雷锋网AI科技评论按:7月7号,全球人工智能和机器人峰会在深圳如期举办,由CCF中国计算机学会主办、雷锋网与香港科技大学(深圳)承办的这次大会共聚集了来自全球30多位AI领域科学家、近300家AI明星企业。雷锋网最近将会陆续放出峰会上的精华内容,回馈给长期以来支持雷锋网的读者们!
今天介绍的这位嘉宾是来自伦敦大学学院的汪军教授,分享主题为“群体智能”。

汪军, 伦敦大学学院(UCL)计算机系教授、互联网科学与大数据分析专业主任。主要研究智能信息系统,主要包括数据挖掘,计算广告学,推荐系统,机器学习,强化学习,生成模型等等。他发表了100多篇学术论文,多次获得最佳论文奖。是国际公认的计算广告学和智能推荐系统专家。
人工智能进入2.0时代,多智体互相协作,互相竞争就是将来发展的一个方向。汪军教授从多智体群体的特征切入,介绍了多智体的强化学习特性。具体表现为:在同一环境下,不同的智体既可以单独处理各自的任务,又可以联合在一起处理优化一个主要的目标方程,而且会根据具体的情况会有不同的变化。
互联网广告中运用到强化学习,效果就比较明显。通过对投放广告后的用户反馈的不断学习,最终就可以快速精准帮助企业找到目标用户。
在既要竞争,又要合作的场景下,AI智体处理起来就比较困难。他们和阿里合作开发了一套AI打星际争霸的系统,目的就是希望能找到计算量又小,多智体之间又能协同配合的方式。
如何让数量巨大的智体协同?
像一些网约车APP,每个用户终端,司机手上的终端,都可以视为一个智能体,它可以优化资源配置,决定什么价钱是用户可以接受的。这些上千万级的智体是需要一个人工智能合作的系统层面上的分析的。共享单车在这方面的需求尤甚。
智能体强化学习模型是否可以从自然界得到启发?
汪军教授讲到了一个生物界的self-organisation(自组织)理论,当一些小的智体遵循这个规则的时候,就会体现一个种群的特质。这些模型可以用宏观的事情解决宏观的问题,但是缺少一种微观的方法去观察这个世界。微观的东西和宏观的现象有什么关系,值得大家以后研究。
Lotka-Volterra模型,该模型描述的是:相互竞争的两个种群,它们种群数量之间的动态关系。汪军教授在此模型上做了一个创新,提出了老虎-羊-兔子模型。如果给智体强化学习能力以后,就和LV模型中的猞猁抓兔子的动态显现十分相似。当智体之间联合一起优化某一个目标或单独优化自己的目标,出现这两种情况的时候,作为一个群体,他们就有了内在的规律。如果找到这些规律,对开发智体模型是非常有帮助的。
强化学习里面的环境
