日前,机器之心介绍了
一种压缩手机端计算机视觉模型的方法
。在这篇文章中,我们介绍了一篇论文,介绍和对比了手机端语言模型的神经网络压缩方法。
神经网络模型需要大量的磁盘与存储空间,也需要大量的时间进行推理,特别是对部署到手机这样的设备上的模型而言。
在目前的研究中,业内已有多种方法解决该难题。部分是基于稀疏计算,也包括剪枝或其他更高级的方法。总而言之,在将模型存储到磁盘时,这样的方法能够大大降低训练网络的大小。
但是,当用模型进行推理时,还存在其他问题。这些问题是由稀疏计算的高计算时间造成的。有一种解决方式是使用神经网络中不同的基于矩阵的方法。因此,Lu, Z 等人 2016 年 ICASSP 的论文提出基于使用 Toeplitz-like 结构化矩阵的方法。此外还有其他的矩阵分解技术:低秩分解、TT 分解(张量训练分解)。Yoshua Bengio 等人 2016 年 ICML 论文提出的 uRNN(Unitary Evolution Recurrent Neural Networks)也是一种新型 RNN。
在这篇论文中,来自俄罗斯三星研发机构、俄罗斯高等经济研究大学的研究人员对上述的研究方法进行了分析。首先,他们对语言模型方法进行了概述,然后介绍了不同类型的压缩方法。这些方法包括剪枝、量化这样的简单方法,也包括基于不同的矩阵分解方法的神经网络压缩。更多论文细节如下,具体信息可点论文链接查看。
论文:Neural Networks Compression for Language Modeling

论文链接:
https://arxiv.org/abs/1708.05963
摘要:在本论文中,我们考虑了多种压缩技术,对基于 RNN 的语言模型进行压缩。我们知道,传统的 RNN(例如基于 LSTM 的语言模型),要么具有很高的空间复杂度,要么需要大量的推理时间。对手机应用而言,这一问题非常关键,在手机中与远程服务器持续互动很不合适。通过使用 Penn Treebank (PTB)数据集,我们对比了 LSTM 模型在剪枝、量化、低秩分解、张量训练分解之后的模型大小与对快速推断的适应性。
3. 压缩方法统计
3.1 剪枝与量化
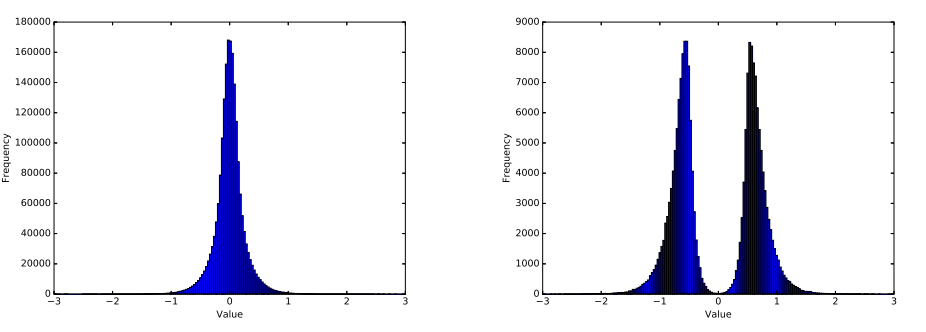
图 1:剪枝前后的权重分布
3.2 低秩分解
3.3 TT 分解法(张量训练分解)
4. 结果
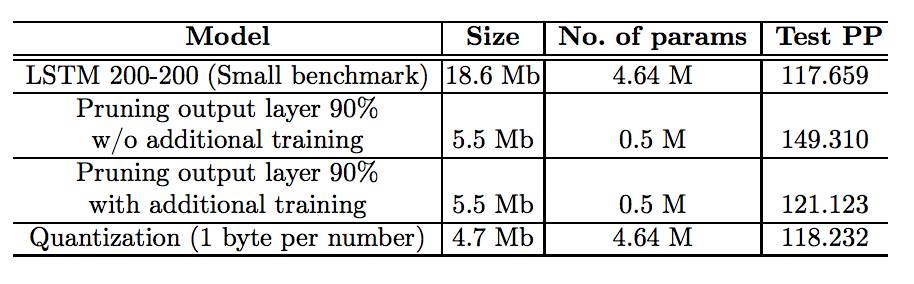
表 1:在 PTB 数据集上的剪枝和量化结果
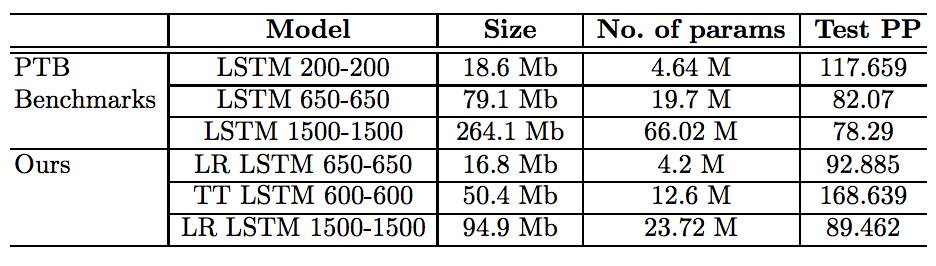
表 2:在 PTB 数据集上的矩阵分解结果
5. 结论
在此论文中,我们考虑语言模型神经网络压缩的多种方法。文章第一部分介绍剪枝与量化方法,结果显示这两种技术应用于语言模型压缩时毫无差别。文章第二部分介绍矩阵分解方法,我们演示了在设备上实现模型时,这些方法的优势。移动设备任务对模型大小与结构都有严格的限制。从这个角度来看,LR LSTM 650-650 模型有更好的特性。它比 PTB 数据集上的最小基准还要小,且其质量可与 PTB 上的中型模型媲美。

本文为机器之心编译,
转载请联系本公众号获得授权
。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]





