1.文字功底好,逻辑清晰,喜欢独立思考;
2.英语6级及以上的英语水平,科技媒体,科技新闻,芯片设计,计算机科学,人工智能,计算机视觉,语音识别相关专业优先;
3. 学习能力快,态度好。深圳,全职。
招募宣言:科学的本质是,问一个不恰当的问题,于是通往了走向恰当答案的路。
简历投递:[email protected]
雷锋网按:本文内容来自涂图 CTO 邱彦林在硬创公开课的分享,在未改变原意的基础上进行了编辑整理。
几年前图片美颜教育了市场,到了直播时代,美颜同样成为直播平台的标配。女主播要是在直播中不能自动美颜,那只能靠更精致的妆容来补,而实时直播美颜技术恰好解决了这个问题。
目前最新的美颜技术已经发展到了 2.0 阶段,打个比方,如果美颜 1.0 只是化妆(磨皮、祛痘、肤色调整)的话,美颜 2.0 基本就能达到整容的效果——把眼睛变大,把圆脸变成瓜子脸。而实现这一效果的基础就是人脸识别。
硬创公开课特邀专攻直播美颜的涂图 CTO 邱彦林为大家讲述 《解密 AI 在直播美颜中起到哪些你看不到的作用》。

邱彦林:涂图 CTO,专注于图像技术,以及机器学习在图像处理中的实际应用。国内最早一批 Flash 开发人员,曾出版 2 本 Flash 中文技术书籍,擅长程序架构设计。
美颜中最常见的祛痘、磨皮技术原理是什么样的?
从图像处理的角度看,什么是“痘”和“斑”?
一张图像可以看作是一个二维的数据集合,其中每个元素都是一个像素点。如果将这些数据用几何的方式来呈现出来,“痘”就是和周围点差异较大的点。在图像处理领域,这个差异是通过灰度值来衡量的灰度,也叫“亮度”。灰度图,也就是黑白图。将彩色图转换为灰度图,图像的关键特征不会丢失。
事实上,人的眼睛在观察物体时,首先注意的是物体的边缘。而在一张图像里面,边缘,即与周边灰度差异较大的点。类似的,“痘”也是与周边点的灰度差异较大的点。相比色彩,人的眼睛对灰度更敏感。这也是为什么对视频进行压缩的时候,会偏向于丢弃色彩部分的数据,而尽量保留亮度数据。
磨皮祛痘,就是要平滑点与点之间的灰度差异,同时还要保持皮肤原有的一些细节。所以,美颜一般选择边界保持类平滑滤波算法。
直播美颜(动态)和图片美颜(静态)的区别在哪里?动态美颜要解决哪些技术难题?
最重要的区别在于:直播美颜要求实时处理,而静态的图像处理对实时性没有要求,比如最近比较火的 Prisma,大家会发现处理一张图像的速度可能需要 1~2 分钟,甚至更长。
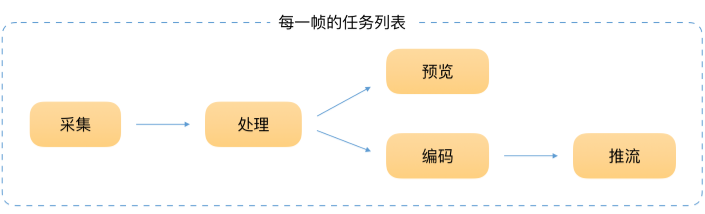
直播的实时性,最直接的体现就是在很短的时间内,完成系列任务。所以直播中的美颜,对性能有很高的要求,无法使用特别复杂的算法。我们只能在算法和美颜效果之间找个平衡点。
在图片处理应用中,没有实时性的要求,所以对算法没有什么限制。只要能实现好的效果,再复杂的算法也可以用。
在第一个问题中,我也提到了边界保持类平滑滤波算法。这类算法有很多种,但在直播中一般均选择双边滤波算法。这个算法性能高,效果也比较好,非常适合直播场景。除了磨皮算法外,调整皮肤肤色也是美颜的一个关键环节。关于调整肤色:一方面实现美白、红润的效果;另一方面则通过控制肤色,可以弱化“痘”和“斑”等,因为磨皮算法只能在一定程度上消除噪点。调整肤色个环节,还能够让设计人员参与进来,来设计出更符合我们审美观的效果来。
如何解决美颜后画面像素变差的问题,可通过什什么办法在保证美颜效果和画质之间的平衡?