以宜家为例:在宜家的的热力图上,可以看出商场内的活动是非常平均的,平均的好处是每个地方都放了不同的东西,用户都兼顾到了。但是如果开发一个强化学习的算法,让环境也能跟着用户的变化而变化,把路径安排最优,自然最好。
以分拣机器人为例:单个智体(机器人)要进行优化,以最快路径分拣快递,这个环境未必是最优。根据货物的统计特性来考量和设计将一些投放的洞放在一起,避免机器碰上,这样就可以优化这个场景。
以迷宫为例:一个人工智体,需要最快找到出口,分两个不同的维度,一个是给定一个环境,人工智体通过强化学习找到最优的策略走出来,另一个是当智体的智能水平不再增长,就可以来优化环境,使它最小概率或更难出去。后来发现通过强化学习的人工智体通过智体间的交互就能学会对环境优化。
以下为现场演讲全文,雷锋网做了不改动原意的编辑整理:
大家好!很高兴到这里来跟大家分享我们在UCL做的工作。今天我主要想讲的是“群体智能”,潘院士今天早上讲了人工智能2.0其中的一个方向,就是有多个智体互相协作、互相竞争,甚至是从社会学角度来讲,作为一个群体,它的动态系统,它们整个群体的特性是什么,我希望给大家做一个介绍。

在我讲之前,大概介绍一下UCL是什么。我经常回国在做报告的时候,大家问你从哪里来?我说我是UCL来的,大家会说:“是加州大学吗?”我说:“不是,我们在伦敦,我们学校的中文翻译叫伦敦大学学院。”我们相对来说还是比较低调的,我们的学术水平在英国还是不错的,在最近一次评比当中,我们是超过剑桥和牛津的,我们学院有29个诺贝尔奖获得者,比如说光纤之父高锟当时就在我们学校电子系,当时他的老板有一个想法是说从理论上证明有一种物质在通讯传播的时候有一种特性,他就找到了光纤。
今天想聚焦的是强化学习。可能大家都了解AlphaGo,其中里面核心的一个技术就叫强化学习,它与模式识别的差别是:它相对来说比较容易,当你没有数据和没有训练数据集的情况下,同样可以工作。这个系统可以直接和环境进行交互,获得它的反馈信息,在跟它交互当中,它不断地学,不断地把智能的东西学出来,所以更加自然,在用到实际场景的情况下也会更加灵活。它主要的特性是:一般来说把它的目标方程定义成一个长期的Reward(奖励)的方式,通过它可以得到一个优化的策略。
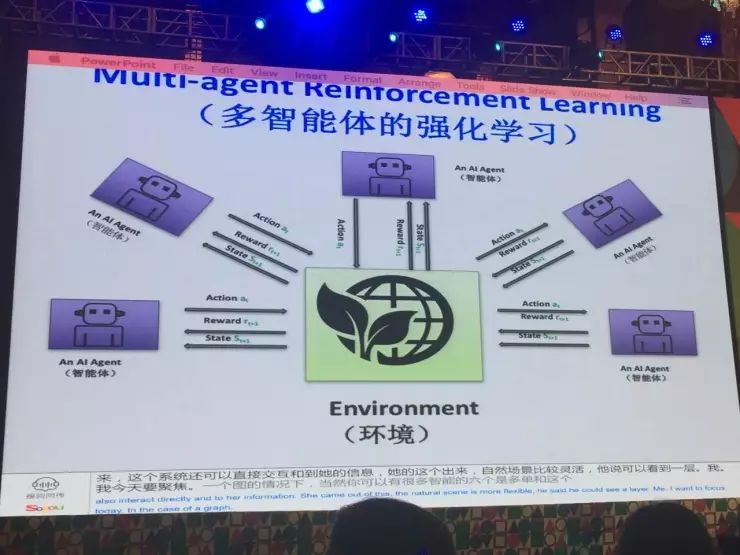
今天重点讲的是多智能体的强化学习,就是说在同样的环境下有一个智能体,当然也可以有很多智能体,它们单独的和环境进行交互,有一种情况下是它们各自优化自己的目标,但是这些目标之间有些约束,或者是它们联合起来优化一个主要的目标方程,根据具体的情况它会有不同的变化。
