
MySQL支持了很多Charset与Collation,并且允许用户在连接、Server、库、表、列、字面量多个层次上进行精细化配置,这有时会让用户眼花缭乱。本文对相关概念、语法、系统变量、影响范围都进行了详细介绍,并且列举了有可能让字符串发生字符集转换的情况,以及来自不同字符集的字符串进行比较等操作时遵循的规则。对于最常用的基于Unicode的字符集,本文介绍了Unicode标准与MySQL中各个字符集的关系,尤其详细介绍了当前版本(8.0.34)默认字符集utf8mb4。
在你使用MySQL的时候,有没有遇到过字符串出现乱码的情况?想查一个英文字符串结果查出来了特殊字符?字符串排序有时小写在前有时大写在前?如果在使用MySQL时不在意字符集、Collation等相关配置,那么就可能会碰到这些问题,本文将以几个例子作为开篇。
一个客户端的错误配置,可能导致字符串二进制存储错乱,并且导致其他正常客户端查询出现乱码,如下:
-- 1.创建表t1,有两列,一列使用utf8mb4字符集,
-- 一列使用latin1字符集
mysql> create table t1
(a char(5) character set utf8mb4,
b char(5) character set latin1);
-- 2.客户端实际使用utf8mb4字符集,
-- 这里模拟客户端在服务端错误配置,并插入数据
mysql> set names latin1;
-- 哪怕列b的latin1字符集没有字符'张'也能成功插入,
-- 正常情况下都无法插入该列,从这里就开始出错了
mysql> insert into t1 values('张','张');
-- 3.正常客户端查询数据
mysql> set names utf8mb4;
-- a列(utf8mb4字符集)内容完全错乱,
-- b列(latin1字符集)内容竟是'张'的utf8mb4编码
mysql> select a,hex(a),b,hex(b) from t1;
+--------+--------------+--------+--------+
| a | hex(a) | b | hex(b) |
+--------+--------------+--------+--------+
| å¼ | C3A5C2BCC2A0 | å¼ | E5BCA0 |
+--------+--------------+--------+--------+
用等值条件查询字符串列时,多返回了一个完全不同的字符串,难道MySQL出Bug了?其实不是的,字符串的比较和Collation配置息息相关,稍不注意就可能得到令人费解的结果。
-- 1.创建表t1,包含一列,默认使用utf8mb4字符集
-- 和utf8mb4_0900_ai_ci Collation
mysql> create table t1 (a char(5));
-- 2.插入两行数据
mysql> insert into t1 values ('ß'),('ss');
-- 3.按等值条件查询该表,结果编码完全不同的两个字符串都返回了!
mysql> select a,hex(a) from t1 where a='ss';
+------+--------+
| a | hex(a) |
+------+--------+
| ß | C39F |
| ss | 7373 |
+------+--------+
-- 4.换一个Collation试试,又正常了
mysql> select a,hex(a) from t1
where a='ss' collate utf8mb4_0900_as_cs;
+------+--------+
| a | hex(a) |
+------+--------+
| ss | 7373 |
+------+--------+
下面这个例子展现了Collation对于字符串排序的影响,怎么有时候是小写优先,有时候是大写优先,不同字符串的先后顺序是怎么确定的?这都是配置的Collation决定的。
-- 1.创建表t1,包含一列,默认使用utf8mb4字符集
-- 和utf8mb4_0900_ai_ci Collation
mysql> create table t1 (a char(5));
-- 2.插入两行数据
mysql> insert into t1 values ('abc'),('ABC');
-- 3.返回字符串排序结果,小写优先
mysql> select * from t1 order by a;
+------+
| a |
+------+
| abc |
| ABC |
+------+
-- 4.换一个Collation,成大写优先了
mysql> select * from t1
order by a collate utf8mb4_0900_bin;
+------+
| a |
+------+
| ABC |
| abc |
+------+
通过上面3个例子可以看出,我们在MySQL中使用字符串时,字符集和Collation是非常重要的配置项,一旦配置错误就可能无法按照预期进行使用。当我们在使用MySQL查看表定义时,经常可以看到如下例所示的CHARSET、COLLATE等字眼,所以相信大家对于这些字眼并不陌生。然而但很多时候我们并不清楚这些字符集、Collation的具体含义,也不知道究竟如何配置才好,要么跟着默认配置走,要么从已有库表的定义那里copy过来,但是这些“祖传配置”真的适合当前的应用么?合理地选择字符集、Collation、了解字符串如何比较将能很大程度上帮我们避免前文例子中所描述的问题,因此本文就将对此展开介绍,希望能对你有帮助。
mysql> show create table t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`a` char(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`b` varchar(10) CHARACTER SET latin2 COLLATE latin2_general_ci DEFAULT NULL,
`c` char(10) COLLATE utf8mb4_0900_as_cs DEFAULT NULL,
`d` char(5) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`e` varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_as_cs
MySQL8.0本身支持很多种字符集(Character Set)与Collation,本身的配置有时候令用户眼花缭乱,本文就将围绕它们由浅入深进行介绍,希望能够回答以下几个问题:
本文将分为两部分进行介绍,组织结构如下:
第一部分(概念介绍与MySQL的配置项)
第二部分(字符集转换与Unicode、Binary字符集的排序算法)
字符集(Charset)和Collation是什么?
字符集(Character Set)是一组符号和编码。Collation是一组用于比较字符集中字符的规则。让我们以MySQL-8.0默认的utf8mb4字符集和utf8mb4_0900_ai_ci Collation为例,明确这个区别。下表是六个字符在utf8mb4字符集中的编码,utf8mb4字符集允许字符的编码是非定长的,长度可以是1~4 bytes,具体的编码方式将在“Unicode与UTF-8”章节介绍。
| 字符 | utf8mb4 编码 |
| E | 0x45 (1 byte) |
| a | 0x61 (1 byte) |
| e | 0x65 (1 byte) |
| ắ | 0xe1baaf (3 bytes) |
| ế | 0xe1babf (3 bytes) |
| 𝔸 | 0xf09d94b8 (4 bytes) |
上面就可以当作一个字符到编码的映射,也就是字符集。字符集的作用是提供字符到编码的映射,但是不定义字符之间的比较关系,而这一部分工作就是由Collation定义的。
对于上面6个字符,如果我们仅看二进制编码对应的数值大小进行比较那么它们的大小关系就是“ECollation,在MySQL中以“_bin”结尾。但是很多时候,我们希望不论大小写,a都应该排在e和E前面,对于欧洲一些语言或者中文拼音来说,不论字母上面有没有音调符号,a也应该排在e前面,于是更加精细的Collation就应运而生,它包含了很多契合人类语言习惯的规则定义。比如上面例子中6个字符在utf8mb4_0900_ai_ci Collation看来,它们的大小关系是“a=ắ=𝔸Collation里,所有字符都忽略了音调、大小写再进行比较,这就比二进制Collation复杂了一些。
上面只是用utf8mb4字符集中的6个字符举了个例子,实际上其内几乎包含了世界上各个语言的文字,这些字符之间的定制化比较规则将更加复杂,不光是音调、大小写,有时还会有多字符映射(例如utf8mb4_0900_ai_ci中 ß = ss)。为此Unicode专门定义了字符串比较算法,解释了如何进行字符的比较,MySQL也是据此实现的自己的比较算法,这一部分将在“Unicode字符串比较算法”详细介绍。
从上面的描述我们可以看出,字符集是符号到编码一一映射的集合,一组Collation是对字符进行比较的一系列规则,一个字符集上可以有很多组Collation。为方便描述,后文使用Charset代表字符集。
查看MySQL支持的Charset和Collation
MySQL支持了很多种Charset[1]以及Collation,可以使用如下语句查看支持的Charset,其中Charset列代表字符集的名称、Description列代表描述、Default collation列代表该字符集的默认Collation、Maxlen列代表该字符集中最长编码的字节数:
-- 对应视图INFORMATION_SCHEMA.CHARACTER_SETS
mysql> SHOW CHARACTER SET;
+---------+--------------------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+--------------------------+--------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| binary | Binary pseudo charset | binary | 1 |
...
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
...
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
...
| utf8mb3 | UTF-8 Unicode | utf8mb3_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
...
MySQL-8.0默认使用的Charset是utf8mb4,这里以它为例使用如下语句查看该字符集可以使用的Collation,其中Compiled列代表该Collation是否在MySQL源码中实现:
mysql> SHOW COLLATION WHERE Charset = 'utf8mb4'; -- 对应视图INFORMATION_SCHEMA.COLLATIONS
+------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
...