从技术上讲,美颜和画质没有关系。直播的画质由主播端的输出码率决定,码率越高,画质越好,反之越差。 一般来说,在直播应用中,主播端输出的码率是固定的,或者说限制在一定范围内。如果网络情况好,输出的码率高,反之则低。目前主流的直播平台都采用 RTMP 协议,采用其它技术比如 webRTC。此外直播画质和直播平台的稳定性也有一定关系。
如何实现直播时添加脸部贴图,甚至实时整容:如把眼睛变大,把圆脸变成瓜子脸?
这类效果的核心是人脸识别技术。在直播时,从相机采集到每一帧的画面,然后进行人脸识别,再标示出关键点的位置,结合图像技术得到最终的效果。
我先深入讲下人脸识别,目前在人脸识别领域可分为机器学习与深度学习两类方案。
机器学习方案:
机器学习识别物体是基于像素特征的我们会搜集大量的图像素材,再选择一个算法,使用这个算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。
深度学习方案:
深度学习与机器学习不同的是,它模拟我们人类自己去识别人脸的思路。比如,神经学家发现了我们人类在认识一个东西、观察一个东西的时候,边缘检测类的神经元先反应比较大,也就是说我们看物体的时候永远都是先观察到边缘。就这样,经过科学家大量的观察与实验,总结出人眼识别的核心模式是基于特殊层级的抓取,从一个简单的层级到一个复杂的层级,这个层级的转变是有一个抽象迭代的过程的。
深度学习就模拟了我们人类去观测物体这样一种方式,首先拿到海量数据,拿到以后才有海量样本做训练,抓取到核心的特征建立一个网络。因为深度学习就是建立一个多层的神经网络。有些简单的算法可能只有四五层,但是有些复杂的,谷歌里面有一百多层,不同的层负责不同的处理方式,如磁化层等等。
当然这其中每一层有时候会去做一些数学计算,有的层会做图象预算,一般随着层级往下,特征会越来越抽象。比如我们人认识一个东西,我们可能先把桌子的几个边缘抓过来,结果每个边缘和轮廓组成的可能性都很多。基于轮廓的组成,我们可把这个桌子抽象成几层,可能第一层是这里有个什么线,然后逐渐往下抽象程度会由点到线到面,或者到更多的面等等这样的过程。这是一个抽象的过程。
机器学习方案和深度学习方案的区别:
而这两种“学习”的区别,举个例子来说:比如要识别具体环境中的人脸,如果遇到云雾,或者被树遮挡一部分,人脸就变得残缺与模糊,那基于像素的像素特征的机器学习就无法辨认了。它太僵化,太容易受环境条件的干扰。
而深度学习则将所有元素都打碎,然后用神经元进行“检查”:人脸的五官特征、人脸的典型尺寸等等。最后,神经网络会根据各种因素以及各种元素的权重,给出一个经过深思熟虑的猜测,即这个图像有多大可能是张人脸。
移动平台上用深度学习替换机器学习算法:
具体到应用层面,在移动设备上,采用机器学习进行人脸识别,是目前的主流做法。将深度学习迁移到移动设备上,这算是时下的研究热点。深度学习的效果很好,但是前提是建立在大量的计算基础上。虽然现在的手机硬件性能已经很好,但如果要运行深度学习的模型,手机的电量会是个问题。
据我了解,目前已经有一些公司已经成功在手机上实现了低能耗的深度学习算法。目前我们也在做相关研究,在移动平台上用深度学习替换机器学习算法。
再回到直播中的给人脸实时贴图或者“整容”,实现这一效果主要应用我上面提到的人脸识别技术,检测并识别出人脸的关键点再进行图像处理即可。
改变眼睛和脸型涉及到美丑的问题,如何让计算机懂得“审美”?