其中有一个方面我们过去做了很多工作,就是互联网广告。我们是比较早的在互联网广告中用上了强化学习的方法,目前我们可以在10毫秒之内做好决策,我们可以达到每天100亿的流量的情况下进行分析,可以帮助广告主精准投放,在环境交互的情况下,根据投放广告以后用户的反馈,它有不断的学习。

另外一个场景是星际争霸游戏,这个场景大家比较熟悉,我们通过对星际争霸里面的英雄的控制,可以找到多智体的规律,可以学习他们怎么样合作,怎么样和敌人竞争,怎么样通讯。这个是我们最近几个月跟阿里开发的一套人工智能打星际的系统,开发这个系统的其中一个最重要的原因就是想解决人工智能智体之间的通讯问题。当他们想一起合作起来攻打对方的时候,他们必须要有效的合作,我们希望在计算的时候,计算量相对比较小,同时又达到他们的协同目的,这时候我们就用了一个双向连通的方式,发现它的效果是非常明显的。

在目前多智体强化学习的还是研究处于非常初步的阶段。今天我大概讲两个方面的问题,第一个是大家目前的研究都是主要集中在少量的多智体之间的协同。如果是上万个的情况下,效果就不是很明显,看实际场景,特别是现在有很多这样的场景,它的人工智体的合作可能需要百万甚至上千万级的人工智体。
举个简单的例子,比如网约车APP,每个用户手上的终端,或者每个司机手上的终端,你可以想象成它是一个智能体,它可以做出决定,到底什么样的价钱我可以接受,甚至可以从系统层面给一些什么机制,能够把它的资源条线分配得比较好,因为有些高峰状态下,我的出租车比较少,但是需求量又比较大,而在其它的一些时候,可能出租车很多,但是需求量不是很大,怎么样调配,有一种机制能够把这个调配弄均匀。
这其实是需要有一个非常大的人工智能合作的系统层面的分析。共享单车的情况更加明显,你可以想象如果给每个自行车装了小的芯片或者计算机,它就是一个很智能的东西,可以根据它目前的情况,优化它的分布情况。

现在如果要做一个强化学习的模型,这个模型必须要可以处理百万级的智体,应该怎么去做?我们可以从自然界里面获得一些启发。如果我们去看生态学的研究会发现,很多动物或者植物有它们独特的性质,特别是在宏观种群的级别上面,它们有一定的规律,而其中有一个理论叫做Self-organisation,它的理论是说一些规律归结于一些非常简单的规则,当这些小的智体遵循它的时候,就会体现出一个种群的特质。
但是这些模型有一个很显著的问题,它可以用宏观的事情解决宏观的现象,但是缺少一种微观的方法去观察这个世界。比如说每个个体有它自己的兴趣,有它自己的优化方程,这个微观的东西和宏观的现象之间有什么关系?目前为止大家的研究还是比较少的。
