5月13日,在Unite2017开发者大会上,莉莉丝技术美术总监李靖做了一则题为《如何在移动平台打造自适应画质的游戏》的演讲。

莉莉丝技术美术总监李靖
李靖曾在育碧先后担任资深美术关卡设计师、技术总监(美术)、资深技术总监与上海工作室美术技术发展经理,并于2016年2月加入莉莉丝。在18余年的工作当中,他在技术美术领域积累了相当丰富的经验。
以下为演讲实录:
大家好,非常荣幸这次Unity邀请我参加这次分享会,也很高兴跟各位见面。我是技术美术,在这个行业工作了18年左右。今天这个题目是怎样去制作一些能够自适应不同机种画面的游戏,或者是其他的一些多媒体方面的东西。
我今天会说到三个模块,第一个模块是介绍一些和硬件,或者和软件,其实就是和使用环境相关的知识点;第二块可能会说一些在制作这一类需求的时候,应该注意的技巧和知识;第三块是我个人在工作中总结出来的,一部分工作的实例。
我们先从第一部分开始,现在手机平台已经发展了很多年,硬件的种类非常之多,多到什么程度呢?多到至少个人几乎没办法统计这些设备。分几块来说吧,这几块都是和我们要做不同画质的游戏相关的一些硬件的支持。第一块就是SOC。

SOC是什么,SOC不是CPU,SOC包括CPU。简单一点来讲,就是在一块芯片上集成了几乎整套系统,我这边有一个高通的例子,其实就包括了显示试配的芯片,包括GPS定位的一些芯片。还有联发科的芯片,还集成了内存,这个内存非常容易和CPU、GPU封装在一起,合成一整个芯片,然后给到厂商去使用。
这点其实非常好,但是千万不要认为手机里只有一个CPU,其他的都是分开的设备。如果这样认为,可能针对性的优化就非常难去实现了。
我们来说第二个,GPU。

当年这个领域是列强纷争,现在能够存活下来的基本只有这三家,还有在后面会提到的另外一家,这三家,一是Imagination,这是最最有名的,因为它是苹果设备的GPU的官方授权商。当然它在安卓上也有一部分的客户,尤其是联发科,会使用其部分的GPU。
另外两家基本是独家,高通一个有Adreno GPU,这是整个移动图形部门收编后新的产物;第三就是ARM自己做的MALI。前面还提到一个,相对目前在移动平台上使用不是那么广但,作为在PC显卡是行业老大的nvidia。但是在移动设备上功耗我觉得做的还是稍稍欠缺一些,所以说厂商选择它的可能性比较小。
这里是和内存相关的,但是我这边没有写内存,写的是它的一个极其重要的指标:带宽。这边有一张图:
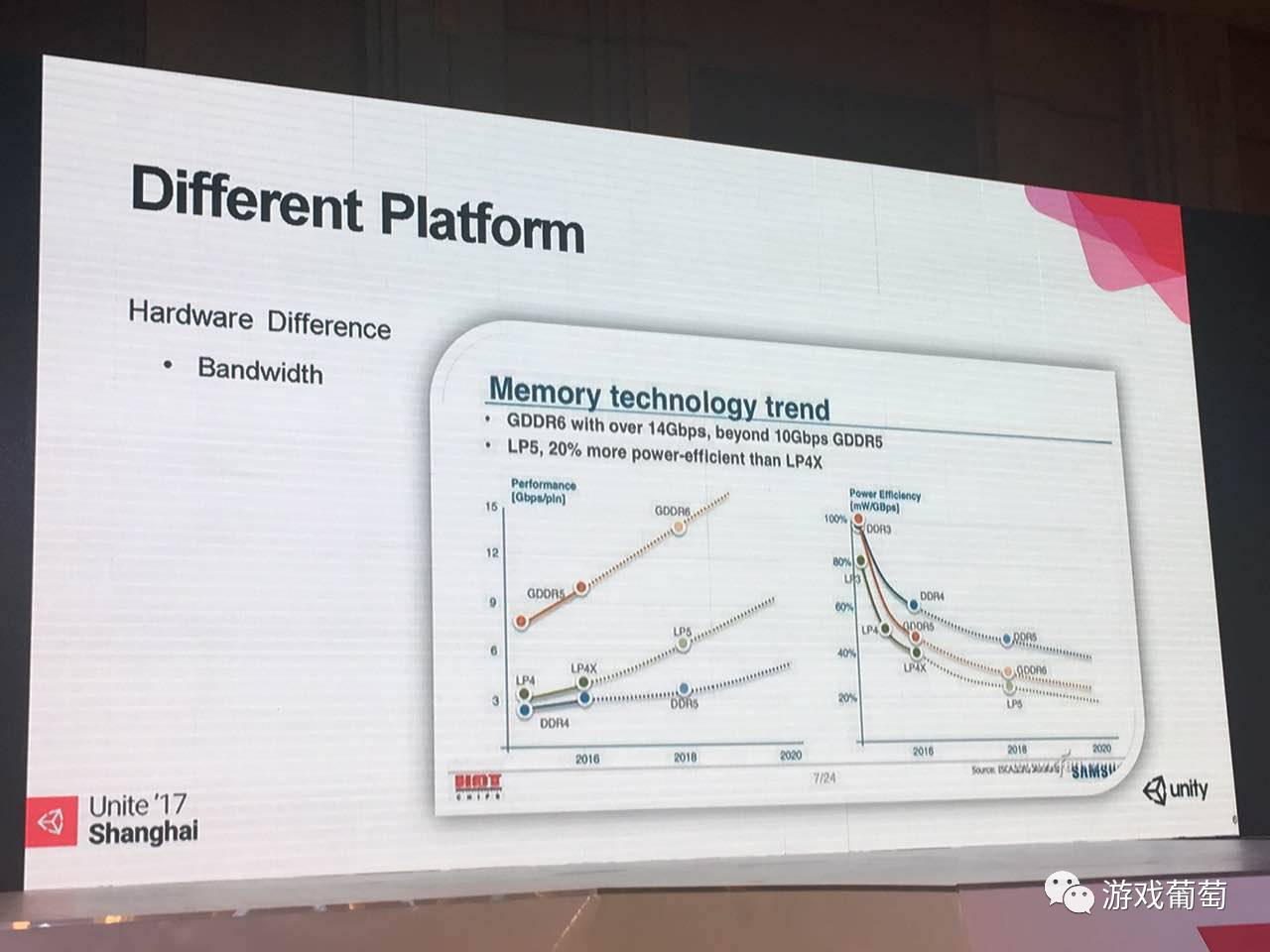
可以看到从2016年到2018年,PC端的那个主流的内存是DDR4,比较主要的显卡是GDDR5,Y轴都是以Gbps为单位的。手机内存会用到的是中间那条绿线,它的内存的带宽远远小于桌面级的GPU,这也就代表在移动设备上,我们开发那些图像类的作品,完全会受限于带宽。
右图右侧相对于带宽指标也重要,就是耗电性,这就是为什么带宽在移动设备上不够大,因为要考虑耗电,手机由电池供电,不是PC插一个电源随便用。电池耗尽了,用户体验就很糟糕,大家都抱怨苹果手机、安卓手机都只能一天一充,为什么诺基亚时代的神话没有了,这其实跟我们使用硬件的规格越来越高,越来越难控制有关系。这些东西都是一些硬件上的知识,可以对于你做优化有很大的帮助。
有很不同类型的硬件,如果把所有组合加起来会上千种,但是都有同样的问题就是发热还有电池消耗,这是一个恶性循环。

越发热电池消耗更快,然后电池没电了,游戏结束了。我们做弹性画质的一部分目的也是为了避免这样的问题,尽量延长玩家的设备的使用时间。在某些情况下,可能我们还要牺牲画质,或通过其他的方式来实现,所以这个对于用户体验来说还是很重要的。
前面大概综述了一下硬件上的不同,其实还有第二块就是软件。首先从操作系统层面来说,IOS和安卓是目前来说永远不会变的两个主题。

两个系统其实都不错,但是完全不一样。IOS封闭,好处是开发会很容易,因为设备的碎片化也没有那么厉害,并且对于后台进程的管理等等都非常严格,所以不会产生那种后台的进程在拼命地影响前台,或者说是消耗CPU、GPU资源的状态。
但是安卓的话,因为比较开放,它可以给开发者带来很多想象力,可以做很多苹果上面做不了的事情,确实是这样。但是它也有缺点,就是它的生态来说,会相对比较混乱一点。可能只有部分厂家会去完全根据安卓的那套规范去做产品。有些不好的小市场,可能会捆绑很多东西,带来的问题就是你的手机耗电非常快,并且在运行你的前台程序的时候,发现效率往往是和这个级别的硬件是不成正比的。这就是操作系统上带来最大的问题。
还有不同的是,Graphics API,这是跟驱动仅仅相关,API是需要显卡驱动,很少有人在一平台上提到显卡去这个,但是确实存在,任何硬件都是需要软件去驱动的,只不过不像PC端大家会说,现在N卡、A卡通过升级驱动,游戏跑的更快了,他们做了一些优化。
其实在手机平台上,同样有驱动这个概念。但是它的驱动是整合在系统里面,所以一般用户没有办法升级它。所以如果需要新的Graphics API,其实需要驱动的升级支持,比较传统是PC平台微软的DirectX还有OpenGL。