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 | PAD SPACE |
...
| utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 | PAD SPACE |
...
| utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 | PAD SPACE |
...
| utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD |
+----------------------------+---------+-----+---------+----------+---------+---------------+
在MySQL中,Charset和Collation遵循以下规则:
查看Collation信息时可以发现有一个Pad_attribute列,其值为“NO PAD”或“PAD SPACE”,这定义了Collation对待字符串尾部空格的态度。MySQL中大部分Collation该属性为“PAD SPACE”,基于UCA 9.0.0(名称中带0900字样)实现的Collation该属性为“NO PAD”:
mysql> SELECT COLLATION_NAME, PAD_ATTRIBUTE
FROM INFORMATION_SCHEMA.COLLATIONS
WHERE COLLATION_NAME LIKE 'utf8mb4%bin';
+------------------+---------------+
| COLLATION_NAME | PAD_ATTRIBUTE |
+------------------+---------------+
| utf8mb4_bin | PAD SPACE |
| utf8mb4_0900_bin | NO PAD |
+------------------+---------------+
-- 1. 具有'PAD SPACE'属性的utf8mb4_bin认为'a ' = 'a'
mysql> SELECT 'a ' = 'a' COLLATE utf8mb4_bin;
+--------------------------------+
| 'a ' = 'a' COLLATE utf8mb4_bin |
+--------------------------------+
| 1 |
+--------------------------------+
-- 2. 具有'NO PAD'属性的utf8mb4_0900_bin认为'a ' != 'a'
mysql> SELECT 'a ' = 'a' COLLATE utf8mb4_0900_bin;
+-------------------------------------+
| 'a ' = 'a' COLLATE utf8mb4_0900_bin |
+-------------------------------------+
| 0 |
+-------------------------------------+
-- 3. LIKE操作符不受'PAD SPACE'影响,尾部空格不可忽略
mysql> SELECT 'a ' LIKE 'a' COLLATE utf8mb4_bin;
+-----------------------------------+
| 'a ' LIKE 'a' COLLATE utf8mb4_bin |
+-----------------------------------+
| 0 |
+-----------------------------------+
Collation名称以其关联的Charset名称开头,通常后面跟着一个或多个后缀,表示其他特征。例如,utf8mb4_0900_ai_ci和latin1_swedish_ci分别是utf8mb4和latin1的Collation。Binary Charset只有一个Collation,也命名为binary,没有后缀。
对于特定语言的Collation包括一个区域代码或语言名称。例如,utf8mb4_tr_0900_ai_ci和utf8mb4_hu_0900_ai_ci中的_tr和_hu分别代表使用土耳其语和匈牙利语的规则对utf8mb4中的字符进行排序。
Collation后缀表示是否区分大小写、音调、平(片)假名,或者是二进制的,下表显示了用于表示这些特征的后缀。如果Collation名称中不包含_ai或_as,则名称中的_ci隐喻着_ai(例如utf8mb4_unicode_ci既不区分音调也不区分大小写),名称中的_cs隐喻着_as(例如latin1_general_cs既区分音调也区分大小写):
| 后缀 | 含义 |
| _ai | 不区分音调,例如认为'a' = 'á' |
| _as | 区分音调,例如认为'a' != 'á' |
| _ci | 不区分大小写,例如认为'a' = 'A' |
| _cs | 区分大小写,例如认为'a' != 'A' |
| _ks | 区分平假名、片假名,日语使用 |
| _bin | 二进制编码对比 |
Unicode字符集的Collation名称可能包括版本号,以表示Collation基于哪个版本的Unicode排序算法(UCA,后文会详细介绍)。名称中不含版本号的Collation则默认基于4.0.0版本的UCA。例如:
• utf8mb4_0900_ai_ci基于UCA 9.0.0[2]
• utf8mb4_unicode_520_ci基于UCA 5.2.0[3]
• utf8mb4_unicode_ci基于UCA 4.0.0[4]
为了便于阅读后文,这里先介绍一下Unicode[5]标准和UTF-8[6]编码。
Unicode标准由非盈利组织Unicode联盟[7]维护,致力于整理和编码世界上大部分文字系统。Unicode标准当前最新版为2022年9月发布的15.0.0版本,收录超过14万字符,每个字符都被分配了独一无二的码点(数值编号)。Unicode已经成为ISO国际标准的一部分,最常见的Unicode编码格式有与ASCII兼容的UTF-8和与UCS-2兼容的UTF-16。
Unicode标准将编码空间划分为17个平面,编号从0到16,其中第0平面称为基本多文种平面(BMP,U+0000到U+FFFF),而第1到16平面被称为辅助平面(U+10000到U+10FFFF),这些平面与BMP平面一起至少需要21bit的编码空间,略少于3个字节。BMP平面的码点可以使用单个UTF-16编码单位(2字节)表示,或者使用1~3个字节的UTF-8进行编码;辅助平面的码点在UTF-8中使用4个字节进行编码,在UTF-16中使用4个字节进行编码。
出于节省空间等目的,实际上对Unicode标准进行编码有不同实现方式,Unicode的实现方式被称为Unicode转换格式(Unicode Transformation Format,简称为UTF),最常见的当属UTF-8编码,其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示)等,下面给出一些示例:
| 字符 | Unicode码点 | UTF-8编码 |
| a | 0x0061 | 0x61 (1 byte) |
| ắ | 0x1EAF | 0xe1baaf (3 bytes) |
| 𝔸 | 0x1D538 | 0xf09d94b8 (4 bytes) |
可以看出Unicode给字符分配的原始码点(编号)和UTF-8具体编码还是有很大不同的,这是因为UTF-8编码以8bit(1字节)为单位对Unicode字符进行变长编码,具体转换规则如下表所示(单元格内首行为16进制表示,次行为2进制表示):
| Unicode码点范围(3字节可表示) | UTF-8编码 | 注释 |
0x000000 - 0x00007F
00000000 00000000 0zzzzzzz | 0x00 - 0x7F
0zzzzzzz | ASCII字符范围,1字节 |
0x000080 - 0x0007FF
00000000 00000yyy yyzzzzzz | 0xC080 - 0xDFBF
110yyyyy 10zzzzzz | 第1个字节由110开始,第2个字节由10开始,共2字节 |
0x000800 - 0x00D7FF
0x00E000 - 0x00FFFF
00000000 xxxxyyyy yyzzzzzz | 0xE08080 - 0xEFBFBF
1110xxxx 10yyyyyy 10zzzzzz | 第1个字节由1110开始,第2-3个字节由10开始,共3字节 |
0x010000 - 0x10FFFF
000wwwxx xxxxyyyy yyzzzzzz
| 0xF0808080 - 0xF7BFBFBF
11110www 10xxxxxx 10yyyyyy 10zzzzzz | 第1个字节由11110开始,第2-4个字节由10开始,共4字节 |
可以看出转换规则其实很直观,就是把Unicode码点对应的数值用3个字节存下来(最多用21个bit),然后根据自己所处的范围将bit位依次填入UTF-8对应空位即可。
汉字的码点空间[8]如下。utf16对于BMP平面字符(在下表中Unicode码点仅需两字节的部分)会使用2字节编码,而utf8对于BMP平面的汉字需要使用3字节编码,非BMP平面的汉字utf16和utf8都需要4字节编码。所以如果存储字符基本都是汉字时,utf16字符集的编码长度始终优于或等于utf8字符集的编码长度,可以有效帮助减少存储空间,最多减少1/3的存储空间。
| 字符集 | 字数 | Unicode码点 |
| 基本汉字[9] | 20902字 | 4E00-9FA5 |
| 基本汉字补充[10] | 38字 | 9FA6-9FCB |
| 扩展A[11] | 6582字 | 3400-4DB5 |
| 扩展B[12] | 42711字 | 20000-2A6D6 |
| 扩展C[13] | 4149字 | 2A700-2B734 |
| 扩展D[14] | 222字 | 2B740-2B81D |
| 康熙部首[15] | 214字 | 2F00-2FD5 |
| 部首扩展[16] | 115字 | 2E80-2EF3 |
| 兼容汉字[17] | 477字 | F900-FAD9 |
| 兼容扩展[18] | 542字 | 2F800-2FA1D |
| PUA(GBK)部件[19] | 81字 | E815-E86F |
| 部件扩展[20] | 452字 | E400-E5E8 |
| PUA增补[21] | 207字 | E600-E6CF |
| 汉字笔画[22] | 36字 | 31C0-31E3 |
| 汉字结构[23] | 12字 | 2FF0-2FFB |
| 汉语注音[24] | 22字 | 3105-3120 |
| 注音扩展[25] | 22字 | 31A0-31BA |
| 〇[26] | 1字 | 3007 |
MySQL内支持Unicode标准的Charset
MySQL支持多种Unicode Charset:
- • utf8mb4:使用一到四个字节表示每个字符的Unicode字符集的UTF-8编码。
- • utf8mb3:使用一到三个字节表示每个字符的Unicode字符集的UTF-8编码,仅支持表示基本多文种平面(BMP)。在MySQL 8.0中,这个字符集已被deprecated,应该尽快改用utf8mb4。
- • utf8:utf8mb3的别名。在MySQL 8.0中,这个别名已被deprecated,应改用utf8mb4。预计在未来的版本中,utf8将成为utf8mb4的别名。
- • ucs2:使用两个字节表示每个字符的UCS-2编码,仅支持表示基本多文种平面(BMP)。在MySQL 8.0.28中已被deprecated,预计在未来的版本中将被移除。
- • utf16:使用两个或四个字节表示每个字符的UTF-16编码,类似于ucs2,但包含了对补充辅助平面的扩展。
- • utf16le:类似于utf16,但是小端序而不是大端序。
- • utf32:使用四个字节表示每个字符的UTF-32编码。
使用show variables命令可以很方便地查看相关变量:
mysql> show variables like "character\_set\_%";
+--------------------------+---------+
| Variable_name | Value |
+--------------------------+---------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |
+--------------------------+---------+
mysql> show variables like "collation%";
+-------------------------------+--------------------+
| Variable_name | Value |
+-------------------------------+--------------------+