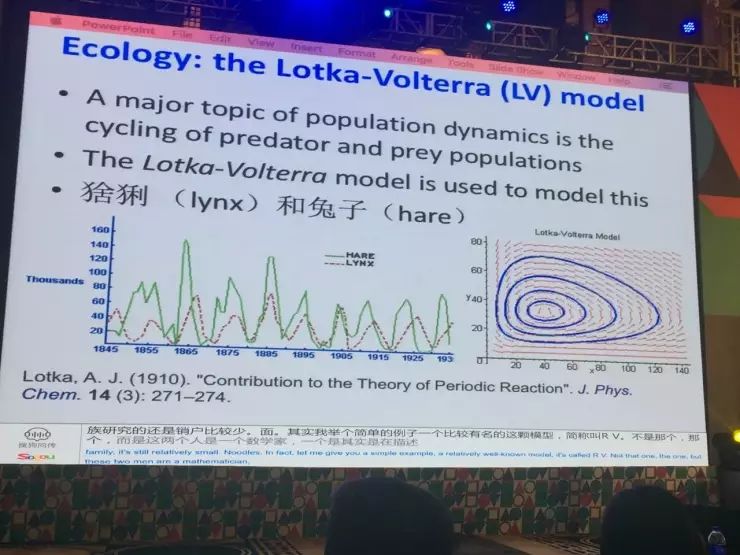
举一个简单的例子,其中有一个比较有名的模型简称LV (Lotka-Volterra) 模型,这是两个人的名字组合,一个是数学家、一个是生物学家,以他们的名字命名这个模型。这个模型是在描述在竞争的两个种群的情况下,它们的种群数量之间的动态关系。在自然界里面,生物学家或者是生态学家发现,种群之间的数量不是一个静态的过程,其实是一个动态的、互相约束的过程。比如说猞猁是兔子的天敌,假设只有猞猁和兔子之间的关系,其它的因素不考虑,我们会发现当猞猁的数量提高的时候,兔子的数量相对来说就要降低,当猞猁的数量降低的时候,兔子的数量就会增高,它们就形成了一种互动的关系,这种关系就可以用LV模型描述。
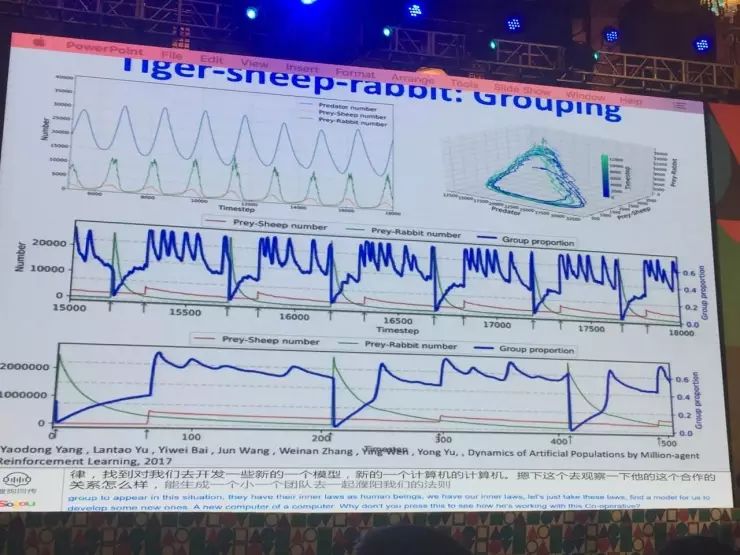
从我们的角度来考虑,如果人工智能体是智慧的,它形成了一个群落,形成了一个智体的网络,形成一个种类,它的内在规律是什么?我们会不会发现跟自然界中一样的规律呢?或者说它有不同的特性?怎么样去学习它们?我们就把强化学习作为每个个体兴趣的驱动,把它放到简单的生物学环境下。我们做一个捕猎的环境,里面有老虎、羊,老虎来捕羊,这样可以保持老虎生存下去,羊当然要躲,老虎去逮它。我们把这个模型做大,比如说有100万头老虎,我们以内在驱动的方式来驱动,看看种群当中有什么样的情况发生。我们用了一个比较简单的模型,现在用的是一个深度学习和强化学习结合的模型,每个老虎的输出就是它的移动的方向,还有一个就是它决定是不是和其它老虎一起组成团队去抓这个羊,还是它单独抓这个羊。给了它这些决定,我们让它在这个情况下想,要生存应该怎么办,强化学习告诉ta3应该怎么办,通过这个基础上,它就自然而然去学习它的生存的法则。
我们第一个实验做的是什么呢?我们不让它有任何智能,用一个最简单的情况,让它的行动随机,或者它的行动不遵循一个学习和环境变化。我们发现很有意思的一点,人工智能或者说我们人为生成的生态系统很快就不平衡了,主要的原因是微观上没有一个机制,在老虎这里没有动态的过程让它适应新的环境。
然后我们就给老虎学习的能力,发现它表现出的现象跟自然界里面的猞猁抓兔子的情况非常相似。有一点也觉得很意外,我们感觉一般来说当你的强化学习达到了最优点,它就停在那个地方。但是这个实验告诉我们,它是一个动态的平衡,我们把老虎和羊的数量用一个图反应出来,就会发现它形成一种圈状的形式,这个形式和这个LV模型非常相似。当然我们的情况是相对来说比那个LV模型要复杂一点,因为LV模型是一次性的一个简化模型,而我们这个地方考虑了各种情况,可以发现大致上它们是一个吻合的情况。所以我们发现在种群的情况下,如果有一个人工智体形成了种群,它和自然界有一定的内在联系。