通过OpenGl我们有opengl es版本,但是这很古老了,还是上时代的产物,所以像苹果及OpenGL基金会都忍不住,也开发了全新的API。苹果的是Metal大家都在用,iPhone 5s就已经支持。OpenGL基金会开发出的新API vulkan也已经出现在今年的新设备上了,这些新时代的API给大家带来的好处就是,可以提供新的画质上的提升点,同时还可以提高渲染的效率,这可以让电池耗的更慢,这个外面有一个Mali展台,他们有这方面的展示,就是解释这个能源消耗的一个问题。
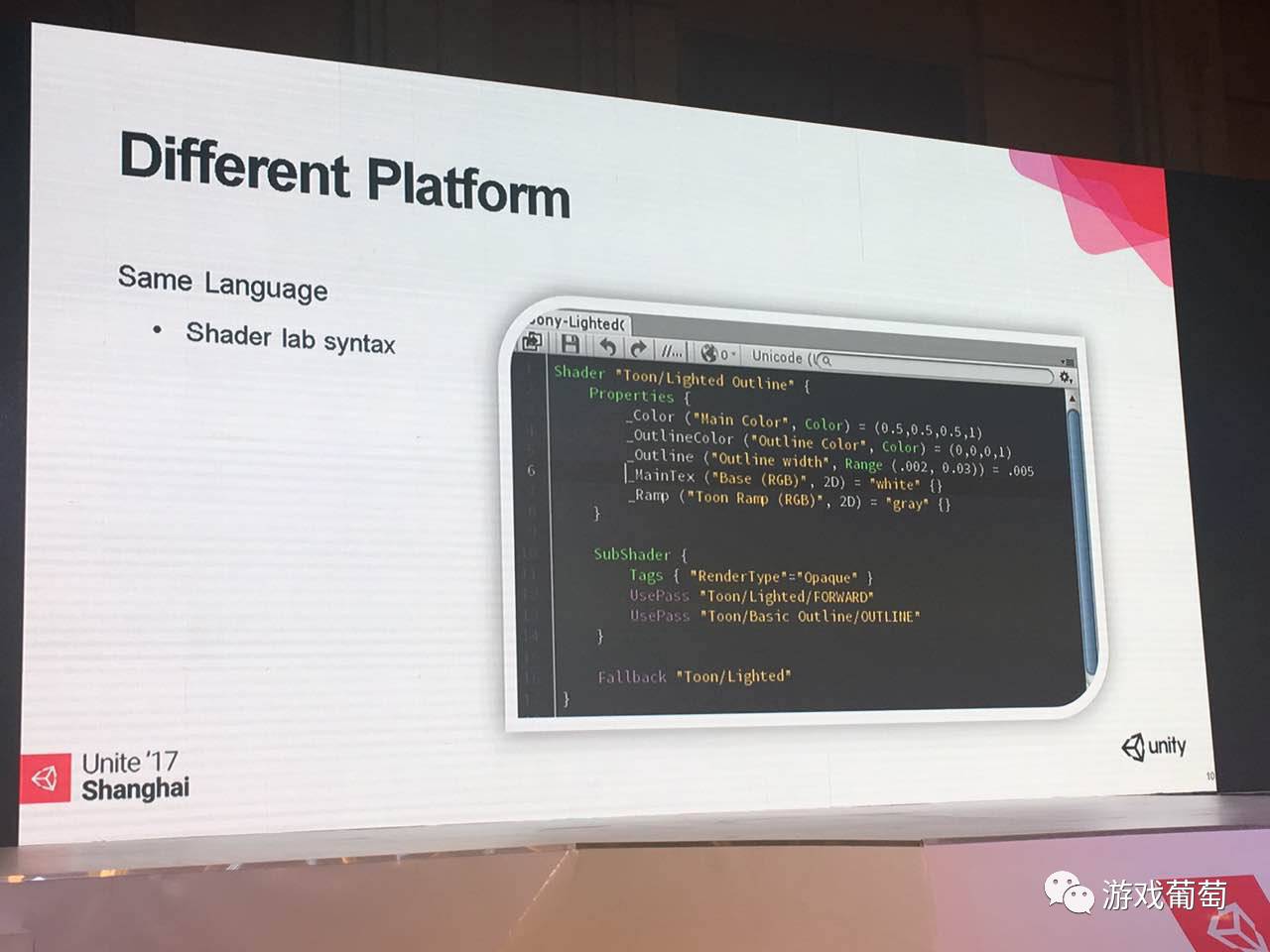
软件还有很多不同。Unity带给我们相同的语法,这个帮助极大,如果用其他类型的编辑器引擎的话,可能就要维护多一些,这个节省的成本非常可观。它的语法很简单,先定义属性,其次subshader块,再通过标签,通过pass来区分,渲染的顺序,包括渲染的状态等等。
综上所述,苹果已经有了很多设备,安卓的设备更多,那么首先我们要预知到,当前的硬件设备是属于哪个级别,如果知道了,你可以进行下一步操作,针对不同的因素,可以做减法;或者针对更好的设备,可以做怎样的加法。
首先IOS比较简单,Unity本身就提供,你只要用这个函数返回一下就知道当前的设备是什么,是属于第几代iPhone,或者第几代iPad,至于安卓就更加复杂,话题就很沉重了……
但是Unity提供一部分的功能,你可以通过UnityEngine.Systeminfo可以获得想要的东西,包括CPU、最大的显存、CPU架构、CPU的频率这一类,但是其实你光用这些东西综合出一套自己的算法来评估其实还不够。我觉得最重要的是
通过维基百科这个平台定义一份自己的表格。

因为现在大部分游戏都有配表,这是一张设备适配表,大家看第一屏,第一屏是把它分成了几种设备,还有是GPU,后面有一个Lv,然后是注释,这都是iOS的设备。因为iPhone每一代都是一个SOC,你可以通过查维基百科上,这一类的GPU的Gflops是多少级,这是第一点。
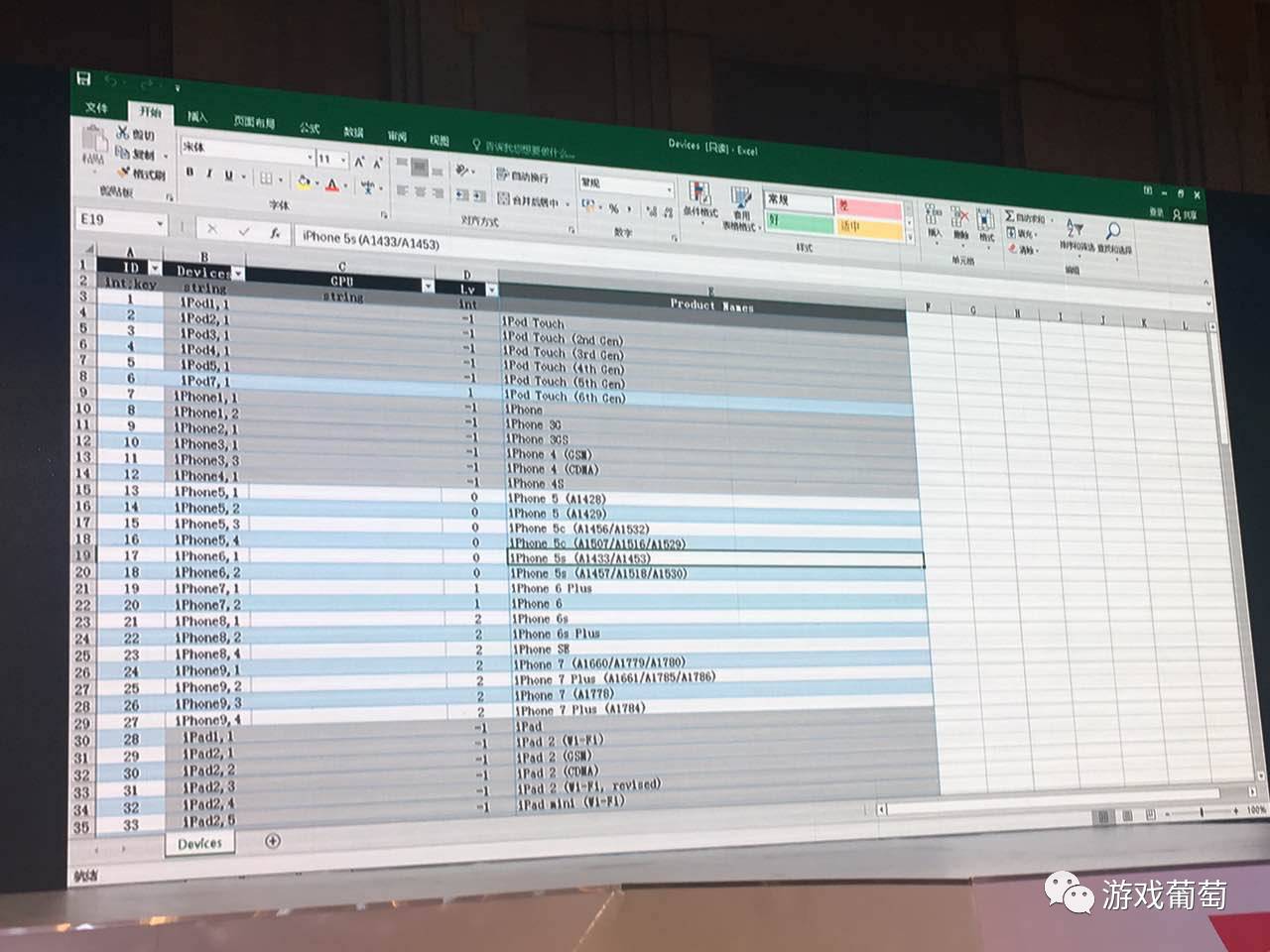
第二点,它支持3.0还是2.0?显存最多有多少?通过这一点我可以得到一个结果,现在的分类是,大家可以看到Lv是-1,在我这边-1的意思,其实就是我测试机最低标准以外可能会有不兼容的状态,而且它们都很低端,都是opengl es2.0。我开发的一些图形上的特性可能需要es3.0以上,那这些机器基本上可以排除掉。或者以后根据需要对它们进行支持,可以通过写一些扩展,或者其他的方式,来增量解决兼容性的问题。现在最新的设备是iPhone 7 Plus,它显示的效果会不太一样;iPad也是一样,也是同样的一个逻辑。