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_0900_ai_ci |
+-------------------------------+--------------------+
MySQL之所以有这么多和Charset相关的变量,是因为这些变量将在不同维度上起作用。这些系统变量中最重要的是跟连接相关的几个变量:character_set_client、character_set_results、character_set_connection、collation_connection,将在后面“配置连接”小节中详细介绍。剩余几个变量的含义如下:
- • character_set_server和collation_server:如果在CREATE DATABASE语句中没有指定DATABASE的Charset和Collation,则该DATABASE默认Charset和Collation就是character_set_server和collation_server,它们没有其他用途。
- • character_set_database和collation_database:该组变量其实是用于展现当前所在DATABASE(通过use db_name切换)的默认Charset和Collation,由数据库本身进行设置,切换DATABASE时这两个变量会跟着变化。当没有use某个DATABASE的时候,这一对变量和character_set_server、collation_server的值相同。因此可以发现该组变量其实是用于展示信息的,虽然还是可以被用户修改,但不建议使用,从8.0.14开始只有有权限的用户才能修改,未来版本会变成read only的变量。
- • character_set_filesystem:此变量用于涉及文件路径的字符串字面量,例如在LOAD DATA和SELECT ... INTO OUTFILE语句以及LOAD_FILE()函数中。这类文件名会在尝试打开文件之前,从character_set_client转换为character_set_filesystem。默认值是binary,这意味着不进行转换。如果文件系统使用某种编码例如UTF-8表示文件名,则应将character_set_filesystem设置为utf8mb4。
- • character_set_system:此变量是Global read only变量,设置为utf8mb3,所有元数据使用此Charset,元数据包括列名、database名、用户名、版本名以及SHOW命令的大部分字符串结果。使用utf8mb3存储元数据并不意味着服务器以character_set_system字符集返回列名,当执行“SELECT column1 FROM t”时,列名“column1”本身是转换为character_set_results系统变量确定的Charset,再从服务器返回到客户端的。下面这个例子尝试在表名中包含非utf8mb3字符,可以看出是不成功的。非法字符会被转换成'?'进行存储。注:由于显示问题,下列SQL中的可能会被显示成其乱码。
-- 1.虽然创建成功,但由于utf8mb3不包含字符'𠀫',
-- 因此被转成问号,字符集转换过程后文描述
mysql> create table `𠀫` (a int);
Query OK, 0 rows affected, 1 warning (0.26 sec)
mysql> show warnings;
+---------+------+------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+------------------------------------------------------------------+
| Warning | 1300 | Cannot convert string '\xF0\xA0\x80\xAB' from utf8mb4 to utf8mb3 |
+---------+------+------------------------------------------------------------------+
mysql> select name, hex(name) from mysql.tables
where schem)a_id = 6;
+--------+--------------+
| name | hex(name) |
+--------+--------------+
| ? | 3F | # 0x3F是'?'的编码
+--------+--------------+
-- 2.尝试创建另一张表,命名为'𠀪',创建不成功,
-- 因为都被转为'?',表名重复
mysql> create table `𠀪` (a int);
ERROR 1050 (42S01): Table '?' already exists
在真正介绍character_set_client、character_set_results、character_set_connection、collation_connection这四个变量之前,先介绍一下字符串字面量的概念,如下面最简单的一个例子,'string'这个字符串就是字符串字面量,也就是客户端发来的语句里面的字符串,所有字符串字面量都有自己的Charset和Collation,可以显式指定(具体方法后续小节详细介绍,这里先有个概念)。character_set_connection和collation_connection就是字符串字面量的默认Charset和Collation。
SELECT 'string';
一个例子
下面用一个比较极端的例子来介绍一下这几个变量是如何起作用的。假设客户端使用utf8mb4字符集,并且在建立连接时将本Session的character_set_client和character_set_results设置成了utf8mb4;由于想让字符串字面量使用latin1字符集的Collation,所以又将character_set_connection和collation_connection分别设置成了latin1和latin1_swedish_ci;而查询语句访问到的列使用的Charset和Collation又分别是ucs2和ucs2_general_ci。那么整个过程将会根据这些变量的设置发生多次字符集转换,如下图所示:
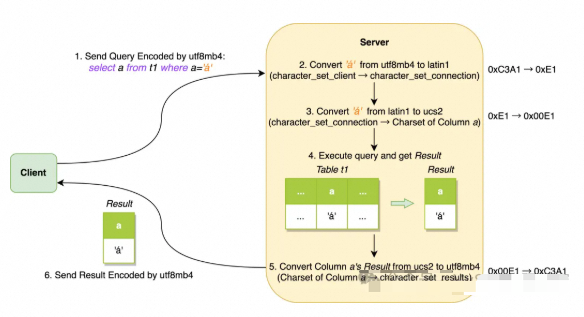
下面文字描述一下上图中的各个步骤:
- • 查询语句中的字符串字面量'á'最开始在客户端的编码使用的是utf8mb4字符集,编码为0xC3A1
- • 服务端接收后会根据character_set_client与character_set_connection的值选择是否进行转换,因为例子中两个变量值不同,因此'á'的编码转为使用latin1字符集,成了0xE1
- • 经过解析语句,发现查询的列使用ucs2字符集,所以'á'的编码再一次发生变化,转为使用ucs2字符集,成了0x00E1
- • 真正执行完语句会得到结果,结果中也包含了'á'这个字符串,使用的是ucs2字符集
- • 在发送结果给客户端之前,会将结果中不是用character_set_results编码的部分进行转换,本例中就将结果中的字符串'á'转换为了utf8mb4字符集,成了0xC3A1
- • 客户端接收到结果后,按照自身的utf8mb4字符集进行解码,再进行后续的处理
下面是复现该例的步骤:
-- 1. 创建表,包含一列,使用ucs2字符集
mysql> create table t1 (a varchar(5) character set ucs2);
-- 2. 插入一行数据'á'
mysql> insert into t1 values ('á');
-- 3. 设置character_set_connection
mysql> set character_set_connection=latin1;
-- 4. 查询'á'的编码,从前向后依次是
-- ucs2、latin1、utf8mb4字符集的编码
mysql> select a, hex(a), hex('á'), hex(_utf8mb4'á')
from t1 where a = 'á';
+------+--------+-----------+-------------------+
| a | hex(a) | hex('á') | hex(_utf8mb4'á') |
+------+--------+-----------+-------------------+
| á | 00E1 | E1 | C3A1 |
+------+--------+-----------+-------------------+
变量具体含义
经过刚才例子相信你已经对几个变量的大致用途有了概念,这几个变量的具体含义如下:
• character_set_connection和collation_connection:该组变量被用于字符串字面量,当字符串字面量本身没有指定Charset和Collation的时候,就用character_set_connection和collation_connection作为该字面量的Charset和Collation。同时该组变量也被用于数字转字符串的时候,目标字符串的Charset和Collation也是该组变量。
• character_set_client:来自客户端的语句所使用的Charset,这个变量的Session值是客户端在连接到服务器时设置的(许多客户端支持一个--default-character-set选项来显式指定这个字符集);当客户端请求的值未知或不可用(ucs2、utf16、utf16le、utf32),或者根本没有请求设置Charset,或者服务器配置--skip-character-set-client-handshake忽略客户端请求时,变量的Global值被用来设置Session值。
• character_set_results:将查询结果返回给客户端时使用的Charset,包括结果数据如列值、结果元数据如列名以及错误信息,这不会影响查询过程,只是最后发送查询结果给客户端时可能会进行一次Charset转换。
大多数情况下,乱码就是因为客户端没有正确设置好character_set_client和character_set_results导致的,因为服务端只能依靠客户端传来的信息决定这两个变量的值,当客户端没有传或错传的时候,就会导致“服务端认为的”与“客户端实际的”驴唇不对马嘴,经过一系列Charset转换后不可预期的乱码就诞生了,这也是本文开篇提到的例1发生乱码的原因。
快捷命令
可以看出跟一个连接相关的变量主要是character_set_client、character_set_results、character_set_connection和collation_connection,为了方便MySQL有SET NAMES和SET CHARACTER SET两个命令可以一次性设置4个变量。
SET NAMES
SET NAMES 'charset_name'这一条语句等价于如下三条语句:
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET character_set_connection = charset_name;
其中设置character_set_connection时会隐式将collation_connection设置为该Charset的默认Collation,如果想更细致地设置Collation,可以使用SET NAMES 'charset_name' COLLATE 'collation_name'指定。
SET CHARACTER SET
SET CHARACTER SET 'charset_name'这一条语句等价于如下三条语句:
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET collation_connection = @@collation_database;
与SET NAMES的唯一不同在于最后一句设置的是collation_connection,变量@@collation_database代表当前所在数据库(use db_name切换库)的默认Collation,这里设置collation_connection也会隐式地将character_set_connection修改为对应Charset。
库表列创建、修改时设置Charset和Collation的语法如下:
-- 创建库
CREATE DATABASE db_name CHARACTER SET charset_name
COLLATE collation_name;
-- 修改库
ALTER DATABASE db_name CHARACTER SET charset_name
COLLATE collation_name;
-- 创建表
CREATE TABLE tbl_name (column_list)
CHARACTER SET charset_name COLLATE collation_name;