这个研究很有意思的一点是,当人工智能在普遍被应用的情况下,我们突然发现一个场景,有很多人类,同样有很多人工智体,它们之间可以通讯,它们之间可以联合在一起优化某一个目标,或者它们单独优化它们自己的目标。当出现这种情况的时候,作为一个群体,他们有他们内在的规律,作为我们人类,我们有内在的规律,把这些规律找到,对于我们去开发一些新的模型、新的计算机人工智能的方法是非常有帮助的。
下一个实验我们做的是观察它的合作关系,它们能不能生成一个小团队去一起捕羊。我们把这个问题做得稍微复杂一点,加上了兔子,把兔子加进去之后,我们会发现当兔子数量非常高的时候,老虎种群里面去合作的数量非常迅速的降低,降低到零。因为兔子相对容易捕获,老虎不愿意组成群去抓羊。当兔子的数量慢慢减少的时候,愿意合作的老虎又开始增加了,所以它是一个动态的过程。

强化学习里面有一个环境,在标准的强化学习的模型里面,假设这个环境是不变的,或者说这个环境有它一定的概率在不断变化,这个概率是不变的,我不一定知道它,但它不是一个Designable(可人为设定的),也就是说它不是去设计这个环境,而是更加适应这个环境。但实际情况下发现,很多场景下,这个环境本身也需要一个适应的过程。举个例子,这是宜家他们的一个购物平面图,这里画的是它的热力图,是根据用户在它的购物商场里面活动的数量画的。这是一个非常好的设计,中间是吃饭的地方,人当然会很多,这个热力图其它的地方相对是比较平均的,平均的好处是你在各个地方放不同的东西,用户都兼顾到了,所以从这个分布来讲,这是很好的情况。但是这也是要设计的,你不可能说一开始的路径安排就是最优化的。我们可以开发一个强化学习的算法,让它强化学习这个环境也能根据这个用户的变化而变化。这是一个建筑系的教授进行的研究,他们做了一个地图模拟人在店铺里面走的情况,根据热力图反馈到铺面设计,来优化用户在这里面待的时间,或者说最大化用户可能消费的情况,可以通过那个情况进行一些优化。
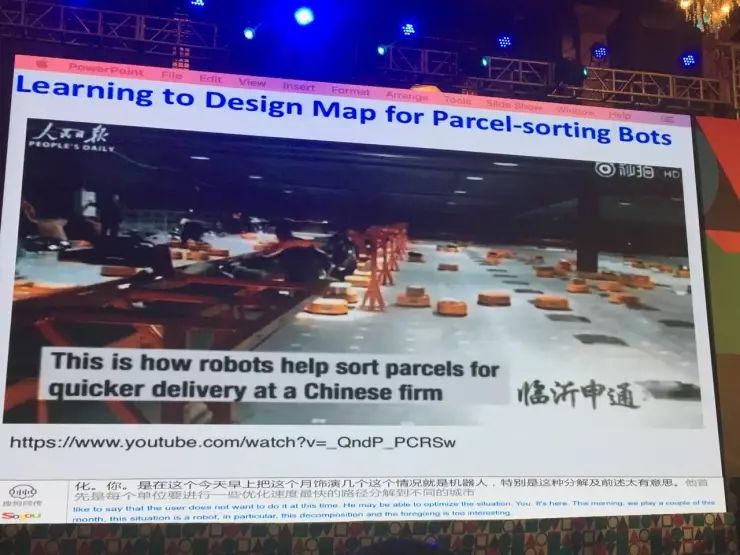