这边大家看到,设置这一栏没有东西了,因为安卓你如果去用设备来分的话,你这个表就非常非常长,不可能统计。所以我用GPU来统计,这相对容易一点,尤其是高通和PowerVR。高通每代对应的GPU是不一样,能很清楚这个相对应的SOC是什么,大家都知道,今后因为苹果和PowerVR合同解除的关系,imagination必然越来越加强安卓阵营的投入。
联发科的新SOC Xelio30,包括其他后续的产品,很多都是PowerVR GPU,还有Mali的GPU,这个也很容易区分。像MALI 400系列,T600系列,T700系列,包括现在的GT系列都是如此。
所有这些信息,包括厂商,SOC细节等,在wikipedia上都有,我认为有想法的人可以整合出更完美的表格。譬如打开wiki就可以查到,现在的SOC都是什么制程?GPU核心是什么?你可以做出一份比较详尽的档次表。
光有这点还不够,你还要去使用自己算的表格,如果这些条件都没有达成,那这个机器怎么处理?譬如新出了iPhone 8,厂商没有及时更新自己的表格,这边认出来就会是iPhone unknow。所以需要再制定一些规范,这个CPU主频怎么样,内存有多少,通过这些方法来决定这台机器可以显示什么效果。
前面关于软硬件环境的部分基本上都讲完了,其实最最重要的是首先知道差异化,并且知道这些东西和图形渲染是直接相关,可能不一定需要知道太多的细节。因为我们并不是硬件工程师,也不是做系统,也不是做驱动的,我们是做产品的,需要判断出什么是好硬件,什么是坏硬件就可以了,免得做盲目的优化。
这边其实也要稍稍吐槽一点,就是国外的硬件比较均衡一点,但是国内的稍微偏激一点,在某一块会做的比较主打。比如我这边是10核心的CPU,很棒,但是不提GPU,可能GPU就不是那么好。主打什么,那块肯定没问题,其他都是短板,这就造成很多机器的综合性能并不高。
说到短板,到了第二环节,我们要做的是什么?我们要做的是让整个渲染的效率没有木桶效应,一旦有木桶效应,那它就有瓶颈。

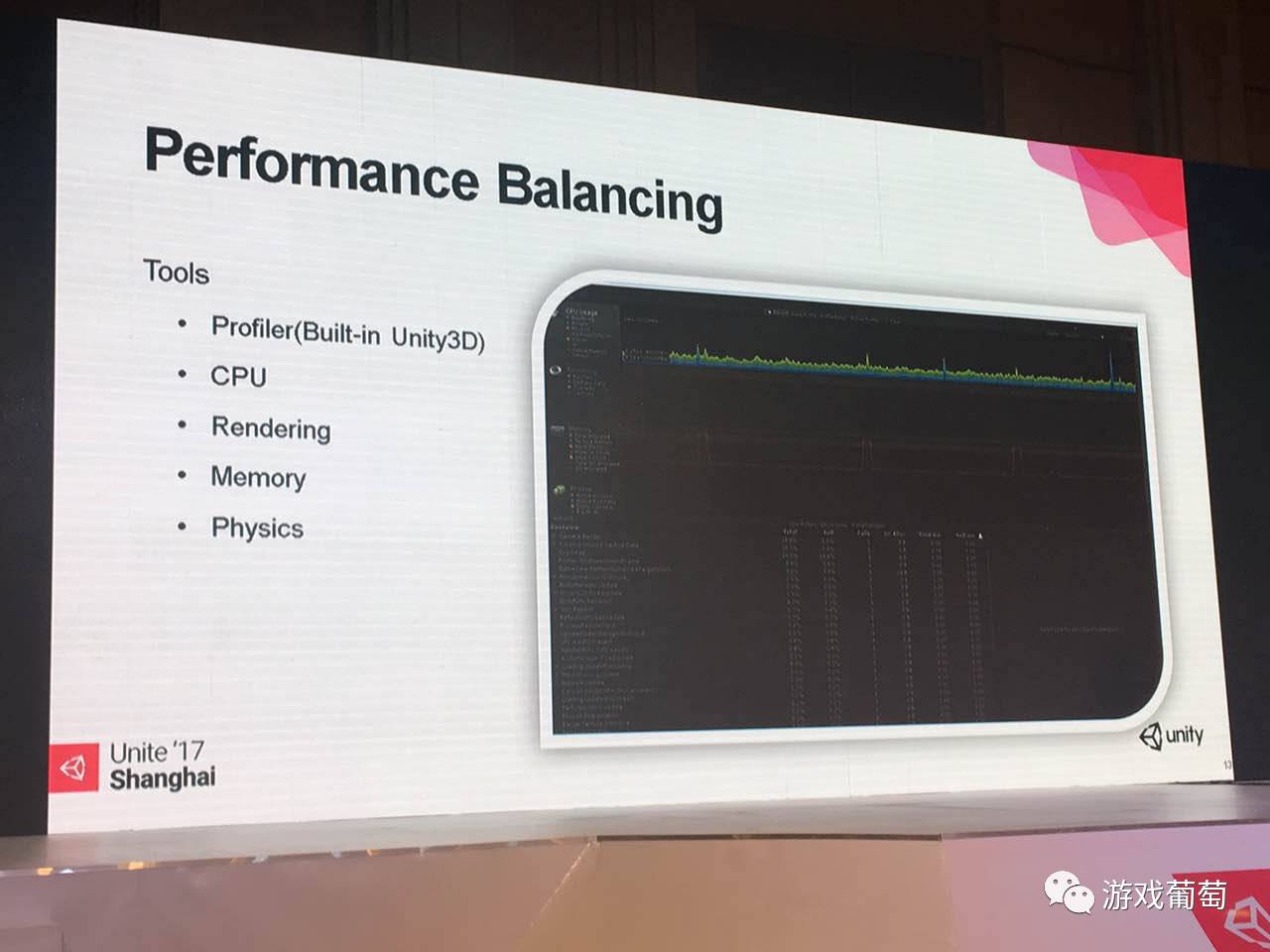
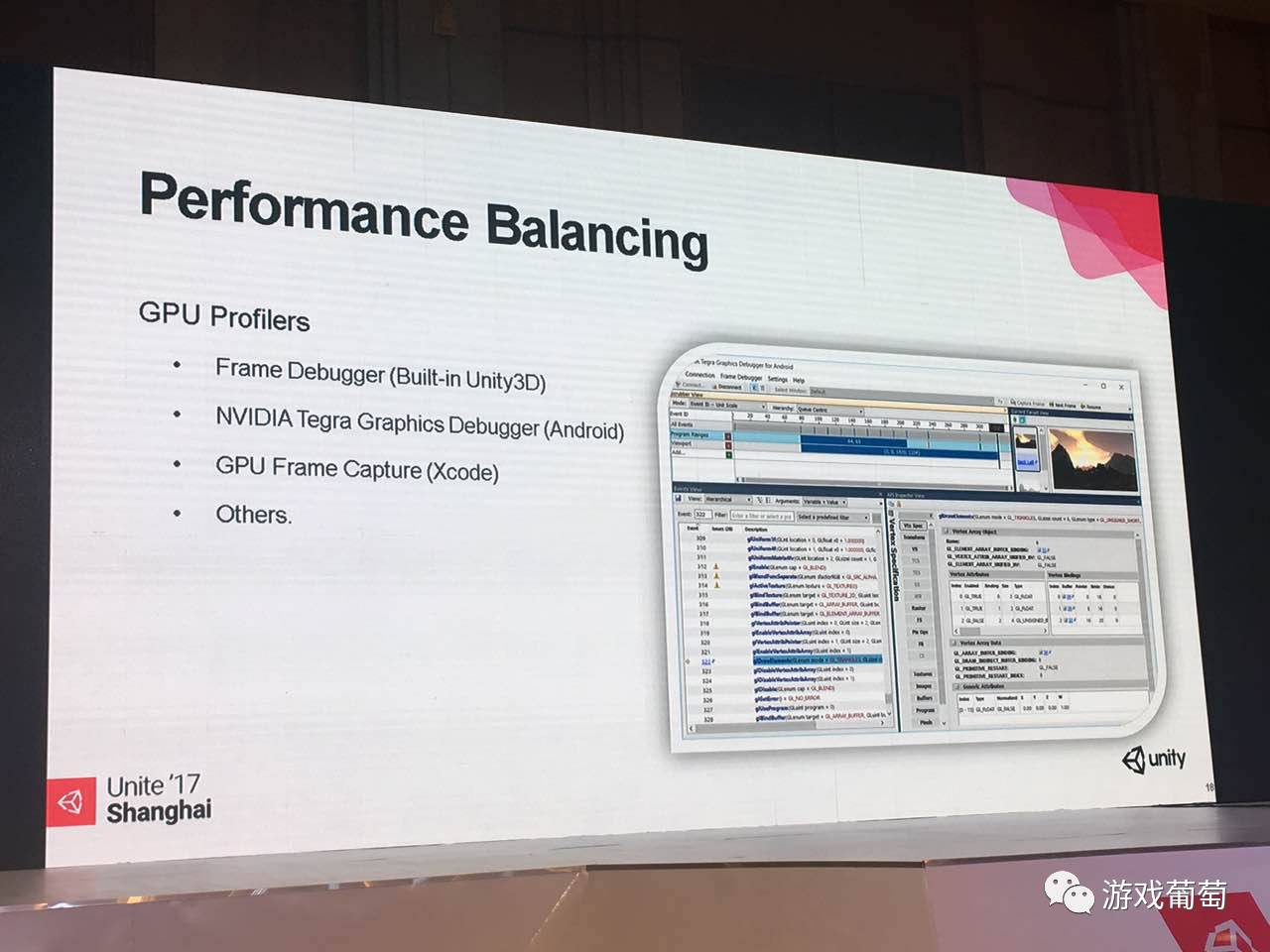
其实最最常用,每天都会用到的工具就是Unity中的Profiler,这个非常好用,因为能看到非常多的信息,并且能够有一个大致的评估范围。比如说CPU里面,CPU这一块到底是什么东西比较费,是Rendering比较费?还是脚本比较费?还是物理比较费?都是非常明确显示在里面。
并且CPU这块还能通过把左下栏那块表,细分出到底是什么函数比较费,可以做一些定位,如果切成另外一个界面。现在这个叫hierachy(层级视图),在工程设置里面,你可以设置成多线程渲染,就能看到现在的情况到底是CPU在等GPU,还是GPU完全不是压力,压力全部在CPU,因为多线程,渲染线程是分开的,并且有一个事件waiting for present,这个事件告诉其他硬件GPU当前在忙,你就等我吧,等我结束了就告诉你了。通过这个例子其实很容易知道,当前开发这款产品,你是逻辑上出问题了,还是渲染的东西过多,已经超过这个GPU能够承受的范围。
包括Rendering也会提供很多消息给我们。如果说我发现我们渲染的东西,GPU并不是很费,大部分时间都在CPU,看一下Rendering,这个也非常高,是不是没做batch(批处理渲染)?或者渲染的东西有问题,或者超标了?这种东西好处还在于可以连到真机进行调试,直接接上iPhone、安卓都可以跑。
像PowerVR的显卡如果顶点流超过范围,就会绘制两次,那时间就是双倍的,所以能看到详细信息。内存和我们这边就关系不大,略过。还有物理的也是一样,物理的话能够看得到当前的激活状态的有多少,当然越多越费。但是这边也要提到一点,你是不是简单的造型?如果都是复杂的造型或凸面体当然很费,如果是简单的造型其实就还好。
除了Unity内置的Profiler,如果需要更详尽的数据,我这边推荐不是三大厂家的,而是Nvidia Tegra Graphcis Debugger。它的一个好处在于可以很容易查看一帧绘制的整个过程,并且可以看绘制的结果,就和Unity的一个功能很像;
另外一个好处在于,你可以即时修改shader,这个时候就没有Unity的帮助,你得注意自己的语法,是GLSL的,还可以通过一些简单的参数的测试。比如说我不知道我现在的渲染的瓶颈到底在哪里,我试试看,把所有贴图就换了,点一下texture替换为2x2像素试试,发现帧数好了,那我知道了,我的贴图有问题,贴图换成2×2代表什么?代表你的带宽被撑满了,内存来不及传输了,你就知道针对点了,也知道在比较低端的平台应该怎么做。或者你也可以把深度测试关掉关掉,不比较Z,通过这样的排除法来替换,能知道这个场景,这个产品到底有什么问题在里边,这是一个方法。
当然另外三大厂商的GPU也可以用,只不过会相对麻烦一些,其实它们的用途作用是一样的。除了使用Profiler工具以外,我们还知道一些知识点,只有这些知识点都被解决了,你的渲染才不会成为整个游戏的瓶颈。
第一个其实解决Draw-CallS和batches。