-- 修改表
ALTER TABLE tbl_name
CHARACTER SET charset_name COLLATE collation_name;
-- 创建列
CREATE TABLE tbl_name
(col_name VARCHAR(5) CHARACTER SET charset_name
COLLATE collation_name);
-- 修改列
ALTER TABLE tbl_name MODIFY col_name VARCHAR(5)
CHARACTER SET charset_name COLLATE collation_name;
在配置时遵循以下规则:
所有字符串字面量都有自己的Charset和Collation,可以如下显式指定,指定时Charset前需要加一个下划线,同时该语法也可以和b、X前缀搭配使用:
_charset_name'string' COLLATE collation_name
下面是一些示例:
SELECT 'abc';
SELECT _latin1'abc';
SELECT _binary'abc';
SELECT _utf8mb4'abc' COLLATE utf8mb4_danish_ci;
SELECT _latin1 X'4D7953514C';
SELECT _utf8mb4 0x4D7953514C COLLATE utf8mb4_danish_ci;
SELECT _latin1 b'1000001';
SELECT _utf8mb4 0b1000001 COLLATE utf8mb4_danish_ci;
在配置时遵循以下规则:
- • 如果没有显式指定Charset和Collation,那么将使用character_set_connection和collation_connection作为其Charset和Collation,对于b、X前缀的字符串Charset和Collation将设置为binary
- • 如果显式指定了Charset和Collation,那么使用显式指定的Charset和Collation
- • 如果显式指定了Charset没有显式指定Collation,那么使用显式指定的Charset和其默认Collation
- • 如果显式指定了Collation没有显式指定Charset,那么显式指定的Collation需要是character_set_connection的某个Collation -_charset_name被称为Introducer,没有Introducer的情况下解析器会把字符串字面量的字符集都转为character_set_connection,Introducer的作用是告诉解析器,紧随其后的字符串使用charset_name作为Charset,但它不会像CONVERT()函数那样将字符串转换为目标Charset,也不会改变字符串的二进制编码,只会在一些情况下进行padding,这也可能导致乱码:
-- 1.创建表t1,有一列使用latin1字符集
mysql> create table t1(a char(5) character set latin1);
-- 2.直接插入'张'不成功是因为latin1没有该字符,但是加上_latin1前缀就插入成功了,
-- 这是由于Introducer让MySQL解析器误以为这个utf8mb4字符串是latin1字符集的,
-- 后续插入相应列的时候就不加检查、转换了
mysql> insert into t1(a) values('张');
ERROR 1366 (HY000): Incorrect string value: '\xE5\xBC\xA0' for column 'a' at row 1
mysql> insert into t1(a) values(_latin1'张');
Query OK, 1 row affected (0.00 sec)
-- 3.select出来存入的是utf8mb4上'张'的编码0xE5BCA0,产生乱码
mysql> select a, hex(a) from t1;
+--------+--------+
| a | hex(a) |
+--------+--------+
| å¼ | E5BCA0 |
+--------+--------+
mysql> SET @v1 = X'000D' | X'0BC0';
mysql> SET @v2 = _binary X'000D' | X'0BC0';
mysql> SELECT HEX(@v1), HEX(@v2);
+----------+----------+
| HEX(@v1) | HEX(@v2) |
+----------+----------+
| BCD | 0BCD |
+----------+----------+
MySQL构建错误消息的方式如下:
一旦错误消息构建完成,可以由MySQL写入Error Log或发送给客户端:
- • 将错误消息写入Error Log时,会以构建时的utf8mb3字符集写入,无需转换
- • 将错误消息发送给客户端程序时,会将错误消息从utf8mb3转换为由character_set_results系统变量指定的Charset,如果character_set_results的值为NULL或binary,则不进行转换;如果变量值是utf8mb3或utf8mb4,也不会发生转换
- • 如果有字符无法在character_set_results中表示,转换过程中可能会发生一些编码,编码使用Unicode码点:
在MySQL中,有很多情况下会发生转换Charset的行为,例如:
-- 从latin1转换为utf8mb4
UPDATE t1 SET utf8mb4_bin_column=latin1_column;
-- 从utf8mb4转换为latin1
INSERT INTO t1 (latin1_column) SELECT utf8mb4_bin_column FROM t2;
SET NAMES latin1; -- 字面量使用latin1
-- 从latin1转换为utf8mb4
INSERT INTO t1 (utf8mb4_bin_column) VALUES ('string-in-latin1');
SET NAMES latin1; -- 客户端使用latin1
-- 结果字符串使用utf8mb4,需要转换为latin1再发送客户端
SELECT utf8mb4_bin_column FROM t2;
SELECT CONVERT(_latin1 'Müller' USING utf8mb4);
SELECT CAST('test' AS CHAR CHARACTER SET utf8mb4);
-- 从utf8mb4转换为latin1
ALTER TABLE t1 MODIFY utf8mb4_bin_column VARCHAR(10) CHARACTER SET latin1;
-- 将表内所有列的Charset转换为latin1
ALTER TABLE t1 CONVERT TO CHARACTER SET latin1;
-- 需要判断优先级,该例中latin1列数据从latin1转换为utf8mb4
SELECT CONCAT(utf8mb4_column, latin1_column) FROM t1;
要将二进制或非二进制字符串列转换为使用特定Charset,需要使用ALTER TABLE,为了能够成功转换,必须满足以下条件之一:
使用ALTER TABLE修改列定义后,有两个需要额外注意的点:
UPDATE t SET col1 = TRIM(TRAILING 0x00 FROM col1);
SELECT x FROM T WHERE x = 'Y';
SELECT concat(x, 'Y', z) FROM T;
在上面的例子中如果x列、字面量、z列都使用相同的Charset和Collation,那么上面的语句将没有任何歧义,但如果它们的Charset或Collation不同,那么以谁的Charset和Collation为准呢?为此MySQL定义了一些规则来消除这些歧义,可以通过COERCIBILITY函数查看优先级,值越低优先级越高:
SELECT COERCIBILITY(_utf8mb4'A' COLLATE utf8mb4_bin);
-- 返回0
• 两个具有不同Collation的字符串连接后得到的字符串的coercibility为1
• 列、存储过程参数或局部变量的Collation的coercibility为2
• 系统常量(如USER()或VERSION()函数返回的字符串)的coercibility为3。
SELECT COERCIBILITY(VERSION()); -- 返回3
SELECT COERCIBILITY('A'); -- 返回4
SELECT COERCIBILITY(1000); -- 返回5
SELECT COERCIBILITY(NULL); -- 返回6
基于以上规则,就可以选出coercibility最小也就是优先级最高的字符串,它的Charset和Collation将被用于表达式及结果,但是如果出现了两个字符串的coercibility一样的情况呢?那就需要如下规则:
- • 如果两个字符串都使用或都没使用Unicode Charset,那么返回错误
- • 如果一方使用Unicode Charset,另一方使用非Unicode Charset,那么使用Unicode Charset的一方将占优势,非Unicode Charset的一方将自动转换为Unicode Charset。这源于MySQL认为任何Charset所包含字符都可以看作Unicode Charset所包含字符的子集 下面是一些具体的示例:
| 表达式 | 使用的Collation |
| column1 = 'A' | 使用column1的Collation |
| column1 = 'A' COLLATE x | 使用Collation x |
| column1 COLLATE x = 'A' COLLATE y | 报错 |
入口函数是位于sql-common/sql_string.cc的String::copy函数,其内主要是做了三件事:
1. 检查是否需要转换字符集,不需要的话就直接做字符串copy
2. 检查原字符集是否是binary字符集,是的话就字节级别copy并对齐
3. 其他情况意味着需要字符集转换,进行转换并copy
bool String::copy(const char *str, size_t arg_length,
const CHARSET_INFO *from_cs, const CHARSET_INFO *to_cs,
uint *errors) {
...
/* 1. 不需要转换就直接copy */
if (!needs_conversion(arg_length, from_cs, to_cs, &offset)) {
*errors = 0;
return copy(str, arg_length, to_cs);
}
/* 2. 原字符集是binary字符集,字节级copy并对齐 */
if ((from_cs == &my_charset_bin) && offset) {
*errors = 0;
return copy_aligned(str, arg_length, offset, to_cs);
}
size_t new_length = to_cs->mbmaxlen * arg_length;
if (alloc(new_length)) return true;
/* 3. 进行字符集转换并copy */
m_length = copy_and_convert(m_ptr, new_length, to_cs, str, arg_length,
from_cs, errors);
m_charset = to_cs;
return false;
}
下面详细看看字符集转换具体怎么做的,copy_and_convert函数内透传调用my_convert函数,该函数逐字符检查,假如是ascii字符就直接复制,不是的话调用my_convert_internal进行后续处理,该函数就是字符集转换的关键,它对每个字符做了以下几件事:
- 1. 按照原字符集规则解析二进制编码,并根据解析结果获得对应的Unicode码点:
- a. 解析成功并且获得了Unicode码点,就进入第2步
- b. 解析失败就将对应字节当作'?'字符,使用其Unicode码点U+003F
- c. 解析成功,但是Unicode不包含对应字符,无法获得Unicode码点,把该字符当作'?'字符,使用其Unicode码点U+003F,这里一般不会发生,因为Unicode字符通常是最全面的
2. 将上一步获得的Unicode码点转换成目标字符集编码,如果目标字符集不包含该字符,就将其转为'?'字符
static size_t my_convert_internal(char *to, size_t to_length,
const CHARSET_INFO *to_cs, const char *from,
size_t from_length,
const CHARSET_INFO *from_cs, uint *errors) {
...
