性能优化是代码中最大的威胁之一。
你可能在想,又有人在这么说了。我能理解。从字面意思可以明确地判断,任何类型的优化都是好事,所以你想把它学好是件很自然的事情。
不要脱离大家,认为自己是更好的开发者。不要避免变成日常
WTF 中的 “Dan”
,因为你相信代码优化是正确的事情(Right Thing to Do™)。在工作中你会为此喊到自豪。
计算机硬件越来越快,
软件
制作越来越容易,但任何你希望做到的简单的事情最后总是会花更长的时间,你因此而摇头(顺便说一句,这种现象称为 Wirth 定律),决心顺其自然。
你真是高尚,但别再这样了。
停止!

无论你在编程方面有多么丰富的经验,你这样做都是在严重阻碍自己的目标。
怎么会这样呢?让我们回到主题。
首先,什么是代码优化?
通常我们在定义它时,都假设我们希望代码有更好的性能。我们会说通过编写或重写代码,达到尽可能减少使用内存或磁盘空间,或最大限度减少 CPU 时间或网络带宽,或者尽可能少的使用额外核心的目的。
实际上,我们有时候会默认另一个定义:编写更少的代码。
但是以此为目标首先写出来的的代码往往成为别人的眼中钉。谁的眼中钉?可能是下一个需要理解你代码的倒霉蛋,甚至可能就是你自己。像你这样聪明能干的人其实可以避免自毁:保持目标,但重新评估你做事的方法,就算它们在表面看起来没有问题。

所以代码优化现在还是一个模糊的术语。我们会在下面考虑一些其它优化代码的方法。
我们先来听听高人的建议,一起探索
Jackson
有名的代码优化规则:
-
不要这样做。
-
(仅对专家而言!) 仍然不要这样做。
1. 不要这样做:引导完美主义
我要从一个相当尴尬的极端例子开始。很久以前的一段时光,我正在涉足精彩的、鱼与熊掌不可兼得的 SQL 世界。问题是,那时我踩到了蛋糕却再也不想吃掉它,因为它湿了并且开始闻起来像臭脚。