你把Unity中的标签打开,Unity在运行的时候,会把这些标上Static的东西合并成一个,这个其实也是要看情况使用,不是说你把整个场景所有的东西全部合并效率就是最高的。因为Static batches有一个内存拷贝的问题,它会生成另外一份合并的内存,原来的资源都是在的,会生成一个新的。一般不会占用太多。但如果做的游戏是针对非常非常低端的设备,可能内存本来就非常捉襟见肘。
第二比较多的就是Dynamic batches,这个限制非常多,能够符合标准的那些物件,就是他们的材质是相同的,然后他们的transform,X、Y、Z ok,它们小于900 vertex attributes就可以合并在一起。
现在有一个方法是Instance rendering,使用相同的材质,可以批处理,这个其实是API相关,Opengles2.0就不支持,我们可以使用这样相对高级的方式,但是这个需要大家去改动shader才能实现。标准的Unity里面有专门的shader支持instancing,这些可以做到批量绘制,但如果使用自定义shader就需要自己维护。
就渲染的优先级来说,
static模式最高效,最快的;第二是instancing rendering,最后是Dynamicbatches
,所以使用优化技术的时候,大家可以有一些侧重点。
第二个支持点,是Overdraw,其实就是屏幕重绘。

现在业界还没有完全解决这个办法。这和当前的图形学的基础优化方案是直接有关的,原因在于不透明的物件,renderer会写深度图,第二个不透明的物件,在画的时候,会比较深度,只有在深度合适的情况下,没有被剔除掉才会画。但是透明物件不一样。透明物件因为不会去写深度,也就是你在屏幕上能看到多少透明物件,就画多少遍,可能会非常多。
比如说我们做一个很简单的例子,往这个游戏摄像机的面前扔一颗炸弹,这个炸弹其实在远处爆炸的时候,效果很酷炫,也不是很费。但是扔到屏幕前,它可能就直接爆炸了。我是指设备爆炸,不是指炸弹爆炸……一下子把很稳定的35帧变成2-3帧,这种情况我都遇到过。
针对这种问题,在制作的时候你就要
严格注意半透明的层叠的数量,注意他们全部展开之后的总的像素的数量。
也有方法能规避掉这些现象,那就是
避免在镜头前出现非常多的半透明物件,让它们在远处显示。
还有一块会对性能产生极大影响,就是Shader,这是今天比较重点讲到的东西。

shader在Unity中有两类:surface shader和vertex fragment shader。surface shader可以在非常顶尖的主机,比如如Xbox One上跑流畅,也可以在PC上的状态下有非常好的效果。但是针对手机游戏的话,surface shader虽然做了非常多的优化,但是因为太通用,所以还是比较费。
我个人主张,在手机平台上尽量使用vertex fragment Shader。
像素剔除默认就是把背面裁掉,但是有些情况,比如写了一个草的Shader,正反面都能显示,但是美术把这个shader用在建筑上,内部永远不会看到,这样的状态会导致有些情况下是两倍的输出,这个还是需要注意的。毕竟移动设备的GPU shader的流出率不是那么高,计算也差一些。
接下来还要考虑带宽,额外的深度操作就可以占满带宽。举一个例子来说,就是我所有东西都是不透明的,然后我画阴影,另外一个摄像机在不同的角度,要重复画一遍深度图,那就是额外的带宽,可能就会导致翻倍。或者也有可能让你比较低端的机器的带宽直接撑满,做不了其他的事。
还有一点是ztest(深度测试),如果这个设置不对,虽然是不可见,但是开销是实际存在的。
还有一点就是叠加的模式,这种情况非常少,你做半透明,你这个半透明后面被遮挡的东西就没有了,你看到就是一个非常奇怪的景象,除非你需要这样的特效。
下面有几点建议:尽可能把所有的计算放到顶点计算中,因为顶点计算比较省,而且现在的GPU既能处理顶点,也能处理像素,因为在几年前这些处理环节还是分开的。大家都知道,像素的输出永远比顶点多得多,如果说我把所有计算都放到顶点上,在顶点到像素之间做一个差值计算,一个点到另外一个点中间,线性做一些多度,类似这样的方式,把这个计算的结果转换到这个级别,很多计算可以做简化,在这块把它放到顶点,并且保证这个足够强大。
现在手机虽然屏幕不大,再大也就是6-7寸,但是像素的密度极高,分辨率非常高,往往是2K,1080P和720P也意味着很高的代价。1080乘720是多少像素点?屏幕上绘制三遍再×3就是开销。但它直接、、其实可以公式化。在有时间有预算的情况下你应该尽量自己写,这样可以让你的效果表达更好一点,或者走的更节省一点。
这边的话又提到带宽这个词,从这几个点来说,都会带来带宽上的问题。