/* 每个字符集会定义自己的字符编码到Unicode码点、Unicode码点到字符编码的映射函数,
这里需要原字符集的第一个函数,新字符集的第二个函数 */
my_charset_conv_mb_wc mb_wc = from_cs->cset->mb_wc;
my_charset_conv_wc_mb wc_mb = to_cs->cset->wc_mb;
...
while (true) { /* 循环处理每个字符 */
/* 1. 解析二进制编码到Unicode码点 */
if ((cnvres = (*mb_wc)(from_cs, &wc, pointer_cast<const uchar *>(from),
from_end)) > 0) /* a. 成功*/
from += cnvres;
else if (cnvres == MY_CS_ILSEQ) { /* b. 解析失败 */
error_count++;
from++;
wc = '?';
} else if (cnvres > MY_CS_TOOSMALL) { /* c. 解析成功但是获取Unicode码点失败 */
error_count++;
from += (-cnvres);
wc = '?';
} else
break;
outp:
/* 2. 将上一步获得的Unicode码点转换成目标字符集编码 */
if ((cnvres = (*wc_mb)(to_cs, wc, (uchar *)to, to_end)) > 0) /* 成功 */
to += cnvres;
else if (cnvres == MY_CS_ILUNI && wc != '?') { /* 失败,将wc赋值为'?'(0x3F),重试转换 */
error_count++;
wc = '?';
goto outp;
} else
break;
}
...
}
从源码可以看出两点需要注意的地方:
-- 1. 创建表t1,有一个使用latin1字符集的列
mysql> create table t1 (a varchar(5) character set latin1);
-- 2. 插入'张',由于latin1字符集没有字符'张',因此直接报错,无法插入成功
mysql> insert into t1 values('张');
ERROR 1366 (HY000): Incorrect string value: '\xE5\xBC\xA0' for column 'a' at row 1
-- 3. 使用二进制字面量字符串插入,成功了,哪怕latin1字符集根本没有字符编码是0xE5BCA0
mysql> insert into t1 values(X'E5BCA0'); -- 0xE5BCA0是'张'在utf8mb4字符集的编码
Query OK, 1 row affected (0.00 sec)
-- 4. 查询看下结果,返回乱码,存的内容就是传啥存啥
mysql> select a, hex(a) from t1;
+--------+--------+
| a | hex(a) |
+--------+--------+
| å¼ | E5BCA0 |
+--------+--------+
-- latin1字符集没有字符'张',转成了'?',16进制为0x3F
mysql> select hex(cast(_utf8mb4'张' as char character set latin1));
+-------------------------------------------------------+
| hex(cast(_utf8mb4'张' as char character set latin1)) |
+-------------------------------------------------------+
| 3F |
+-------------------------------------------------------+
在真正介绍Unicode字符串排序算法原理前,先通过MySQL中的一个例子对字符串排序有一个初步概念。首先创建一个只有一个VARCHAR列的表,该列使用的Charset是utf8mb4,向表中插入 “rôle”、 “Role”、 “role”、 “roles”、“rule”五个字符串,下面是分别使用utf8mb4_0900_as_cs和utf8mb4_bin两种Collation的排序结果:
mysql> select * from role_table
order by str collate utf8mb4_0900_as_cs;
+-------+
| str |
+-------+
| role |
| Role |
| rôle |
| roles |
| rule |
+-------+
mysql> select * from role_table
order by str collate utf8mb4_bin;
+-------+
| str |
+-------+
| Role |
| role |
| roles |
| rule |
| rôle |
+-------+
可以看出Collation的不同影响了排序结果,先解释一下utf8mb4_bin的结果,其实该Collation排序规则很简单,就是将字符都转为原本的Unicode码点,然后根据码点数组由前到后进行比较,因此大写字母R排在了小写字母r前面。
utf8mb4_0900_as_cs既是音调敏感又是大小写敏感,该Collation基于UCA(Unicode Collation Algorithm) 9.0.0实现,本节将会以该版本UCA为例进行介绍,比较两个字符串绝大多数情况分为三个层次:原始字符、音调、大小写,三个层次的优先级逐级递减,只有前一级完全相等时才会比较下一级,因此:
至此,经过三个层级的比较,完全决定出五个字符串的大小关系,本例中使用的Collation是带_as、_cs后缀的,对于_ai、_ci后缀的Collation,会取消对应层级的比较,比如utf8mb4_0900_ai_ci会认为“role”=“Role”=“rôle”
从上面例子的介绍可以看出在UCA 9.0.0进行字符串比较时,会获得每个字符在三个层级的键,显然字符的Unicode码点已经无法满足需求,那么就需要一个权重表去记录每个字符在三个层级上的权重,每个版本的UCA都会有一个对应的DUCET(Default Unicode Collation Element Table)[27]记录这些信息,不同语言的定制化Collation其实就是基于DUCET加了本语言的一些特定权重配置。
下面给出几个表项的示例:
0061 ; [.1C47.0020.0002] # LATIN SMALL LETTER A
0041 ; [.1C47.0020.0008] # LATIN CAPITAL LETTER A
1D434 ; [.1C47.0020.000B] # MATHEMATICAL ITALIC CAPITAL A
00E1 ; [.1C47.0020.0002][.0000.0024.0002] # LATIN SMALL LETTER A WITH ACUTE
249C ; [*0317.0020.0004][.1C47.0020.0004][*0318.0020.0004] # PARENTHESIZED LATIN SMALL LETTER A
上面示例中的五个字符分别是a、A、𝐴、á、⒜,其中第一列是字符的Unicode码点,之后每一个方括号[]包裹的包含三个数字的数组称为一个Collation Element,一个字符可能对应一或多个Collation Element,#是注释符,其后是对该字符的介绍信息。
Collation Element内的三个16进制数字从前到后分别代表了原始字符、音调、大小写三个层级的权重,'*'开头的数字一般对应于标点符号,在有的比较方式中会忽略,但是MySQL内并没有对标点符号特殊处理,因此⒜字符前后的()标点符号也参与排序。
下面稍微解释下á、⒜对应多个Collation Element的由来,UCA定义了将一个复杂字符分解(decomposition)的规则[28],因此如下表所示,分解得到简单字符的Collation Element List再组织起来就成了上面例子中最终的Collation Element(并不一定完全相等,可能伴随一些音调、大小写权重的变化):
| 原字符 | 分解后 | Collation Elements |
| á | 'a'、' ́' | [.1C47.0020.0002]、[.0000.0024.0002] |
| ⒜ | '('、'a'、')' | [*0317.0020.0002]、[.1C47.0020.0002]、[*0318.0020.0002] |
有了权重表之后,就剩下该如何使用权重表了,特别是有些字符不止对应一个Collation Element,UCA会计算出整个字符串用于排序的Sort Key,下面用字符串"aáA"为例进行介绍,三个字符及其Collation Element如下:
| 字符 | Collation Element |
| a | [.1C47.0020.0002] |
| á | [.1C47.0020.0002][.0000.0024.0002] |
| A | [.1C47.0020.0008] |
1. 获得字符串中所有字符的Collation Element,并组成一个Collation Element List,本例如下:
| aáA | [.1C47.0020.0002][.1C47.0020.0002][.0000.0024.0002][.1C47.0020.0008] |
2. 将所有第一层级的权重(略过为0的项)从前向后取出拼接在一起,本例如下:
3. 如果是音调敏感(_as),将所有第二层级的权重(略过为0的项)从前向后取出拼接在一起,本例如下:
4. 如果是大小写敏感(_cs),将所有第三层级的权重(略过为0的项)从前向后取出拼接在一起,本例如下:
5. 最后根据是否音调、大小写敏感选择是否将SortKey2、SortKey3拼接,假设都敏感的情况下,如下拼接出最终的SortKey,拼接符为0000,本例如下:
之后对于字符串的比较就全部根据Sort Key,本质是一个16bit整型数组,数组中越靠前的值在比较时优先级就越高,至此就已经实现了三个层级的比较架构。在MySQL中可以使用WEIGHT_STRING函数获得字符串的Sort Key,本例如下:
-- 音调、大小写敏感
mysql> select hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_as_cs));
+---------------------------------------------------------------+
| hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_as_cs)) |
+---------------------------------------------------------------+
| 1C471C471C470000002000200024002000000002000200020008 |
+---------------------------------------------------------------+
-- 音调敏感,大小写不敏感
mysql> select hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_as_ci));
+---------------------------------------------------------------+
| hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_as_ci)) |
+---------------------------------------------------------------+
| 1C471C471C4700000020002000240020 |
+---------------------------------------------------------------+
-- 音调、大小写不敏感
mysql> select hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_ai_ci));
+---------------------------------------------------------------+
| hex(weight_string(_utf8mb4'aáA' collate utf8mb4_0900_ai_ci)) |
+---------------------------------------------------------------+
| 1C471C471C47 |
+---------------------------------------------------------------+
因此当我们设定Collation为音调、大小写不敏感时,会有很多非预期的情况出现,这时"aaaa"和"aáA𝐴"会被认为相等,如下:
mysql> select _utf8mb4'aáA𝐴' collate utf8mb4_0900_ai_ci = 'aaaa';
+-----------------------------------------------------+
| _utf8mb4'aáA?' collate utf8mb4_0900_ai_ci = 'aaaa' |
+-----------------------------------------------------+
| 1 |
+-----------------------------------------------------+
虽然UCA提供的权重表包含了很多字符到其Collation Element的映射,但是并不是所有字符都在表中拥有一个条目,对于这些字符,UCA会按照一定规则生成其Collation Element。
UCA 9.0.0
如果字符需要生成权重,那么其对应两个Collation Element,形如[.AAAA.0020.0002][.BBBB.0000.0000],其中AAAA和BBBB是根据字符的Unicode码点计算出来的,UCA 9.0.0规则的MySQL实现如下:
static void set_implicit_weights(MY_UCA_ITEM *item, int code) {
int base, aaaa, bbbb;
if (code >= 0x17000 && code <= 0x18AFF) // Tangut character
{
aaaa = 0xFB00;
bbbb = (code - 0x17000) | 0x8000;
} else {
/* non-Core Han Unified Ideographs */
if ((code >= 0x3400 && code <= 0x4DB5) ||
(code >= 0x20000 && code <= 0x2A6D6) ||
(code >= 0x2A700 && code <= 0x2B734) ||
(code >= 0x2B740 && code <= 0x2B81D) ||
(code >= 0x2B820 && code <= 0x2CEA1))
base = 0xFB80;
/* Core Han Unified Ideographs */
