FPGA 芯片领域顶级会议 FPGA 2017 于 2 月 24 日在加州 Monterey 结束。在本次大会上,斯坦福大学在读 PhD、深鉴科技联合创始人韩松等作者的论文 ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA 获得了大会最佳论文奖。得知此消息后,机器之心对深鉴科技科技创始人兼 CEO 姚颂与联合创始人韩松(本论文的第一作者)进行了联系,他们对该文章进行了技术解读。可点击阅读原文下载此论文。

韩松在FPGA'17会场讲解 ESE 硬件架构
FPGA 领域顶级会议 FPGA 2017 于 2 月 24 日在加州 Monterey 结束。在本次大会上,深鉴科技论文《ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA》获得了大会最佳论文奖(Best Paper Award)。
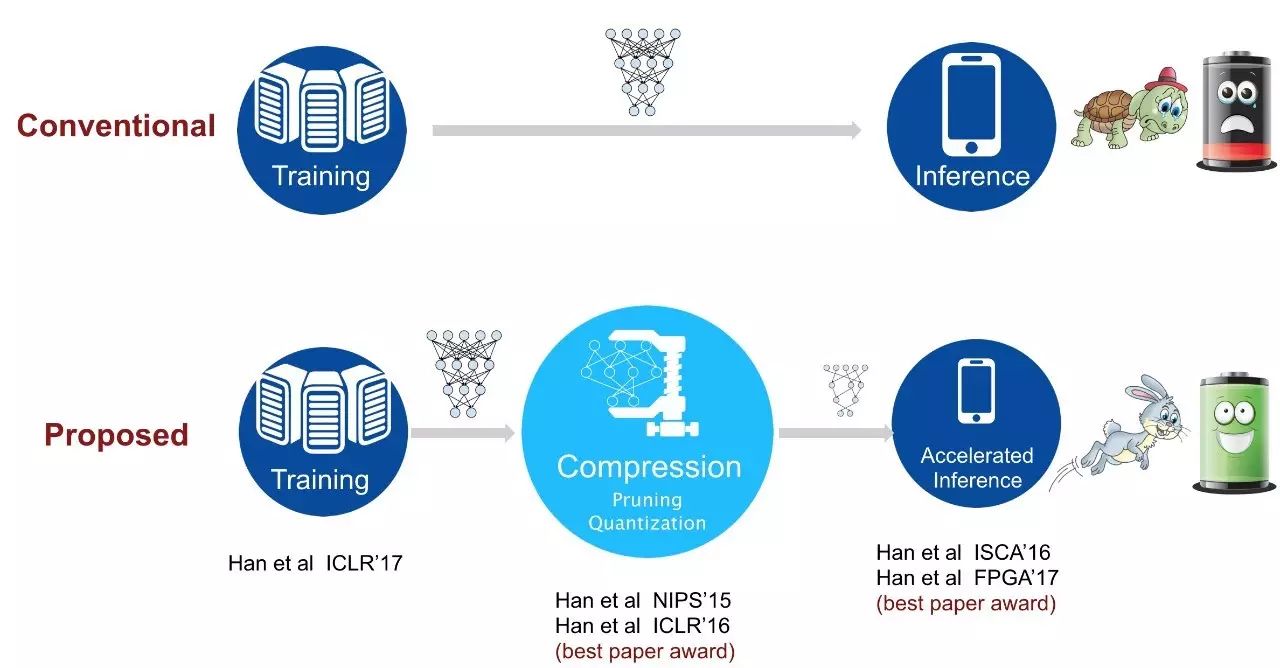
图1:韩松提出的深度学习部署方案。跟传统的「训完即用」的方案相比,「训练后经过压缩再用硬件加速推理」的方案,可以使得推理更快、能耗更低。
该项工作聚焦于使用 LSTM 进行语音识别的场景,结合深度压缩(Deep Compression)、专用编译器以及 ESE 专用处理器架构,在中端的 FPGA 上即可取得比 Pascal Titan X GPU 高 3 倍的性能,并将功耗降低 3.5 倍。而此前,本文还曾获得 2016 年 NIPS Workshop on Efficient Method for Deep Neural Network 的最佳论文提名。据悉,本文所描述的 ESE 语音识别引擎,也是深鉴科技 RNN 处理器产品的原型。
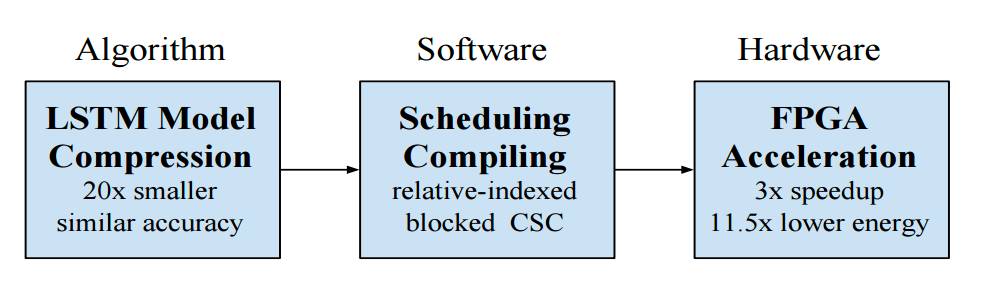
图 2:ESE 语音识别引擎工作全流程
LSTM 全称为 Long-Short Term Memory,在语音识别、机器翻译、Image Captioning中有较多的应用。对于语音识别而言,LSTM 是其中最重要一环,也是计算耗时最多的一环,通常占到整个语音识别流程时间的 90% 以上。