另外一个例子是分拣机器人,它首先是每个单体要进行一些优化,以最快的路径分拣到每个洞,每个洞对应的都是不同的城市。这个环境不是最优的,有可能这个机器人送到北京的信,另外一个机器人送到南京的信,它们可能会碰上,这个效率就不会很高。根据货物的统计特性,设计我把南京的洞放在北京旁边还是放在上海旁边,所以这个环境也是需要很好的考量和设计的。所以在标准的强化设计下你没法做设计,于是我们做了一个新的设计,我们叫Learning to design environments(学习设计环境),可以优化这个场景。
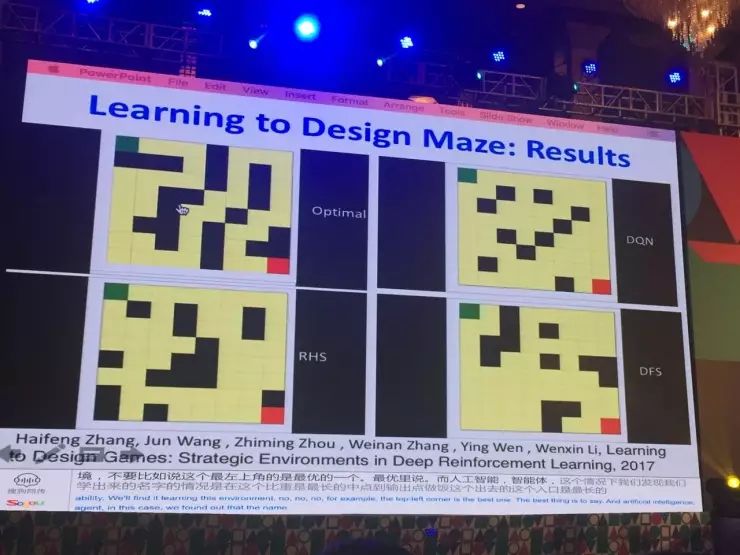
举一个简单的例子,假设来设计迷宫,我可以说我有一个人工智体,它的目的就是以最快的效率找到出口。环境是知道你的智体的智能水平,根据你的情况来设计迷宫,使得你最困难或者最小的概率可以出去。所以它们是一个竞争的关系。怎么优化呢?你会发现,它在两个不同的维度进行。在人工智体的情况下,它给定一个环境情况,想以最快的效率、最优的策略走出来。当你把这个人工智体学到的东西定住以后,你就可以在另外一个维度优化环境,我现在这个人工智体是这样的属性,我能不能根据的它的属性使得它的环境更困难,所以在这两个维度互相竞争、互相迭代,就可以达到优化的情况。这里举的例子是迷宫,当然还可以有其它的场景,比如说可以是机器人,也可以是宜家,当然也可以是其它的场景。
我们发现很有意思的是,如图中所述,左上角是根据不同的人工智体的能力,会发现它学出来的环境是不一样的,比如说最左上角是我们有最优的一个人工智能体,在这个情况下,我们发现我们学出来这个迷宫的情况是在这个给定的8×8的方块下,它从入口到出口的路径是最长的,我们没有告诉你这个环境就要这样优化,它通过根据人工智能体之间的交互就学到了这一点。右上角是用了一个DQN模型,这个模型是一个概率性的模型,也就是说这个智体在每次选择走的时候,它有一定的概率走上走下,有一定的随机性,你会发现在这个情况下,学到的环境有很多岔路,这个岔路就是为了让有随机的人工智能体陷到一些支路里面,所以这样的环境对它来说是最困难的。

大家研究现在的这个趋势,如果和人的智慧来比的话,其实差的还是非常远的。我非常同意笛卡儿说的一句话:“机器和人的能力差别非常大,其中有一个最重要的问题是意识(Conscience)......”我们现在还不是很清楚,我跟认知学家进行交流,认知学家经常会说,在他们的心里面有一个梦想,就想研究认知,研究意识,但是他又没法去研究,因为他没有一个很好的手段,连意识是什么东西大家都定义得不是很清楚。虽然我们在人工智能方面,包括强化学习这一块,做了很多的突破,但是离真正意义上的人工智能还是很远的,我们还要不断地进行努力。
我的分享到此结束,谢谢大家!