else if ((code >= 0x4E00 && code <= 0x9FD5) ||
(code >= 0xFA0E && code <= 0xFA29))
base = 0xFB40;
/* All other characters whose weight is unassigned */
else
base = 0xFBC0;
aaaa = base + (code >> 15);
bbbb = (code & 0x7FFF) | 0x8000;
}
item->weight[0] = aaaa;
item->weight[1] = 0x0020;
item->weight[2] = 0x0002;
item->weight[3] = bbbb;
item->weight[4] = 0x0000;
item->weight[5] = 0x0000;
item->num_of_ce = 2;
}
中日韩字符的Collation Element基本就是这样生成的,如“张”的Unicode码点是0x5F20,对应上面代码base就是FB40,那么aaaa就可以计算得到是0xFB40,bbbb就可以计算得到是0xDF20,因此“张”这个字符的Collation Element就是[.FB40.0020.0002][.DF20.0000.0000],作为字符串来看它的Sort Key如下,与我们的推算相符:
mysql> select hex(weight_string(_utf8mb4'张' collate utf8mb4_0900_as_cs));
+--------------------------------------------------------------+
| hex(weight_string(_utf8mb4'张' collate utf8mb4_0900_as_cs)) |
+--------------------------------------------------------------+
| FB40DF200000002000000002 |
+--------------------------------------------------------------+
UCA 4.0.0
对于utf8mb4非0900、520的Collation来说,它们使用的UCA 4.0.0,在该版本的UCA中仅支持为BMP字符(U+0000到U+FFFF)生成权重,所有非BMP字符(U+10000到U+10FFFF)的权重统一为0xFFFD,因此在utf8mb4_unicode_ci看来所有非BMP字符都是相等的,如下:
-- '𠀫'的Unicode码点为U+2002B,其在utf8mb4_unicode_ci下的权重为0xFFFD
mysql> select hex(weight_string(_utf8mb4'𠀫' collate utf8mb4_unicode_ci));
+------------------------------------------------------------+
| hex(weight_string(_utf8mb4'?' collate utf8mb4_unicode_ci)) |
+------------------------------------------------------------+
| FFFD |
+------------------------------------------------------------+
-- 在基于UCA 4.0.0的utf8mb4_unicode_ci看来,'𠀫'和'𠀪'相等
mysql> select _utf8mb4'𠀫' collate utf8mb4_unicode_ci = '𠀪';
+----------------------------------------------+
| _utf8mb4'?' collate utf8mb4_unicode_ci = '?' |
+----------------------------------------------+
| 1 |
+----------------------------------------------+
-- 在基于UCA 9.0.0的utf8mb4_0900_ai_ci看来,'𠀫'和'𠀪'不等
mysql> select _utf8mb4'𠀫' collate utf8mb4_0900_ai_ci = '𠀪';
+----------------------------------------------+
| _utf8mb4'?' collate utf8mb4_0900_ai_ci = '?' |
+----------------------------------------------+
| 0 |
+----------------------------------------------+
对于未明确指定权重的BMP字符来说,生成权重的规则和UCA 9.0.0类似,只是没有对非BMP字符的处理,如下:
if (code >= 0x3400 && code <= 0x4DB5)
base= 0xFB80; /* CJK Ideograph Extension */
else if (code >= 0x4E00 && code <= 0x9FA5)
base= 0xFB40; /* CJK Ideograph */
else
base= 0xFBC0; /* All other characters */
aaaa= base + (code >> 15);
bbbb= (code & 0x7FFF) | 0x8000;
对于MySQL中的Unicode字符集,普遍有一个_general Collation和一个_unicode Collation,对于utf8mb4字符集而言,这两个Collation分别是utf8mb4_general_ci和utf8mb4_unicode_ci。这两个Collation都是基于UCA 4.0.0,但是utf8mb4_general_ci可以看作是utf8mb4_unicode_ci的简化,utf8mb4_general_ci不支持一个字符映射到多个Collation Element,因此有些在DUCET中规定的规则在utf8mb4_general_ci上并不生效,下面是一个例子。
| 字符 | Collation Element |
| s | [.0FEA.0020.0008.0053] |
| ß | [.0FEA.0020.0004.00DF][.0000.015D.0004.00DF][.0FEA.0020.001F.00DF] |
在UCA 4.0.0的权重表中,每个Collation Element有四个数值,第四个是Unicode码点,前三个数值的含义、使用方法与9.0.0一致,下面看看utf8mb4_general_ci与utf8mb4_unicode_ci的不同:
-- 1. utf8mb4_general_ci的Sort Key是字符还原后的Unicode码点,'ß'被还原为's'
mysql> select hex(weight_string(_utf8mb4'ß' collate utf8mb4_general_ci));
+-------------------------------------------------------------+
| hex(weight_string(_utf8mb4'ß' collate utf8mb4_general_ci)) |
+-------------------------------------------------------------+
| 0053 |
+-------------------------------------------------------------+
mysql> select hex(weight_string(_utf8mb4's' collate utf8mb4_general_ci));
+------------------------------------------------------------+
| hex(weight_string(_utf8mb4's' collate utf8mb4_general_ci)) |
+------------------------------------------------------------+
| 0053 |
+------------------------------------------------------------+
-- 2. utf8mb4_general_ci看来,'ß'与's'相等
mysql> select _utf8mb4'ß' collate utf8mb4_general_ci = 's';
+-----------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_general_ci = 's' |
+-----------------------------------------------+
| 1 |
+-----------------------------------------------+
-- 3. utf8mb4_unicode_ci的Sort Key与UCA 9.0.0类似,只是映射表不同,
-- 允许一个字符映射为多个Collation Element
mysql> select hex(weight_string(_utf8mb4'ß' collate utf8mb4_unicode_ci));
+-------------------------------------------------------------+
| hex(weight_string(_utf8mb4'ß' collate utf8mb4_unicode_ci)) |
+-------------------------------------------------------------+
| 0FEA0FEA |
+-------------------------------------------------------------+
mysql> select hex(weight_string(_utf8mb4's' collate utf8mb4_unicode_ci));
+------------------------------------------------------------+
| hex(weight_string(_utf8mb4's' collate utf8mb4_unicode_ci)) |
+------------------------------------------------------------+
| 0FEA |
+------------------------------------------------------------+
-- 4. utf8mb4_unicode_ci看来,'ß'与'ss'相等,而不是与's'相等
mysql> select _utf8mb4'ß' collate utf8mb4_unicode_ci = 'ss';
+------------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_unicode_ci = 'ss' |
+------------------------------------------------+
| 1 |
+------------------------------------------------+
在CPU还没有很强大的年代,utf8mb4_general_ci由于简化了一些内容(伴随着准确性的损失),相比utf8mb4_unicode_ci能够有更好的性能,但是随着CPU的发展,这里的性能提升已经不明显了,所以目前并不建议继续使用utf8mb4_general_ci。至于utf8mb4_unicode_ci,其基于的UCA 4.0.0相比utf8mb4_0900_xx基于的UCA 9.0.0也落后了很多,因此更加建议使用utf8mb4_0900_xx Collation,至于后缀是使用_ai_ci、_as_ci、_as_cs中的哪一个,就需要根据自身业务进行考量。
在上面例子中,描述的都是=、这种常规的比较,直接用算好的Sort Key即可,因此会有utf8mb4_unicode_ci上'ß'='ss'的情况,一个字符也可以和两个字符相等,但是LIKE运算符就不允许这种情况了,LIKE只允许一对一的字符匹配,所以有下例所示:
-- utf8mb4_unicode_ci上,'ß'既不LIKE 'ss',也不LIKE 's'
mysql> select _utf8mb4'ß' collate utf8mb4_unicode_ci like 'ss';
+---------------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_unicode_ci like 'ss' |
+---------------------------------------------------+
| 0 |
+---------------------------------------------------+
mysql> select _utf8mb4'ß' collate utf8mb4_unicode_ci like 's';
+--------------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_unicode_ci like 's' |
+--------------------------------------------------+
| 0 |
+--------------------------------------------------+
-- utf8mb4_general_ci上,'ß' LIKE 's'如同=比较符一样,因为它们是字符级别一对一相等
mysql> select _utf8mb4'ß' collate utf8mb4_general_ci like 's';
+--------------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_general_ci like 's' |
+--------------------------------------------------+
| 1 |
+--------------------------------------------------+
binary Charset与_bin Collation
本节将介绍最直观的二进制比较方式,包括binary Charset的binary Collation与非二进制Charset的_bin Collation两类,同时它们两者也有一些不同。BINARY、VARBINARY和BLOB数据类型使用binary Charset以及binary Collation,binary字符串是字节序列,这些字节的数值决定了排序顺序。
CHAR、VARCHAR和TEXT数据类型大多数情况下使用了非二进制的Charset,对于大多数非二进制Charset,其上支持一个_bin结尾的二进制比较Collation。例如,latin1和big5的二进制Collation分别命名为latin1_bin和big5_bin。utf8mb4是一个例外,它有两个二进制Collation,utf8mb4_bin和utf8mb4_0900_bin。
