示形式上也是相近的,没有表示出词本身的意思。Adversarial training使得有相近语法结构但是不同意义的词能够被分开,可以用来做情感分类和sequence model等。
Louis Shao, Stephan Gouws, Denny Britz, Anna Goldie, Brian Strope, Ray Kurzweil
Google Research, Google Brain
Long and Diverse Responses
ICLR 2017
开放域聊天机器人如何生成更长且较为丰富的回答?
本文模型是基于经典的seq2seq+attention框架,在其基础上进行了若干修改,得到了满意的效果。不同于之前模型的地方有两点:
1、encoder不仅仅包括整个source,还包括一部分target,这样attention不仅仅考虑了source,而且考虑了部分target。
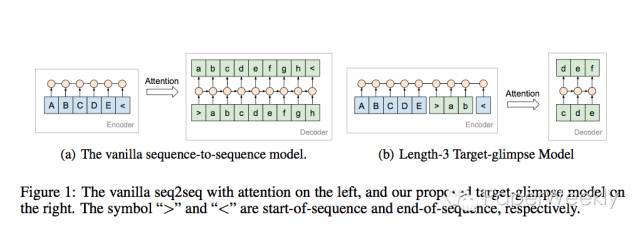
经典的seq2seq+attention在decoding部分会将source中的每个token都考虑到attention中来,之前有一种做法是将整个target部分也加入到attention中,效果上虽然有一定的提升,但随着数据规模地增加,内存代价太大。本文正是针对这一个问题,提出了所谓的“glimpse”模型,如上图所示,在encoder部分加入了target的前几个token,相当于是上面两种方案的一种折中。
2、提出了一种基于sampling的beam search decoding方案。
经典的beam search在decoding部分,是基于MAP(最大后验概率)进行贪婪解码的,这种方案生成的responses具有简短、无信息量以及高频的特点,通俗地讲会生成很多的类似“呵呵”的话,没有太多营养和价值。(Jiwei Li,2015)在解决这个问题时,在decoding部分通过MMI(互信息)对N-best结果进行重排序,这种方法对于生成短文本效果显著,但对于生成长文本效果不佳。因为,基于MAP的beam search天然存在这样的问题,N-best和重排序都解决不了根本性的问题。针对这一问题,本文提出了一种基于sampling的beam search解码方案,sampling即在每一步解码时都sample出D个token作为候选,搜索完毕或达到预设的长度之后,生成B个候选responses,然后进行重排序。
本文的另外一大亮点是用了大量的对话数据,用了很大规模参数的模型进行了实验。实验评价标准,在自动评价这部分,设计了一个N选1的实验,给定一个输入,将正确输出和错误输出混在一起,模型需要从中选择正确的输出,用选择准确率来作为自动评价指标。本文没有用到经典的BLEU指标,因为这个指标确实不适合评价对话的生成质量。为了更有说服力,本文用人工对结果进行评价。
本文用到的对话数据:
1、
Reddit Data
2、
2009 Open Subtitles data
3、
Stack Exchange data
4、本文作者从Web抽取的对话数据(待公开)
用seq2seq方法研究生成对话的质量(包括长度、多样性)的工作并不多,具有代表性的有下面两个工作:
1、Wu,2016 提出了用length-normalization的方案来生成更长的对话
2、Jiwei Li,2015 提出了在解码阶段用MMI(互信息)对N-best结果进行重排序,旨在获得信息量更大的对话。
本文模型部分并没有太多的创新,因为是工业部门的paper,所以更多的是考虑实用性,即能否在大规模数据集上应用该模型,集中体现在glimpse模型上。为了生成更加长、更加多样性的对话,在原有beam search + 重排序的基础上,引入了sampling机制,给生成过程增加了更多的可能性,也是工程上的trick。对话效果的评价是一件很难的事情,人类希望bot可以生成类人的对话,回复的长度可以定量描述,但多样性、生动性、拟人化等等都难以定量描述,所以在探索生成对话的这个方向上还有很长的路要走。