我正在涉足精彩的、鱼与熊站不可兼得的 SQL 世界。问题是,那时我踩到了蛋糕…

请稍等。让我从我打的这个比方中恢复过来,并解释一下。
那时我正在为一个内部网应用程序做研发,我希望将来有一天它能成为所工作的小公司的完全集成的管理系统。 它将为他们跟踪一切,而不像他们当时运行的系统,它不会丢失数据,因为它将由 RDBMS(关系型数据库管理系统)支持,而不是其他开发人员使用的不可靠的、自产的、扁平的文件。我想从一开始就把各种东西设计得尽可能智能,因为我有一块空白的石板。对于这个系统的想法在我的脑海中像烟花一样爆炸,我开始设计表 - 给客户关系管理(CRM)的联系人表和他们的许多上下文的变化的表,会计模块,库存,采购,内容管理系统(CMS),以及项目管理, 这个系统我很快就会自己试用。
所有这一切都停顿下来,朝开发和性能的方向,你猜对了,因为要优化。
我看到,对象之间(表示为表的行)在现实世界中可以有许多不同的关系, 我们可以从跟踪这些关系中获益:我们可以保留更多地信息,并最终将业务分析自动化到所有地方。鉴于这是一个工程问题,我做了一个似乎是对系统灵活性的优化。
在这一点上,重要的是要注意你的脸,因为我不会被追究责任,如果你的手掌打了你的脸。准备好了吗?我创建了两个表:relationship 及其有外键引用到的 relationship_type。relationship 可以指向整个数据库中的任意两行,并描述它们之间的关系的性质。
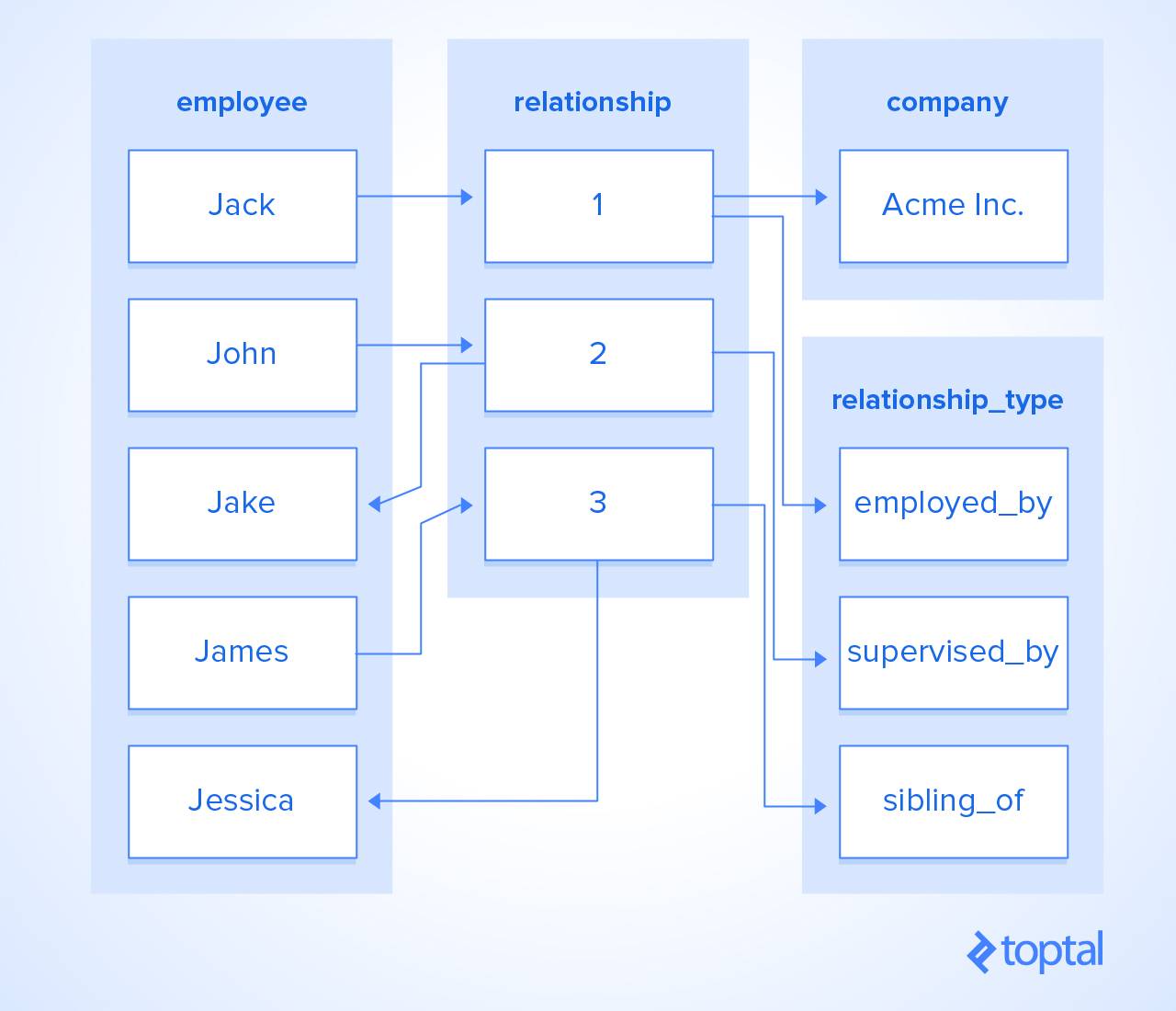
哦,伙伴!我刚刚优化了灵活性,该死地太多了。
实际上太多了。现在我有一个新问题:给定的 relationship_type 自然在每个给定的行组合之间都不会有意义。虽然一个人能通过与公司之间的雇用关系使得这变得有意义,但是这在语义上是绝对不能对等的。比如两个文档之间。
我们将只向 relationship_type 添加两列,指定可以应用哪个表。 (如果你已猜想我想通过将这两列移动到一个引用 relationship_type.id 的新表来实现这一点,那么给你加分,这样做可以在语义上应用于多个表的关系,而无需重复表名。因为如果我需要更改表名,但忘记在所有适用的行中更新,这会导致 Bug 的产生!后患无穷。)

幸运的是,在沿着这条路走了一段之后,我在一条线索风暴中被无意地打醒了。当我醒来时,我意识到我已经或多或少地设法重新实现了 RDBMS 的内部的外键相关表。通常,我喜欢在大功告成的时刻,大喊“我是超神了”,但遗憾的是,各位,这并不是我要说的优化方法之一。 忘记这个失败的设定——这个设定带来的膨胀差点毁了我的简单应用程序的后端,它的 DB 几乎没有任何测试数据,几乎不可用。

让我们退后一步,看看这里的许多衡量标准中的其中两个。一个是灵活性,这是我的既定目标。在这种情况下,我的优化本质上是建筑性的,甚至还不成熟:

(我将在我即将发表的文章中提到,“多云,有过早优化的机会”)然而,我的解决方案却因过于灵活而失败。另一个度量标准,可伸缩性,是我甚至还没有考虑过的,但这样至少免去了可能发生的附带的损害。
没错,“心好累”。

这对我来说是一个很好的教训,让我知道了优化是如何完全失败的。我的完美主义彻底崩溃:我的聪明使我产生了我所做过的最客观、最不明智的解决方案之一。
优化你的习惯,而不是代码
当你在拥有工作原型和测试套件以证明其正确性之前,倾向于重构,考虑下将这种冲动引导到其他方向。Sudoku 和 Mensa 是个不错的选择的,但也许一些实际上直接使你的项目受益的东西会更好:
-
安全性
-
运行时稳定性
-
清晰度和编码风格
-
编码效率
-
测试有效性
-
性能剖析
-
你的工具包/ DE
-
DRY(避免重复代码)
但要留意:优化这些特定任务之一都可能需要其他任务的代价来实现。至少,这是以时间为代价的。
在这里,很容易看到写代码中多少存在一点艺术。对于上述任何一种,我可以告诉你有关太多或太少被认为是错误选择的故事。谁在这里思考也是上下文的重要组成部分。
例如,关于 DRY:在一个工作中,我接手了至少 80% 冗余语句的代码库,因为它的作者显然不知道如何和何时写一个函数。其他 20% 的代码是令人困惑的自相似。
我的任务是增加一些功能。在所有要实现的代码中都需要重复一个这样的功能,并且未来的任何代码将必须仔细的复制以利用新功能。
显然,只有为了我自己的头脑清楚(高价值)和任何未来的开发者才需要去进行重构。但是,因为我是将新的代码加入代码库,我首先写了测试,进行回归测试,以确保我任何的重构没有问题。事实上,只是这样做:我遇到两个错误,我不会注意到生成所有冗繁而费解的脚本输出。
最后,我以为我做得很好。在重构之后,我用一些简单的代码行实现了被认为是一个难点的功能,使我的老板印象深刻。而且,程序性能总体上提高了一个数量级。但不久之后,同一位老板告诉我,我进度太慢了,而且这个项目应该早就完成了。(潜台词:编码效率是优先考虑的问题。)
注意:优化任何特定的[方面]将以牺牲其他方面为代价。至少,这是以时间为代价的。
我仍然认为我的选择是正确,即使当时代码优化没有得到老板的赞赏。没有重构和测试,我想事实上可能要花更长的时间才能找到正确的路,也就是说,专注于编码速度实际上会阻碍它的发展。(嘿,那是我们的主题!)
与我在我做过的一个小型项目工作相比。在项目中,我尝试了一个新的模板引擎,并希望从一开始就养成良好的习惯,尽管尝试新的模板引擎并不是项目的最终目标。
我注意到,我添加的几个代码区域非常相似,而且每个区域需要指向同一个变量三次,DRY警铃在我的脑海中响起,我开始试图用模板引擎来找到正确的方法做事情。
事实证明,经过几个小时的无结果的调试之后,我发现这个模板引擎不可能像我想象的那样。不仅没有完美的解决DRY;根本没有任何一个解决方案!
我试图调整自己的价值观,我完全破坏了我的编码效率和幸福感,因为这条弯路导致我的项目花费了我那天可能取得的进步。
即使这样,我完全错了吗?有时,值得一点投资,特别是在新的技术背景下,要更早地了解最佳实践,而不是稍后。减少代码重写和撤销的坏习惯,对吧?
不,我认为即使在我的代码中寻找减少重复的方法也是不明智的,这与我在以前的处事中的态度形成了鲜明的对比。原因是场景是一切:我在一个小型项目中探索一个新的技术,而不是长期解决。一些额外的线路和代码重复不会伤害任何人,但失去专注,伤害了我和我的项目。
等等,所以寻求最佳做法可能是一个坏习惯?有时。如果我的主要目标是学习新的引擎,或者普通的学习,是很花费的时间的:修修补补,找出约束,通过研究发现不相关的功能和问题。但我忘了这不是我的主要目标,这让我付出了代价。
这是一种艺术,就像我说的。而这种
开发的艺术
受益于提醒,不要这样做。至少让你考虑在工作时有哪些是有的价值,在你的工作场景中哪些又是最重要的。
那第二条规则呢?什么时候才能够进行优化?
2. 不要这么做了:有人已经做过这些了
好的,无论是你还是别人,当架构被设置好,数据流被考虑清楚并文档化,就可以开始编码了。
让我们把"不要这么做"扩展下:不要进行编码。
这听起来像是提前优化,但和别的优化不一样,这个非常重要。是为了避免可怕的 NIHS 或“Not Invented Here”综合征 - 假设你的优先级包括代码性能和最小化开发时间。如果没有,如果你的目标完全以学习为导向的话,可以跳过下一节。
有人会自以为是地重新发明方形车轮,就算像你我一样的诚实谦虚的人,也会因为认识的不全面而犯这样的错误。了解堆栈中每个 API 和工具的每个选项,并且随着它们的发展深化知识,做到与时俱进,这当然是需要很多工作的。但是,这段时间的投入能帮你成为这个领域的专家,让你避免像 CodeSOD 上的人一样,做各种无用的尝试。
检查标准库,框架生态系统,以及那些已经解决了你的问题的自由和开源软件
有可能,您所处理的概念具有相当的标准和众所周知的名称,因此快速的互联网搜索可以节省大量的时间。
例如,我最近正在准备对棋盘游戏的 AI 策略进行一些分析。我早上醒来就意识到,如果我使用一些我记得的组合概念,我计划的分析可以更快地达到效果。在这个时候我自己并没有意识到这个概念的算法,但我已经知道正确的名字,并去搜索。 不过,经过大约 50 分钟的研究和一些初步代码的尝试,我发现我并没有把我这些半成品伪代码正确地实现。(有一个博客文章,那个作者假定算法有着不正确的输出,实现的算法不能正确的匹配假设情况,评论者也指出了这一点,然而多年后,问题解决否?)那时,我戒除了早茶,我搜索[我的编程语言]的概念名称。30 秒后,我找到了 GitHub 上的正确代码,然后还是行动。一切都要具体化,包括具体的语言,而不是对计划做出假设。
花时间来设计数据结构和实现算法