图 3:LSTM 在语音识别中的位置
Deep Compression 算法可以将 LSTM 压缩 20 倍以上。但在以往的纯算法压缩上,并没有考虑多核并行时的负载均衡,这样在实际运行时,实际的运行性能被负载最大的核所限制。本文提出了一种新的 Load Balance Aware Pruning,在稀疏化时保证剪枝后分配到每个核的计算量类似,从而进一步加速的计算。
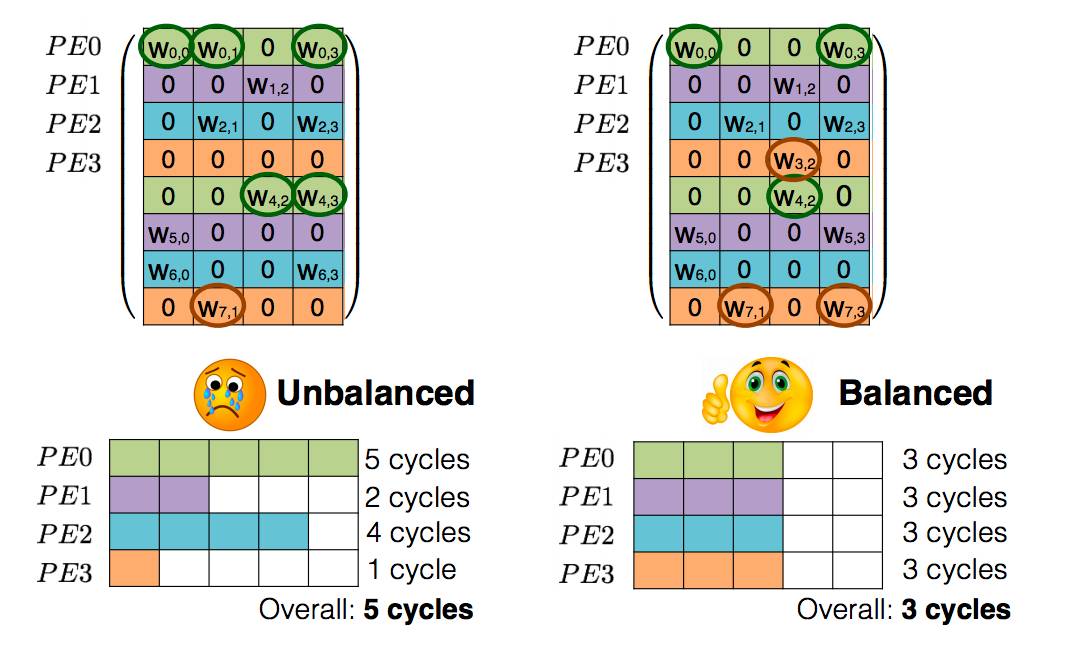
图 4:Load-Balance-Aware Pruning示意:保证稀疏性的同时保证多核负载均衡
结合新的模型压缩算法以及 ESE 专用处理架构,在一个可实际使用的 LSTM 模型上测试,相同情况下,深鉴基于中等 FPGA 平台的耗时为 82.7us,功耗为 41W;而 Pascal Titan X GPU 则需要 287.4us 的运行时间,并且耗能 135W。这也再次证明了稀疏化路线的作用:在价格、资源全面弱于 GPU 的专用硬件上,通过算法与硬件的协同优化,的确可以取得更好的深度学习运算能力。
深鉴科技成立于 2016 年 3 月,创始成员来自清华大学和斯坦福大学,公司致力于结合深度压缩与深度学习专用处理架构,提供更高效与便捷的深度学习平台。
公司聚焦于稀疏化神经网络处理得技术路线,提出的 Deep Compression 算法可以将模型尺寸压缩数十倍大小而不损失预测精度,并结合专用的深度学习处理架构来实现加速。而 ICLR 2016 和 FPGA 2017 两篇最佳论文的获奖,也证实深鉴科技所聚焦的稀疏化路线越来越得到深度学习界的关注。

摘要:长短期记忆网络(LSTM)被广泛用于语音识别领域。为实现更高的预测精度,机器学习研究者们构建了越来越大的模型。然而这样的模型十分耗费计算和存储资源。部署此类笨重的模型会带数据中心来很高的功耗,从而带来很高的总拥有成本(TCO)。为了增加预测速度,提高能源效率,我们首次提出了一种可以在几乎没有预测精度损失的情况下将 LSTM 模型的尺寸压缩 20 倍(10 倍来自剪枝和 2 倍来自量化)的负载平衡感知剪枝(load-balance-aware pruning)方法。这种剪枝后的模型对并行计算很友好。另外,我们提出了可以对压缩模型进行编码和分割成 PE 以进行并行化的调度器(scheduler),并编排了其复杂的 LSTM 数据流。最后,我们设计了一种可以直接在这种压缩模型上工作的硬件框架——Efficient Speech Recognition Engine (ESE)。该框架使用了运行频率为 200 MHz 的 Xilinx XCKU060 FPGA,具有以 282 GOPS 的速度直接运行压缩 LSTM 网络的性能,相当于在未压缩 LSTM 网络上 2.52 TOPS 的速度;此外,该框架执行一个用于语音识别任务的全 LSTM 仅需 41 W 功耗。在基于 LSTM 的语音基准测试中,ESE 的速度为英特尔 Core i7 5930k CPU 的 43 倍,英伟达 Pascal Titan X GPU 的 3 倍。它的能量效率分别为以上两种处理器的 40 倍和 11.5 倍。
©本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