binary Charset的基本比较单位是字节,非二进制Charset的基本比较单位是字符,字节和字符的差别在于字符有可能是多个字节组成的。当binary Charset的binary Collation进行比较时,会逐字节比较其数值;当非二进制Charset的_bin Collation进行比较时,会逐字符比较其数值,对于Unicode Charset而言有如下规律:除utf8mb4_0900_bin外的_bin Collation会将字符转为Unicode码点进行比较,可能会加上前导0
utf8mb4_0900_bin会使用字符原本的二进制进行比较,因为utf-8编码顺序和Unicode码点顺序上一致,所以可以获得相同结果,同时速度会更快 下面以binary、utf8mb4_bin、utf8mb4_0900_bin三种Collation举例演示:
-- 使用以下两个字符为例
mysql> select _utf8mb4 X'64';
+----------------+
| _utf8mb4 X'64' |
+----------------+
| d |
+----------------+
mysql> select _utf8mb4 X'e18080';
+--------------------+
| _utf8mb4 X'e18080' |
+--------------------+
| က |
+--------------------+
-- 1. binary
mysql> select WEIGHT_STRING(_binary X'64');
+------------------------------------------------------------+
| WEIGHT_STRING(_binary X'64') |
+------------------------------------------------------------+
| 0x64 |
+------------------------------------------------------------+
mysql> select WEIGHT_STRING(_binary X'e18080');
+--------------------------------------------------------------------+
| WEIGHT_STRING(_binary X'e18080') |
+--------------------------------------------------------------------+
| 0xE18080 |
+--------------------------------------------------------------------+
-- 2. utf8mb4_bin
mysql> select WEIGHT_STRING(_utf8mb4 X'64' collate utf8mb4_bin);
+------------------------------------------------------------------------------------------------------+
| WEIGHT_STRING(_utf8mb4 X'64' collate utf8mb4_bin) |
+------------------------------------------------------------------------------------------------------+
| 0x000064 |
+------------------------------------------------------------------------------------------------------+
mysql> select WEIGHT_STRING(_utf8mb4 X'e18080' collate utf8mb4_bin);
+--------------------------------------------------------------------------------------------------------------+
| WEIGHT_STRING(_utf8mb4 X'e18080' collate utf8mb4_bin) |
+--------------------------------------------------------------------------------------------------------------+
| 0x001000 |
+--------------------------------------------------------------------------------------------------------------+
-- 3. utf8mb4_0900_bin
mysql> select WEIGHT_STRING(_utf8mb4 X'64' collate utf8mb4_0900_bin);
+----------------------------------------------------------------------------------------------------------------+
| WEIGHT_STRING(_utf8mb4 X'64' collate utf8mb4_0900_bin) |
+----------------------------------------------------------------------------------------------------------------+
| 0x64 |
+----------------------------------------------------------------------------------------------------------------+
mysql> select WEIGHT_STRING(_utf8mb4 X'e18080' collate utf8mb4_0900_bin);
+------------------------------------------------------------------------------------------------------------------------+
| WEIGHT_STRING(_utf8mb4 X'e18080' collate utf8mb4_0900_bin) |
+------------------------------------------------------------------------------------------------------------------------+
| 0xE18080 |
+------------------------------------------------------------------------------------------------------------------------+
可以发现:
- • binary Charset没有字符的概念,在它看来所有字符串都是字节序列,它看到的字节序列就是binary Collation对该字符串比较、排序时使用的权重key
- • utf8mb4 Charset就有字符的概念,但是utf8mb4_bin和utf8mb4_0900_bin两种Collation的表现有些不同
- • utf8mb4_bin会将所有字符转回Unicode码点并且补齐到3 byte(因为Unicode字符可以完全使用3 byte表示),例子中一字节字符d转为了0x000064,三字节字符က转为了0x001000,因此可以清晰看出_bin Collation是以字符为基本单位进行比较的
- • utf8mb4_0900_bin则不能明显体现出以字符为基本单位,它的表现和binary Collation类似,直接使用utf8mb4原始编码进行比较,由于本身编码设计就已经满足多字节字符二进制首字节数值更大,所以这里不进行补齐byte直接比较也是可以达到相同目标的
二进制字符串没有字符大小写的概念,而非二进制字符串哪怕使用了_bin Collation也可以使用大小写转换函数,如下例所示:
mysql> SET NAMES utf8mb4 COLLATE utf8mb4_bin;
mysql> SELECT LOWER('aA'), UPPER('zZ');
+-------------+-------------+
| LOWER('aA') | UPPER('zZ') |
+-------------+-------------+
| aa | ZZ |
+-------------+-------------+
mysql> SET NAMES binary;
mysql> SELECT LOWER('aA'), LOWER(CONVERT('aA' USING utf8mb4));
+-------------+------------------------------------+
| LOWER('aA') | LOWER(CONVERT('aA' USING utf8mb4)) |
+-------------+------------------------------------+
| aA | aa |
+-------------+------------------------------------+
CHAR、VARCHAR、BINARY、VARBINARY
这四种数据类型和Charset、Collation的相关性很高,因此这里介绍一些关键点:
- • CHAR(N)、VARCHAR(N)的N代表的是字符数,CHAR(N)预留的是“N*字符集最长字符字节数”个字节;BINARY(N)、VARBINARY(N)的N代表的是字节数,BINARY(N)预留的是N个字节。举个例子说明,假设一个列类型为CHAR(5),使用的utf8mb4字符集,由于最长字符的字节数为4,所以每个CHAR(5)都会预留5*4=20字节;但是BINARY(5)就只会预留5字节。
- • 列定义时CHAR BINARY和VARCHAR BINARY并不意味着和BINARY类型有什么关系,而是意味着使用字符集的_bin Collation。例如当默认Charset是utf8mb4时,CHAR(5) BINARY等于是CHAR(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin的缩写。
- • CHAR和BINARY在插入数据时,如果数据不够长,会进行padding,CHAR类型padding的是0x20(空格符),BINARY类型padding的时0x00。在读取CHAR类型列的时候,MySQL会自动将所有padding的0x20摘掉,因此在MySQL看来,向CHAR列插入"a"和"a "后读取出来都是"a",丢失了原本的空格。在读取BINARY列的时候会将完整的N个字节返回(包括padding的0x00),如下例所示:
mysql> CREATE TABLE t (c BINARY(3));
mysql> INSERT INTO t SET c = 'a';
-- 字符串'a'后被补足了两个0x00,在判断时不认为该列数据等于'a',而是等于'a\0\0'
mysql> SELECT HEX(c), c = 'a', c = 'a\0\0' from t;
+--------+---------+-------------+
| HEX(c) | c = 'a' | c = 'a\0\0' |
+--------+---------+-------------+
| 610000 | 0 | 1 |
+--------+---------+-------------+
-- VARCHAR和VARBINARY就没有上面所述padding的步骤,因此VARCHAR存入"a "后读取出来仍然是"a ",下面是一个例子:
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
mysql> INSERT INTO vc VALUES ('ab ', 'ab ');
-- VARCHAR列数据的尾部空格符能够返回,CHAR列数据的尾部空格符无法返回
mysql> SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;
+---------------------+---------------------+
| CONCAT('(', v, ')') | CONCAT('(', c, ')') |
+---------------------+---------------------+
| (ab ) | (ab) |
+---------------------+---------------------+
MySQL支持了很多Charset与Collation,并且允许用户在连接、Server、库、表、列、字面量多个层次上进行精细化配置,这有时会让用户眼花缭乱。本文对相关概念、语法、系统变量、影响范围都进行了详细介绍,并且列举了有可能让字符串发生字符集转换的情况,以及来自不同字符集的字符串进行比较等操作时遵循的规则。
对于最常用的基于Unicode的字符集,本文介绍了Unicode标准与MySQL中各个字符集的关系,尤其详细介绍了当前版本(8.0.34)默认字符集utf8mb4。为了能够理解MySQL如何比较字符串,本文还介绍了Unicode标准定义的字符串多级排序算法,并举例说明了一些可能让中文用户感到费解的例子。
最后本文还介绍了特殊的binary字符集,厘清了其与其他非二进制字符集的_bin Collation的异同。经过本文的介绍,相信你已经对MySQL的Charset和Collation有了比较清晰的认识,下面将汇总一些关键点。
客户端实际使用的字符集与登记在服务端的character_set_client、character_set_results变量不一致,“客户端使用的”和“服务端以为客户端使用的”不统一,造成后续的错误处理,如开篇例子所示:
-- 1.创建表t1,有两列,一列使用utf8mb4字符集,一列使用latin1字符集
mysql> create table t1 (a char(5) character set utf8mb4, b char(5) character set latin1);
-- 2.客户端实际使用utf8mb4字符集,却在服务端登记的是latin1字符集
mysql> set names latin1;
-- 2.a 列a使用utf8mb4字符集,MySQL看来character_set_client和
-- character_set_connection都是latin1,多了一次latin1字符集到utf8mb4
-- 字符集的转换,哪怕客户端原始传的就是utf8mb4格式编码,经过这一次转换后
-- 结果不可预期
-- 2.b 哪怕列b的latin1字符集没有字符'张'也能成功插入,这是因为MySQL看来
-- character_set_client、character_set_connection和列b字符集全都一致
-- 是latin1,无需做检查和转换,直接插入
mysql> insert into t1 values('张','张');
-- 3.正常客户端查询数据
