上次跟Y叔联手推出createKEGGdb后,反响热烈,感谢大家的支持。但是上次的包只能下载一个物种,能不能批量下载我们所需的多个物种,甚至将所有的物种都下下来呢?
必须可以!
首先安装createKEGGdb包:
remotes::install_github("YuLab-SMU/createKEGGdb")
指定需要下载的多个物种:比如拟南芥("ath")和人("hsa")(具体物种和缩写的对应关系可以查看KEGG的API:http://rest.kegg.jp/list/organism)。
library(createKEGGdb)
species "ath","hsa")
create_kegg_db(species)
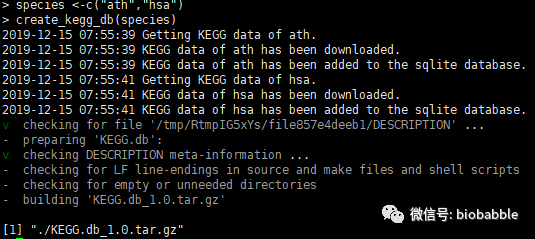
测试一下刚刚生成的KEGG.db包:
install.packages("./KEGG.db_1.0.tar.gz", repos=NULL)
library(KEGG.db)
library(clusterProfiler)
data(geneList, package="DOSE")
gene 2]
kk organism = 'hsa',
pvalueCutoff = 0.05,
qvalueCutoff = 0.05,
use_internal_data =T)
nrow(kk)
head(kk)
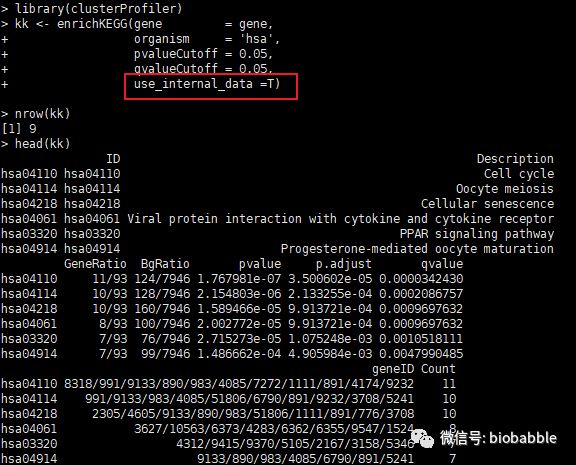
得到的结果跟上一篇推送
《KEGG数据本地化,再也不用担心网络问题了》
是一样的。
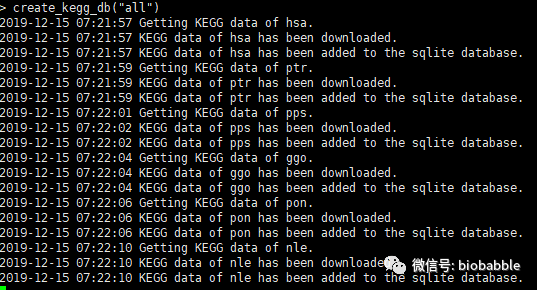
如果想下载KEGG上
所有物种
的做富集分析所需的信息怎么办?
create_kegg_db("all")
最后补充一点:有一些物种信息,虽然KEGG的物种列表(http://rest.kegg.jp/list/organism)里有,但是对应的pathway相关信息其实是没有的,这种情况程序会自动跳过。另外,网络或者服务器问题,以至于数据没下载下来,也会出现同样情况。