如你所见,这样并没有解决你使用的工具链中的内置问题,也没有在网络上获得使用许可。你需要有自己的方案。
参考建议如下:
简单性,某些情况下很难去遵循。这就是编码习惯和
代码风格
、艺术和
工艺
以及优雅的魅力所在。 在这一点上,你正在做的工作显然是从工程角度来看的,但再次强调,不要玩代码高尔夫。在实际项目中将正确性和清晰度放到高优先级。
如果你喜欢视频,
有人按照以上步骤进行了演示
。不喜欢看视频的人,我就用语言简单概述一下:这是一个在谷歌求职面试中的算法编码测试。面试者首先以易于沟通的方式设计算法。在编写任何代码之前,都会设计所期望的输出示例,然后代码自然地跟随输出。
至于测试本身,我知道在某些圈子里,测试驱动的开发可能会引起争议。我认为部分原因是它太火了,花了大量时间开发以追求极致。(我们试图从一开始将一个变量优化到最佳,以至于搬起石头砸了自己的脚)
即使 Kent Beck 也不会把 TDD 用到如此极端
,尽管是他发明了极限编程,还撰写了那本关于 TDD 的书。所以从简单的东西开始,确保你的输出是正确的。毕竟,你无论如何都会手动编码,不是吗?(如果你是“编程高手”,写完代码之后都不会再运行一遍,那你应该让之后的代码维护者进行一下测试,以免他们打破你厉害的代码实现。 )所以与其进行手动的、可视的文本比较,不如预备一份测试代码,让计算机代替你执行。
在机械化实现算法和数据结构的过中程,要避免进行逐行的优化,也别使用可自定义的低级语言的全局变量声明(extern) (如果你用 C 编码,那就是汇编,如果你用 Perl 编码,那就是 C 了,以此类推。) 。理由很简单:如果你的算法完全被替换了,你要在这个过程的后期才会发现它是否需要,那么你的低级优化工作最终就没有效果了。
一个 ECMAScript 示例
在优秀社区代码评审站点 exercism.io
, 我最近发现
一个练习题
,建议为重复数据删除或清晰度尝试进行优化。 我进行重复数据删除优化,只是为了证明如果你进行 DRY(Don't Repeat Yourself)事情会变得多么可笑。不然的话,DRY 是一种有益的心态,正如我前面提到的。扯太远了,下面是我的代码的样子:
const zeroPhrase = "No more";
const wallPhrase = " on the wall";