改变眼睛与脸型这类美颜,因为要涉及到人脸识别的问题,就像我刚才说的原理,非常复杂,对计算量的要求也非常大。
目前这类美颜一般都是基于机器学习的,参数在编写程序时已经确定好,并没有计算机“自己”调整的过程。所以,目前的美颜的“美”,都是我们人为的来控制。当然,这个人为也不是说程序员自己可以随便编,而是要与美工人员共同参与来完成的。
举例来说:在一些比较专业的图象处理论坛里面,有设计师会发一些经过处理的美女图片来。一般是发张原图,发张经过处理之后出来一个效果图,原图跟效果图之间有个差异,我们可以通过技术手段得到这个差异。然后把这个差异应用在我们做美肤里面去,这就是调整肤色的做法。
图片跟图片之间可以通过一些手法去模拟到这个效果,这中间的过程都是可以计算出来的。然后在滤镜、PS,或者是图象处理里的一项技术,去控制一张图片的颜色表现。通过把技术人员跟美工人员结合起来,技术只管技术,美工只管美工,这样就能够开发与设计结合起来,实现所谓的“美”。
所以你看很多平台算法都大同小异,但是为什么最终出来的美颜效果让人感觉还是有差异,其实就是说里面有很多细节在,需要花时间优化,特别是用户的需求是什么,怎样更漂亮。
未来深度学习的技术更为成熟时,电脑也许就可以凭借海量的数据来总结出美来,进而按这种总结出的“审美”来处理图像。但话说回来,“美”终究还是一种很主观的事,就像之前有人通过大量美女图片合成过各个国家标准的美女脸来,还是很多人觉得不好看,就是这个原因。
直播美颜目前面临最大的技术难题是什么?
暂时没有很大的技术难题,Android 设备适配可以算一个。由于 Android 设备和系统类型较多,导致在 Android 平台上,直播美颜很难做到兼容所有设备。Android 直播,从技术上分为硬编和软编两种方案。
硬编:即采用硬件加速,通过 GPU 进行视频编码。特性是省电、性能好,是目前最佳的方案。但无法支持个别机型。Android 4.3 + 以上的系统才支持这个方案。(这其实不是问题了,现在主流的设备都是 Android 5.0 以上);另一方面,一些厂商在硬件层和软件层做适配时,缺乏相关支持。
软编:通过 CPU 进行视频编码,比较耗电、性能差,但能兼容绝大部分设备。主流的直播平台一般是根据进行来自动适配,保证最佳效果。
群友问答环节
美颜技术如何嵌入在硬件中,如美图手机和卡西欧自拍神器?
美图手机使用的是 Android 系统,在软件层面,和一般的应用开发应该是相似的:也就是开发一款拍照应用,通过调用系统 API 访问相机,采集到画面,然后通过美颜处理。
在 Android 平台一般使用 OpenGL ES 进行图像处理。在 OpenGL ES 中编写算法,实现效果,最后将处理的结果传输给 CPU,然后生成最终的照片。
至于卡西欧自拍神器,据我所知这个应该使用的是厂商自己的系统。我分析整个运行流程和 Android 系统相似。它的效果比较好,除了算法之外,在硬件上应该也有自己独特的处理元件。
动态美颜怎么保证在时序下不同角度的同一人物的美颜效果相同?
这个没法保证。不过,不同角度、不同光照使得人物看起来本来就是不同的效果。
运动物体检测 + 跟踪,然后把人脸部分单独提取出来做美化,这样做对于性能的要求是提高了还是会降低?
一般都没有把人脸单独提取出来做美化,美化是通过肤色检测来确定美颜范围的。运动物体检测 + 跟踪,指的是人脸检测吗?如果是,对性能的要求肯定是提高了。如果要追踪的比较紧,需要每帧都做检测,性能要求肯定是非常高,以毫秒计。
双边滤波的多数实现似乎也无法达到实时性的需求,请问这里有什么 trick 吗?
主要是性能优化吧,比如一般图像卷积处理,是选周围 8 个点,可以减少为 4个。OpenGL ES 脚本按顺序执行,我们需要逐点处理,减少处理的点,这样速度会提上去。GPUImage 开源库里有可参考的代码。
深度学习类算法应用于哪些方面呢?相比传统的基于特征的算法,性能差距至少是两个数量级吧?
深度学习采用的多层神经网络,运算量大,相比传统的机器学习算法,一般来说,差距至少是好几个数量级,这个和网络结构、层级等有直接关系。应用的范围很广,包括图像识别、语音识别、翻译、数据挖掘等。
在移动设备上,使用深度学习来实现一些图像识别的功能,这是时下的一个研究热点。前段时间 Caffe 的作者在手机上实现了实时处理视频添加类似 Prisma 的网络结构,使用的是经过优化的 Caffe2 版本。随着手机硬件越来越高,在上面跑多层神经网络逐渐成为可能,甚至是实时处理都已经不是问题。
iOS 9 开始,苹果就提供了深度学习 API ,在 iOS 10,相关 API 得到更新。可以理解为, iPhone 7 以后,进行深度学习的开发,已经逐渐成熟了。