第一个是贴图的Filtering,就是过滤器,其实从3D世界远近的角度来说,贴图做的越小,还原度会越高,并且和近处的高分辨率的贴图之间的过度得更平滑。但是带来的代价就是它是多重采样,并且有比较复杂一点的计算,而且这个没有太大的关系。因为这个是硬件级别,是直接可以处理的,但是会占用带宽。
第二点是Mip-maps,它在安卓上有意义,在PowerVR的GPU上帮助会有一点,但是非常少,因为使用的渲染方式是deferred tiled base rendering,所以一定要注意这些问题。当然我指的都是3D物件的贴图,2D其实很多情况下大家都不用mipmaps,因为纯粹是浪费。
还有就是贴图大小。贴图大小不光占显存,还会让传输变慢。越是大的贴图,cache miss率会越高,传输效率也越低,这就是恶性循环。
还有一点,就是我们自定义的一些后期渲染用的postprocess,这个越少越好,这也是为什么Unity到现在为止,不建议让延时渲染这样的技术跑在手机上。其实就是因为手机带宽永远不够,根本跑不动,那么高分辨率,同时3到4个gbuffer,没有那么大的带宽。
带宽其实是渲染时经常出现的一个瓶颈。我以前做主机游戏比较多,带宽很大,比如Xbox One的esram带宽就非常大,但是内存很少。我们为了把一个游戏用延时渲染的方式需要的gbuffer塞进去就需要做很多优化,如果放到主存,虽然能用,但延时就非常厉害,没有实用性;PS4用的主内存速度比较好,可以用全尺寸gbuffer。大家在手机上如果一定要做延时渲染,理论上来说也是可以的,但是只能用非常低的画面分辨率,这个画质非常差,优点不足以弥补缺点。
再讲一下我在莉莉丝实现这套系统的一些想法。这个功能其实有一个切入点,那就是quality setting。
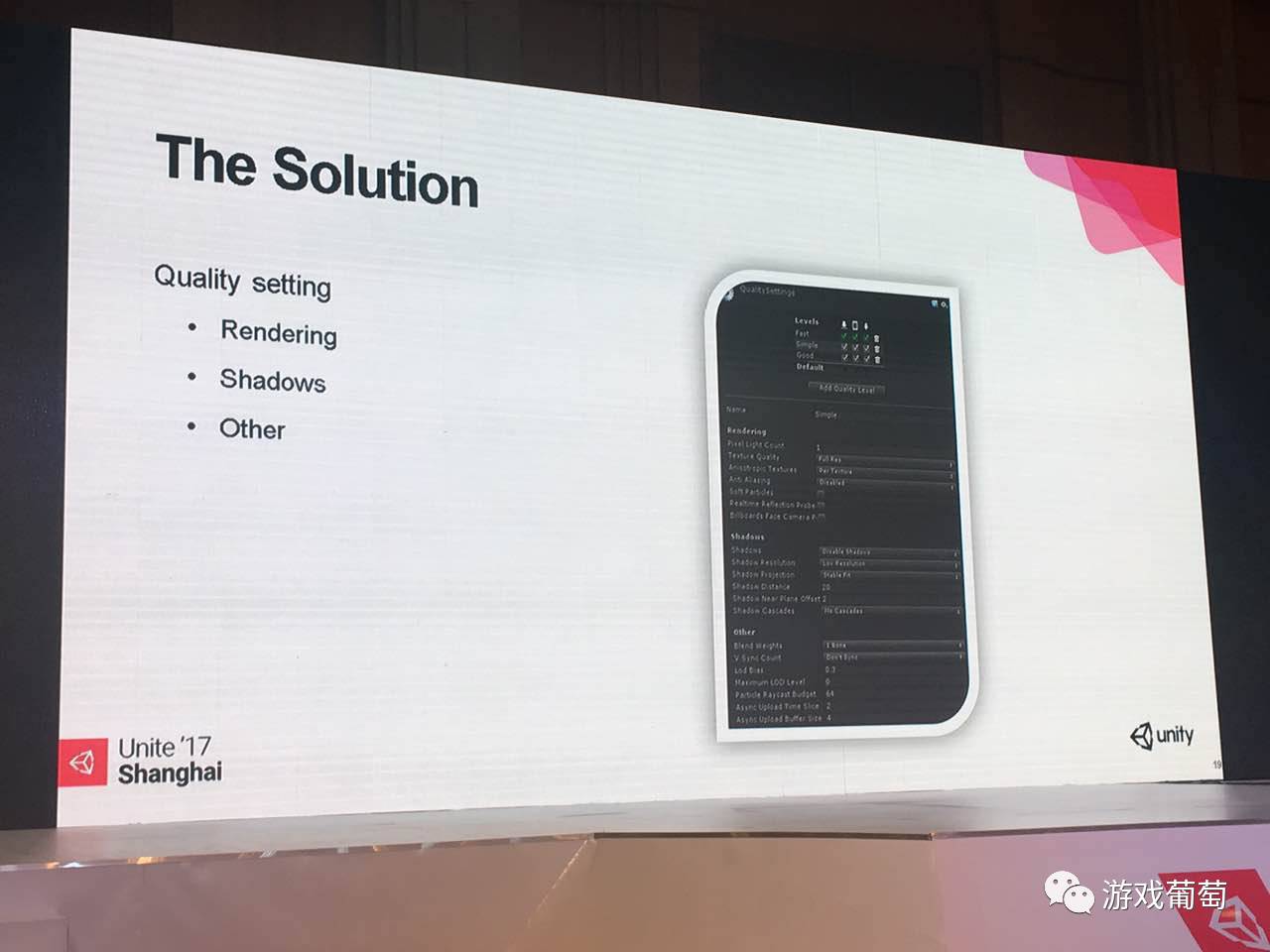
它可以把游戏的画质分为Fast、Good等等,可以控制一些东西。第一个是pixel lighting接受的数量,在forward渲染的模式下,你的物件就以多pass的模式画下来,这样的话效率很低。在我这边的demo里面,低配全部是零,最多有一个,不包括太阳光。
第二,贴图分辨率有两个选项,一种是全尺寸,一种是半尺寸,半尺寸在有些情况下解决带宽的问题。还有就是一些过滤方式,是不是基于每张图都做,还是强行都关闭,这个因需求而异就可以。
还有就是soft particle开销很大,会有额外的深度图的输出,其他的一些选项开销都不是那么大,所以没太大的关系。reflection probes我现在没有用到它,其实就是做一些反射的点,在场景里面有很多,还要是实时更新这些probes,对CPU的负担肯定很大。然后还有下面这一块,在我的例子里面,shadow全部是自己实现的,所以在高中低配,把这些全部都禁掉。
还有其他的选项,也会有帮助。像第一个是bone weights,这个是对于蒙皮的骨架数量控制,如果你用CPU蒙皮的话,这个选项的作用就很大,可以控制这个顶点到底由是多少个骨架影响,最终来实现那个运动。
第二个是vsync,vsync手机上一般都不会去开,因为虽然可以帮助画面不撕裂,但是会让帧数跌5帧以上,造成明显的卡顿。还有一点,我用比较多的是LOD Bia和Max LOD,这个我在后面会说到。包括Paticle 射线检测方面的这一块我会降到很低。
还有下面就是异步加载的时间切片,你使用脚本去调用资源相关的东西,这类东西的话,目前在我这个Demo里面没有使用。
先说说第一个,第一个其实就是LOD。