mysql> set names utf8mb4;
-- a列(utf8mb4字符集)内容完全错乱,b列(latin1字符集)内容是'张'的utf8mb4编码
mysql> select a,hex(a),b,hex(b) from t1;
+--------+--------------+--------+--------+
| a | hex(a) | b | hex(b) |
+--------+--------------+--------+--------+
| å¼ | C3A5C2BCC2A0 | å¼ | E5BCA0 |
+--------+--------------+--------+--------+
character_set_client哪怕配置正确,Introducer没有正确使用也可能跳过检查、转换插入乱码数据,如下例所示:
-- 1.创建表t1,有一列使用latin1字符集
mysql> create table t1(a char(5) character set latin1);
-- 2.直接插入'张'不成功是因为latin1没有该字符,但是加上_latin1前缀就插入成功了,
-- 这是由于Introducer让MySQL解析器误以为这个utf8mb4字符串是latin1字符集的,
-- 后续插入相应列的时候就不加检查、转换了
mysql> insert into t1(a) values('张');
ERROR 1366 (HY000): Incorrect string value: '\xE5\xBC\xA0' for column 'a' at row 1
mysql> insert into t1(a) values(_latin1'张');
Query OK, 1 row affected (0.00 sec)
-- 3.select出来存入的是utf8mb4上'张'的编码0xE5BCA0,产生乱码
mysql> select a, hex(a) from t1;
+--------+--------+
| a | hex(a) |
+--------+--------+
| å¼ | E5BCA0 |
+--------+--------+
配置完全正确,但是用了binary字符串插入数据,binary字符串向非binary字符串转换时是逐字节拷贝,没有合法性检查,可以插入乱码数据,如下例所示:
-- 1. 创建表t1,有一个使用latin1字符集的列
mysql> create table t1 (a varchar(5) character set latin1);
-- 2. 插入'张',由于latin1字符集没有字符'张',因此直接报错,无法插入成功
mysql> insert into t1 values('张');
ERROR 1366 (HY000): Incorrect string value: '\xE5\xBC\xA0' for column 'a' at row 1
-- 3. 使用二进制字面量字符串插入,成功了,哪怕latin1字符集根本没有字符编码是0xE5BCA0
mysql> insert into t1 values(X'E5BCA0'); -- 0xE5BCA0是'张'在utf8mb4字符集的编码
Query OK, 1 row affected (0.00 sec)
-- 4. 查询看下结果,返回乱码,存的内容就是传啥存啥
mysql> select a, hex(a) from t1;
+--------+--------+
| a | hex(a) |
+--------+--------+
| å¼ | E5BCA0 |
+--------+--------+
-- 1. utf8mb4_general_ci看来,'ß'与's'相等
mysql> select _utf8mb4'ß' collate utf8mb4_general_ci = 's';
+-----------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_general_ci = 's' |
+-----------------------------------------------+
| 1 |
+-----------------------------------------------+
-- 2. utf8mb4_0900_ai_ci看来,'ß'与'ss'相等,而不是与's'相等,支持更加复杂的组合比较
mysql> select _utf8mb4'ß' collate utf8mb4_0900_ai_ci = 'ss';
+------------------------------------------------+
| _utf8mb4'ß' collate utf8mb4_0900_ai_ci = 'ss' |
+------------------------------------------------+
| 1 |
+------------------------------------------------+
utf8mb4_general_ci具有“PAD SPACE”属性,比较时会忽略尾部空格;utf8mb4_0900_ai_ci具有“NO PAD”属性,不会忽略尾部空格,如下例:
-- 1. 具有'PAD SPACE'属性的utf8mb4_general_ci认为'a '='a'
mysql> SELECT 'a ' = 'a' COLLATE utf8mb4_general_ci;
+---------------------------------------+
| 'a ' = 'a' COLLATE utf8mb4_general_ci |
+---------------------------------------+
| 1 |
+---------------------------------------+
-- 2. 具有'NO PAD'属性的utf8mb4_0900_ai_ci认为'a '!='a'
mysql> SELECT 'a ' = 'a' COLLATE utf8mb4_0900_ai_ci;
+---------------------------------------+
| 'a ' = 'a' COLLATE utf8mb4_0900_ai_ci |
+---------------------------------------+
| 0 |
+---------------------------------------+
utf8mb4_general_ci基于UCA 4.0.0,utf8mb4_0900_ai_ci基于UCA 9.0.0,UCA 9.0.0具有更多的字符权重定义,对于非BMP平面字符,utf8mb4_0900_ai_ci也会为它们计算生成不同的权重,utf8mb4_general_ci则会认为这些字符全部相等,如下例:
-- 在基于UCA 4.0.0的utf8mb4_general_ci看来,'𠀫'和'𠀪'相等
mysql> select _utf8mb4'𠀫' collate utf8mb4_general_ci = '𠀪';
+----------------------------------------------+
| _utf8mb4'?' collate utf8mb4_general_ci = '?' |
+----------------------------------------------+
| 1 |
+----------------------------------------------+
-- 在基于UCA 9.0.0的utf8mb4_0900_ai_ci看来,'𠀫'和'𠀪'不等
mysql> select _utf8mb4'𠀫' collate utf8mb4_0900_ai_ci = '𠀪';
+----------------------------------------------+
| _utf8mb4'?' collate utf8mb4_0900_ai_ci = '?' |
+----------------------------------------------+
| 0 |
+----------------------------------------------+
- • 在应用的测试阶段,就应该测试好客户端所使用的编码,以及与服务端建连后是否正确设置了character_set_client、character_set_results变量,否则很容易出现乱码的情况;
- • 一般情况下character_set_client、character_set_results、character_set_connection可以统一,使用SET NAMES命令可以一次性设置完成;
- • 如果字符串字面量前有Introducer,那么解析器不会将该字符串转为character_set_connection指定的字符集,而是认为字符串使用Introducer指定的字符集,但如果客户端字符集和Introducer字符集不一致,Introducer不会对原始字符串进行字符集转换,这时字符串的二进制编码与字符集不匹配,很可能产生乱码;
- • MySQL中表名、列名等元数据使用的是utf8mb3字符集,仅支持Unicode BMP平面字符,不要在这些元数据信息中使用辅助平面字符;
- • 字符集A转换为字符集B时,不兼容的字符会被MySQL转换成'?',这有可能导致唯一键冲突;
- • 在绝大多数情况下,utf8mb4字符集搭配其默认的utf8mb4_0900_ai_ci Collation就可以满足需求,但作为中文用户如果不希望看到英文字母和很多特殊字符相等的情况,可以追加使用utf8mb4_0900_as_ci或utf8mb4_0900_as_cs完成不同层次的过滤;
- • 如果目标是字节序列完全相同,可以使用utf8mb4_0900_bin Collation,既能在比较时直接使用字节进行比较,具有更好的性能,同时又可以使用utf8mb4这种非binary字符集上的UPPER()、LOWER()等辅助函数;
- • 当不确定某个Collation上两个字符串的排序顺序时,可以使用WEIGHT_STRING函数看看字符串的Sort Key,来确定该Collation的表现是不是符合自己的预期;
- • 当多元操作符进行字符串比较时,如果输入字符串并不是来自一个Charset或使用不同的Collation,将会根据一些规则选择最终使用的Collation,并发生字符集转换,如果不熟悉这些规则,最好加上COLLATE子句明确自己想用的Collation;
- • 二进制字符集的字符串可以不加变换逐字节转为非二进制字符集的字符串,这也可能导致乱码,因此使用INSERT语句的时候,谨慎使用b、X前缀将二进制字符串字面量插入到非二进制字符集的列中。
作者简介
张熙哲,AliSQL研发人员。目前主要从事AliSQL性能优化相关的研发工作和RDS运维工作。
引用链接
[1] Charset: https://dev.mysql.com/doc/refman/8.0/en/charset.html
[2] UCA 9.0.0: http://www.unicode.org/Public/UCA/9.0.0/allkeys.txt
[3] UCA 5.2.0: http://www.unicode.org/Public/UCA/5.2.0/allkeys.txt
[4] UCA 4.0.0: http://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt
[5] Unicode: https://en.wikipedia.org/wiki/Unicode
[6] UTF-8: https://en.wikipedia.org/wiki/UTF-8
[7] Unicode联盟: https://home.unicode.org/
[8] 汉字的码点空间: https://www.zhangxinxu.com/study/201611/chinese-language-unicode-range.html
[9] 基本汉字: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=4E00-9FA5
[10] 基本汉字补充: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=9FA6-9FCB
[11] 扩展A: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=3400-4DB5
[12] 扩展B: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=20000-2A6D6
[13] 扩展C: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2A700-2B734
[14] 扩展D: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2B740-2B81D
[15] 康熙部首: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2F00-2FD5
[16] 部首扩展: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2E80-2EF3
[17] 兼容汉字: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=F900-FAD9
[18] 兼容扩展: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2F800-2FA1D
[19] PUA(GBK)部件: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=E815-E86F
[20] 部件扩展: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=E400-E5E8
[21] PUA增补: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=E600-E6CF
[22] 汉字笔画: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=31C0-31E3
[23] 汉字结构: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=2FF0-2FFB
[24] 汉语注音: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=3105-3120
[25] 注音扩展: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=31A0-31BA
[26] 〇: https://www.zhangxinxu.com/study/201611/show-character-by-charcode.php?range=3007
[27] DUCET(Default Unicode Collation Element Table): https://www.unicode.org/Public/UCA/9.0.0/allkeys.txt
[28] 复杂字符分解(decomposition)的规则: https://www.unicode.org/reports/tr15/tr15-44.html