这个其实对应的是前面那个LOD Bias里面的。LOD有几种,第一个是显示模型,就是和显示相关的物件,一类是静态模型,一类是蒙皮模型,可以添加一个LODGroup的组件,有了这个之后,可以有多个模型,根据距离切换显示的等级,可能是越远越简单。通过LOD Bias可以控制这个系数。在最高配的机器上,可能50米以外才会切到第二个等级。
但是如果是非常差的设备,我会把这个系数传的非常小,在5米以外就变成另外一个模型了。对于Particle来说,这块同样是适用的,使用它的话,就把一个完整的Particle system切成不同的分类,使用这个LODGroup,你可以在近距离的时候,显示的是相对精简过的。
为什么与模型的方式不一样呢,这和overdraw相关。因为相对镜头最近的,比如说十米以内,不允许有很复杂的overdraw,必须很简单。10-50米之间,全效果,50米以后慢慢再精简,这样的方法可以让你的粒子在大部分的状态下显示出完整的效果。
但是这类方式也有一个问题,就是所有的这一类,换了LodGroup,必然有一个计算距离,有什么办法可以一劳永逸吗?有一个小技巧,这张图上写的,有一类叫decorations,纯装是的和这个游戏本身的关卡、结构没有必然的联系,一类东西。我把它全部放到一个节点上,在低配或者中配的情况下,把部分的节点关掉,下面所有的东西都关掉,就不要显示浪费性能了。
然后自己再写一点比较有扩展性的东西,我在这边,我把它扩展出了几类。
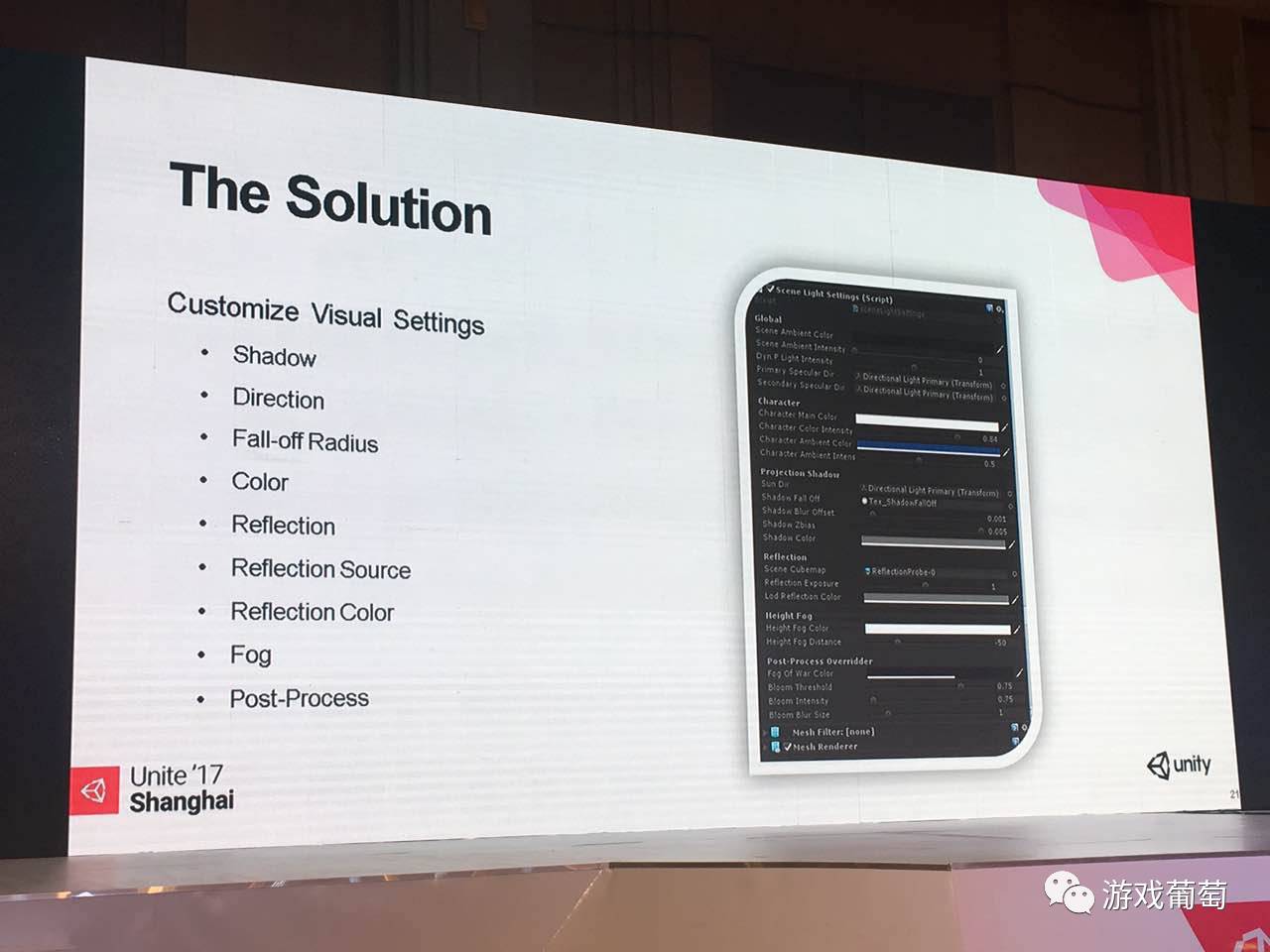
在游戏中,我们的人物比较小,它不是真实的,但是会拿一个灯光的方向,根据matcap来算出受光面和背光面的效果。就全局上来说,我会使用到场景里面的ambient,但是Unity的ambient会比较多一点变化,比较复杂,所以我们直接提出来,这样的话可以做到,在游戏中,在不同的区域,可以有不一样的效果,它们互相之间可以转换。
还有一类是shadow,因为我shadow完全重写,我的设置全部在这边。还有一个反射源,我会用Unity的reflection probes来生成出需要的资源,有时候会自己手动放一些cubemap在里面,在不同的区域,可以通过把这些做差值,计算出你到底是离哪一个点更近的混合的效果。比较简单的反射的,水面或者PBR都可以用到,基于顶点的也可以放在这儿。
还有这个面板是每个场景,都会有一个,当然也可以有多个,你只要放在那个,每个区域放一个,并且标记好位置,区域也是可以的。这样的话你在不同的位置,可能你全片滤镜是不一样,我这边还有一些全品滤镜的调整。
这边其实就是这边也要写LOD,这个语法很简单,就是利用Shader Lab中的一个LOD的标签。
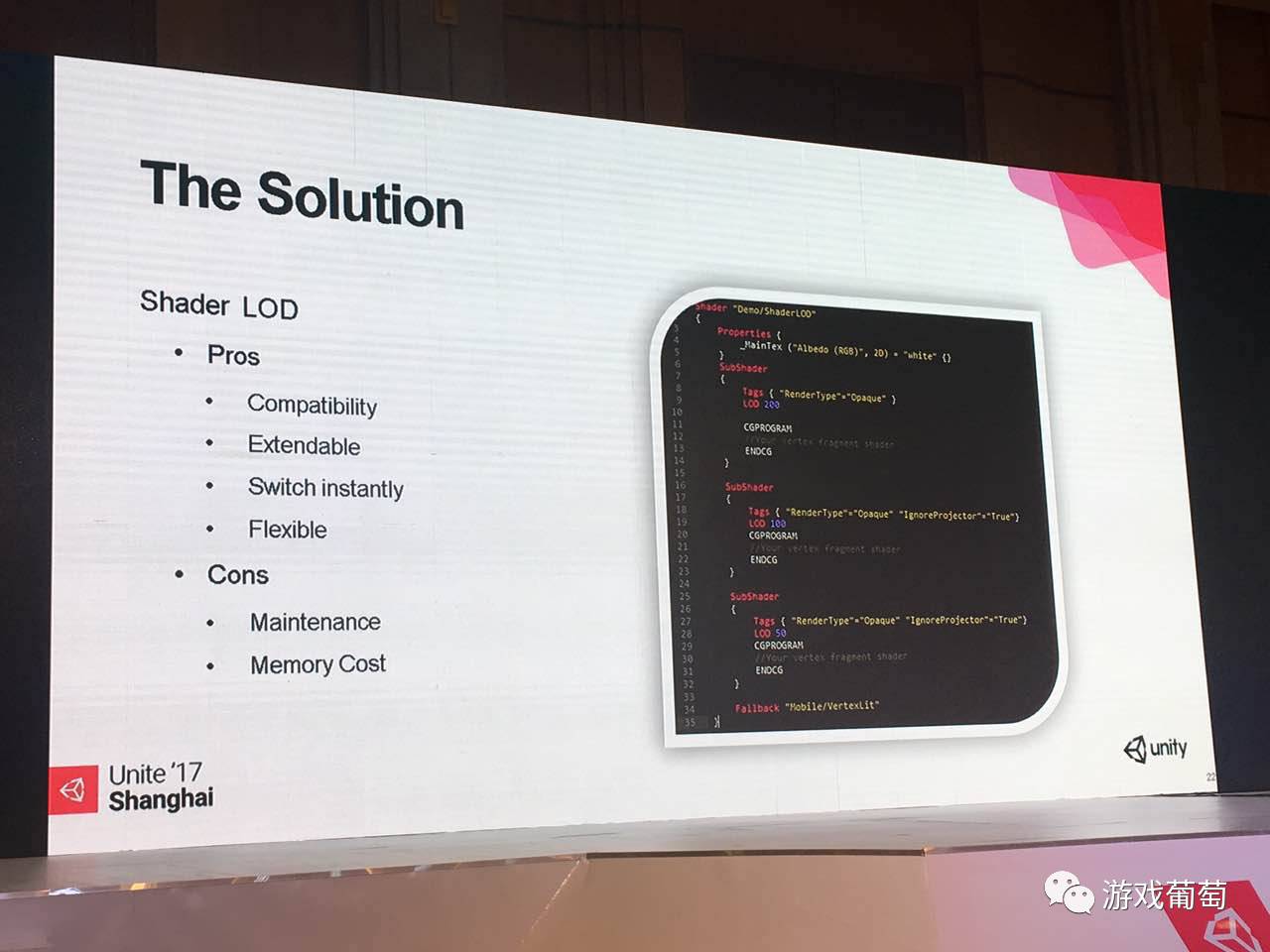

这个有很多好处,第一个是兼容性很高,兼容性有两方面。一方面是对于美术同学它的兼容性很高,不用高中低配,为了不同的模型指定不一样的模式。它只需要一个材质,这个材质自带LOD,你为这个材质所做所有变化,对于所有的低级的LOD都有意义。
第二种好处,因为这是Unity自带,所以Unity原生的shader都有标好了级别的,这个上官网,帮助里面都有,你可以和你的评估值对比,评估测试一下自己的shader,让你的消耗程度和他写的某种shader差不多,这样的话你的场景中,可以不需要全部自己写shader,一部分的用原生的,一部分用自定义的,就可以解决兼容性的问题。
第二个来说,非常容易扩展,因为LOD随便定,所以容易扩展。
第三个的话是切换很方便,切换其实就是用到了Max LOD。开始的时候,在quaity setting的面板中只要把中间那个max LOD的值改了就自动切换了,所以它很灵活。但是它也有缺点,缺点就是现在变的冗长,修改起来,一下子修改多个LOD,第二块来说,会稍稍多占一点内存。
这边其实很简单,就是提了一下,也可以用Script方式可以切换,所以含这些的,包括的物体,这类物体的Shader会变成另外一种状态。
但是有一点注意,因为写shader的时候经常会碰到一个兼容性问题。其实兼容性问题都来自于两点:是D3DLike还是OpenGlLike,
主要的不同点在于,一个是切线不一样,还有深度方向是相反的。然后数值的精确度,这种全精度、半精度类型等,可能某些Shader对数值精度会很敏感,千万注意这些问题。还有千万不要忽视PC,我一开始写这些东西,经常碰到的问题就是在真机上一切都OK,PC上会报错,因为Unity都是有支持的。那么它的shader在一个装了比较高版本directx(DX9以上)的PC上,那这个shader compiler是不一样的,会严苛很多。所以需要花更多的时间去维护。

最后的话,还有一些小的技巧上的东西,我觉得也很重要。
第一个是后期滤镜,一定要把后期滤镜的合并起来,因为Unity的标准资源包中包括了一部分。但就算用官方的,也是可以合并在一起,这样可以节省rendertexture的数量,提升在一帧中不同阶段的重用率,带宽占用也就少了一点。
第二,尽量使用Unity提供的宏。因为用了shader的LOD及宏控制,一定要放在Shader Variants的容器下,并且挂载到quality setting中,这些shader在一开始就被预加载,虽然内存多那么一点点,但是在游戏中不会卡顿。
还有就是要注意透明;以及在有可能的情况下,使用一些Culling的方式,自己写一些Culling给的方法,因为Unity都有开放接口,或者使用官方的occlusion culling。

这个就是Demo本身,这个屏幕很大,大家会看到影子是画两层,如果说放在一个非常高ppi设备上,这两层影子就变成软阴影,这本身是一个PBR材质的Demo,现在是最高级别,大家可以看到会有景深,会有bloom效果,还有PBR所有反射还有影子等等。
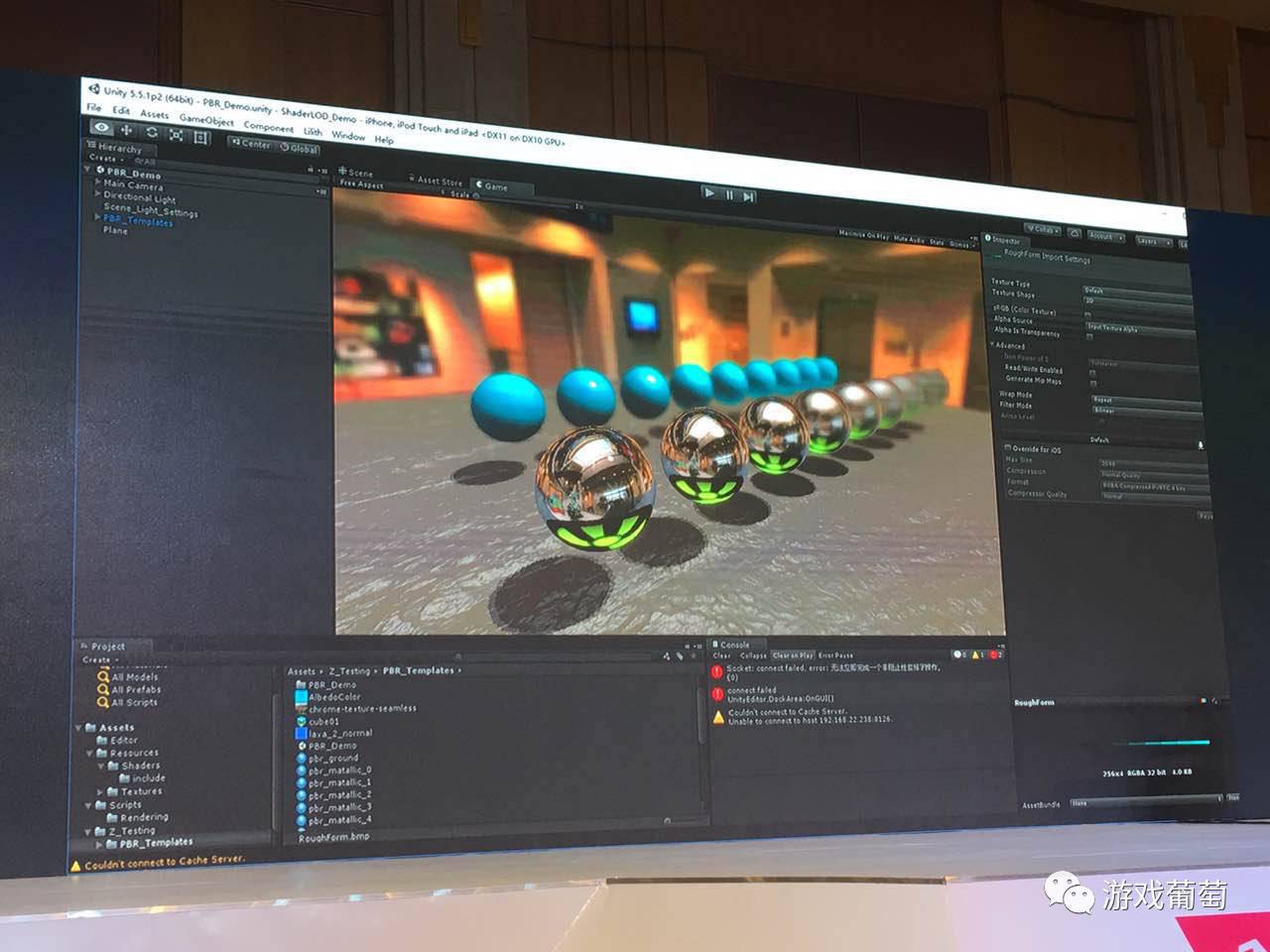
这是降一档,其他效果都还在,还有影子变成单层,法线贴图没有了。
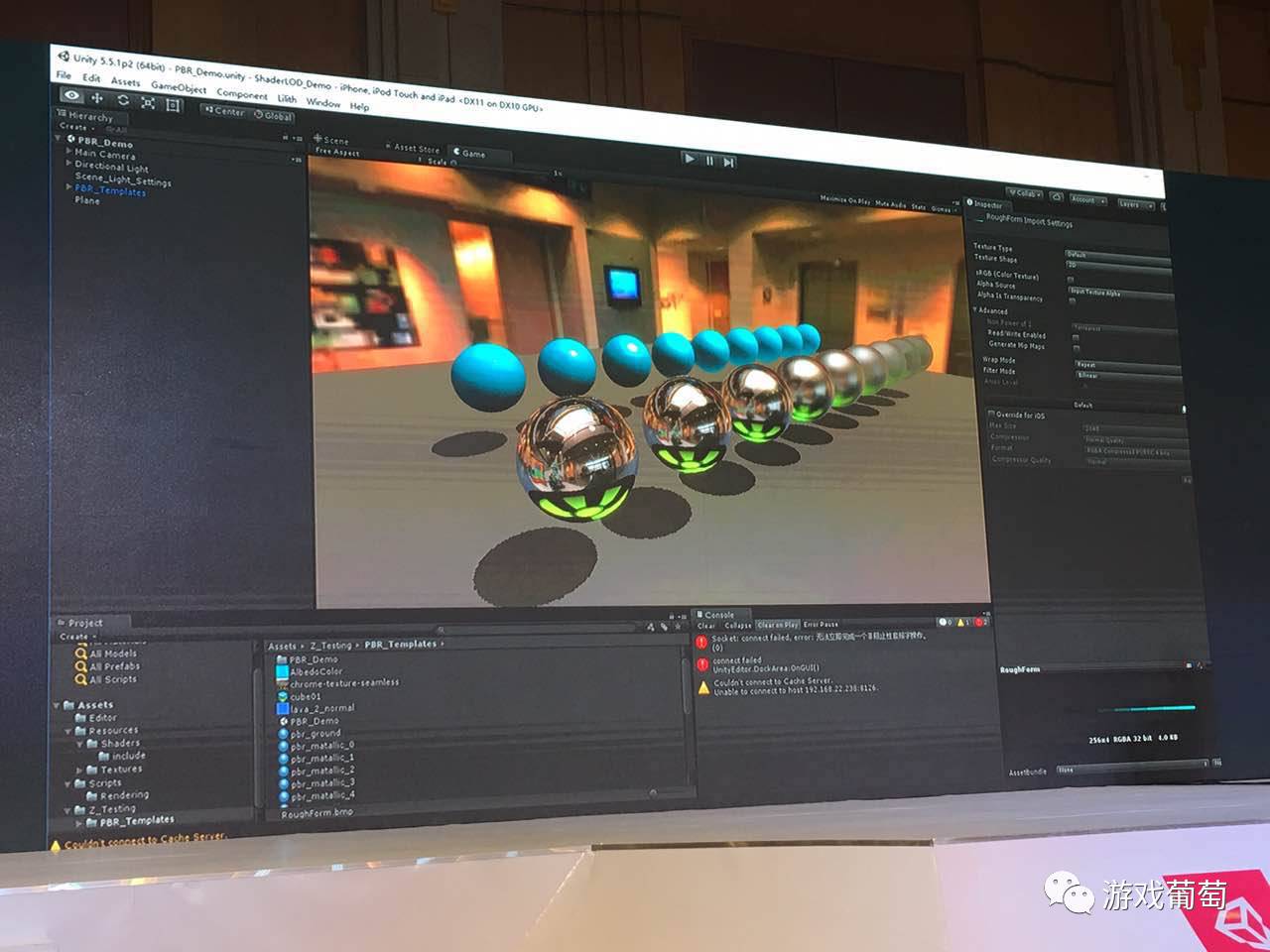
再降一档(我这边有意做的区别很大)反射没有了,变成这样了,然后后面那些塑料球的质感变化不大,影子变成不受你太阳光的角度控制,变成了垂直的,因为这样是最省的。
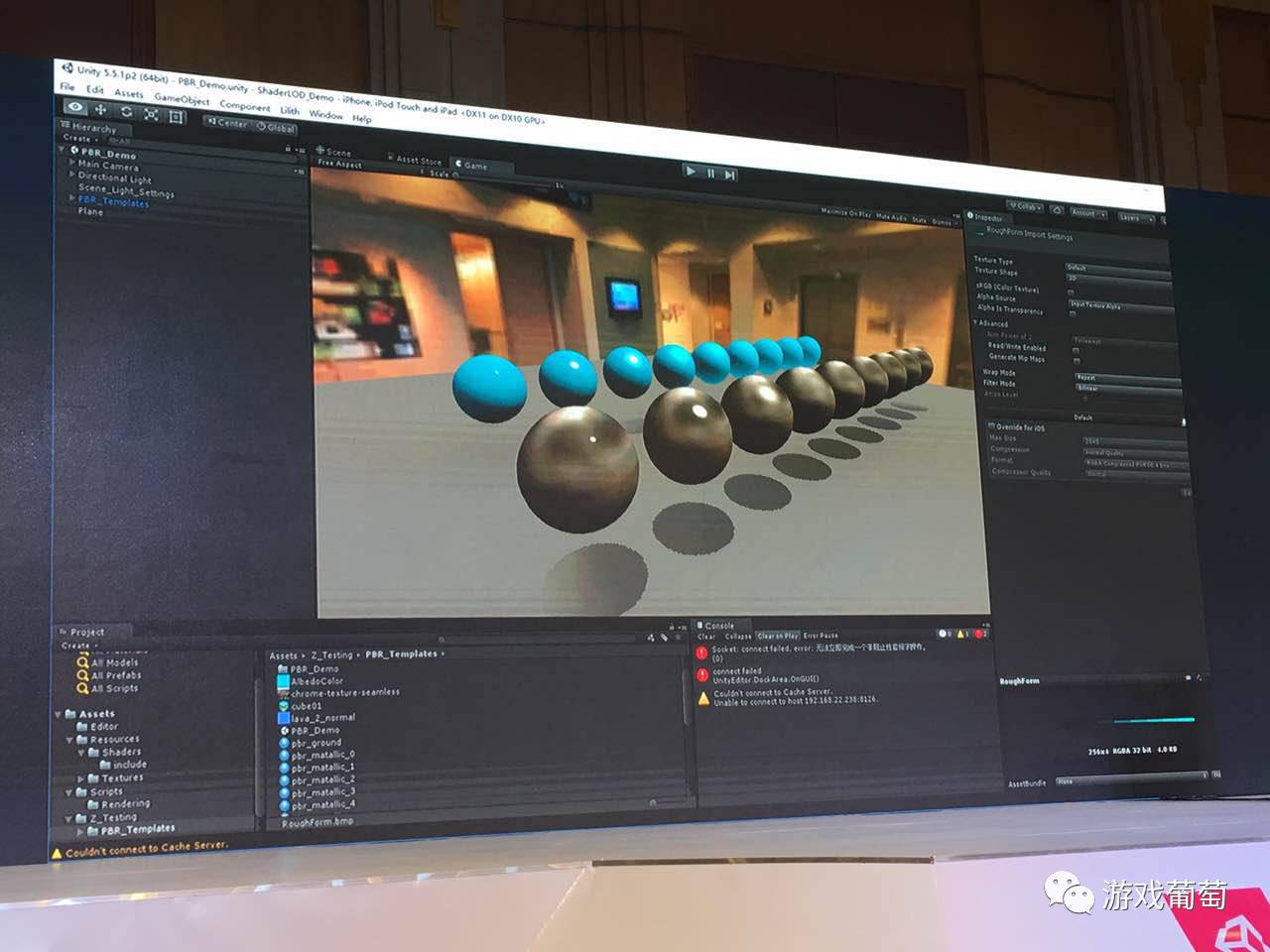
然后再往下,高光也没有了,影子也没有了。

再往下,只有顶点光和贴图。
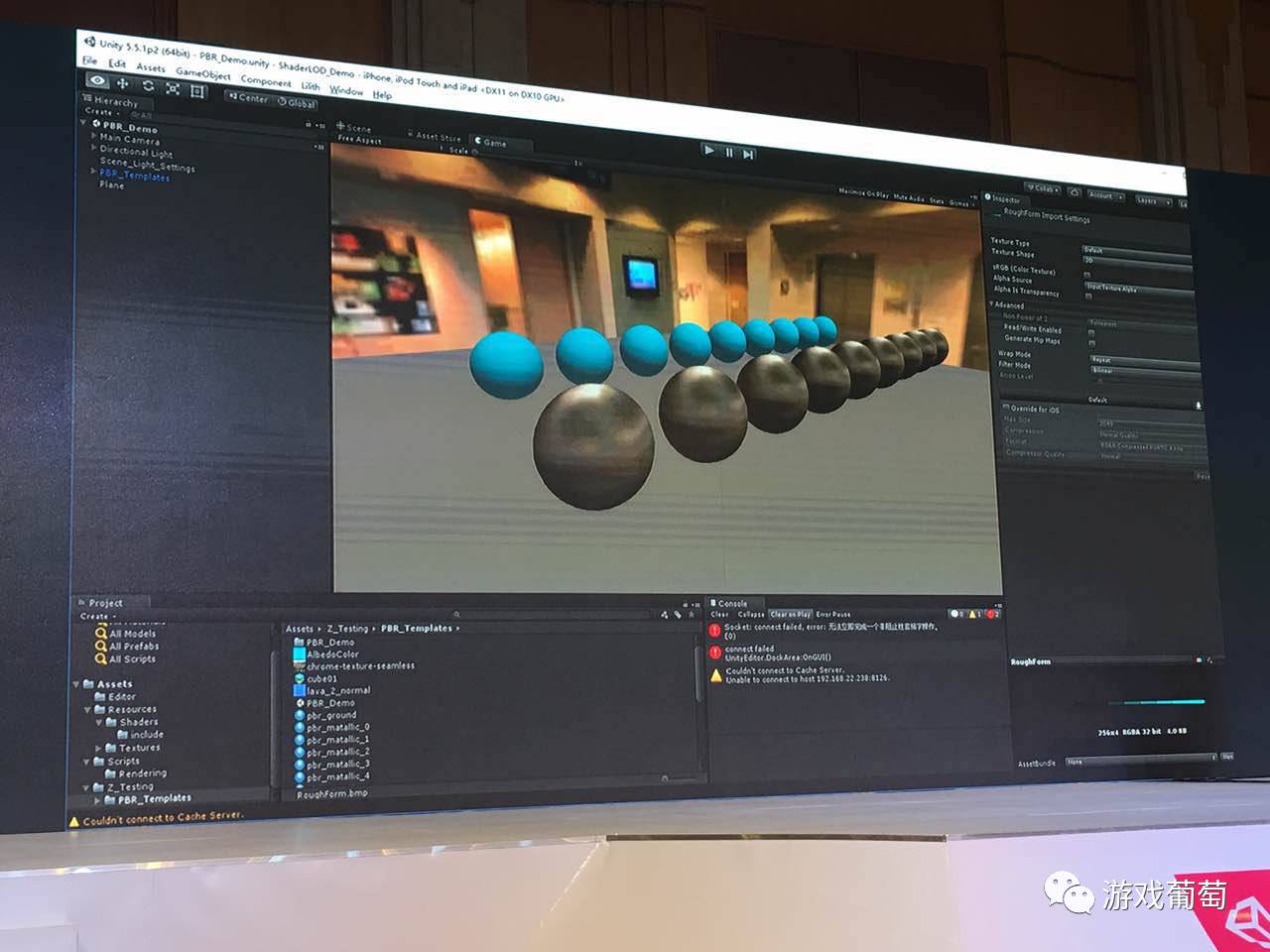
使用到相对比较实际的情况下,是这样,差距没有前面看到那个Demo那么大,这个是全效果。

往下,并且影子那边那辆赛车上只有影子,自投影和地面投影,都有一个影子:

再往下动态投影没有影子,并且反射关闭了,但是specular还是在:

再往下lightmap还在,其他东西没有了:

最后一级,是顶点光照,这些可以写成各种各样不一样的样子,可以做的就是会更好一些,或者说是差距再大一点都是有可能的。

今天我分享的内容就到这里,时间有限,谢谢。
关注微信公众号“游戏葡萄”,每天获取最前瞻的游戏资讯






