强化学习(RL)和生成对抗网络(GAN)都是近来的热门研究主题,已经在许多领域得到了非常出色的表现。近日,伯克利和 OpenAI 的一项新研究将这两者组合到了一起。在一篇名为《用于强化学习智能体的自动目标生成(Automatic Goal Generation for Reinforcement Learning Agents)》的论文中,研究者提出了一种让智能体可以自动发现目标的方法。机器之心对该论文进行了摘要介绍,论文原文请参阅:https://arxiv.org/abs/1705.06366

强化学习是一种训练智能体执行任务的强大技术。然而,强化学习训练的智能体只能通过其奖励函数(reward function)实现单一任务,这种方法不能很好地扩展到智能体需要执行各种不同的任务集合中,例如导航到房间的不同位置或将物体移动到不同位置。相反,我们提出了一种允许智能体自动发现其能够执行的任务范围的方法。我们使用生成器网络给智能体提出任务,然后试着实现并将其作为目标状态(goal state)。该生成器网络使用对抗训练进行优化,以产生总是处于合适难度的智能体任务。因此,我们的方法自动生成任务,以供智能体学习。我们表明,通过使用此框架,智能体可以高效自动地学习执行广泛的任务,而不需要任何预先的环境知识。我们的方法也可学习以稀疏奖励(sparse reward)来完成任务,而在以往这是重大的挑战。
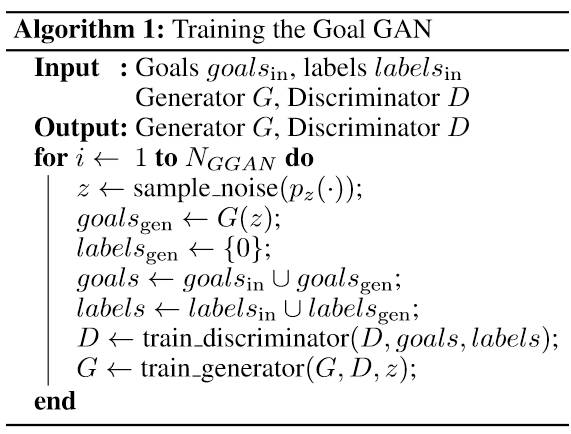
算法 1:训练目标 GAN(Goal GAN)

算法 2:生成式目标学习

图 1:我们的迷宫环境;以橙色显示的智能体必须移动到的一个目标位置(以红色显示),采样工作是在任务开始的时候开始的。迷宫墙呈灰色。
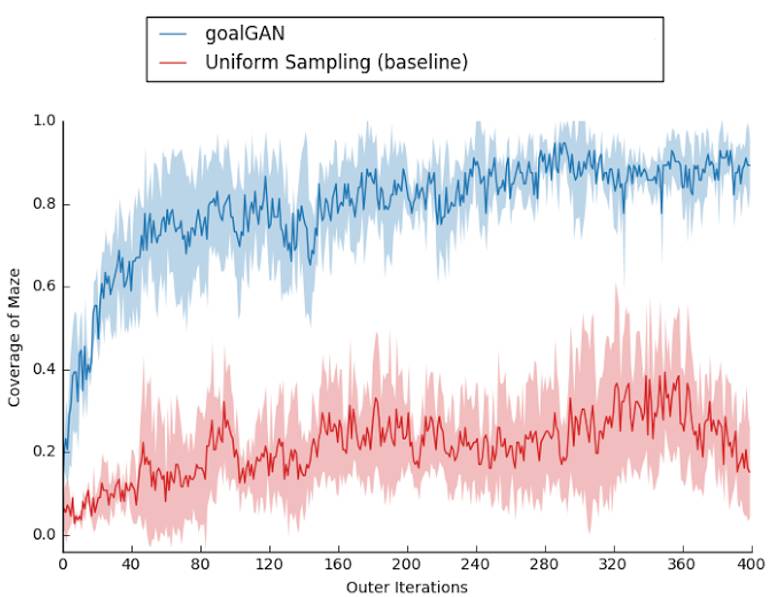
图 2:我们的方法(蓝色)和基准方法(红色)训练效率学习曲线的比较。y 轴表示迷宫中所有目标位置的平均回报,x 轴显示了新目标已被采样的次数(对于两种方法,该策略都针对相同次数的迭代进行训练),所有的点均为在 5 个随机种子(seed)上的平均值。
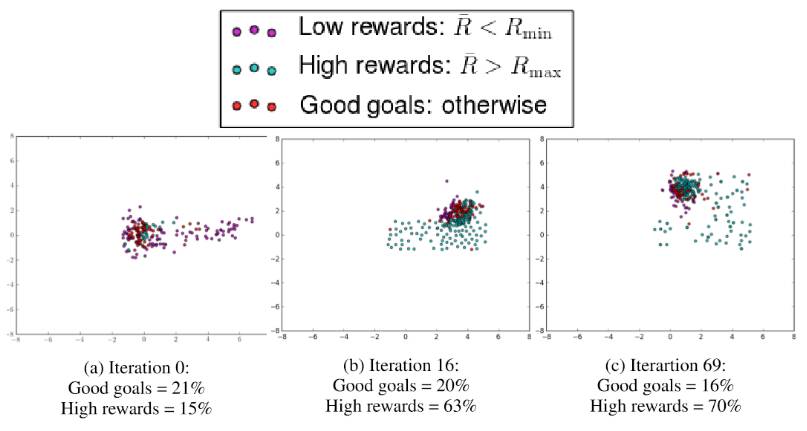
图 3:Goal GAN 采样的目标(与图 4 相同的训练方法)。当前方法与难度相适应就是「好目标」
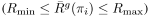 。
。
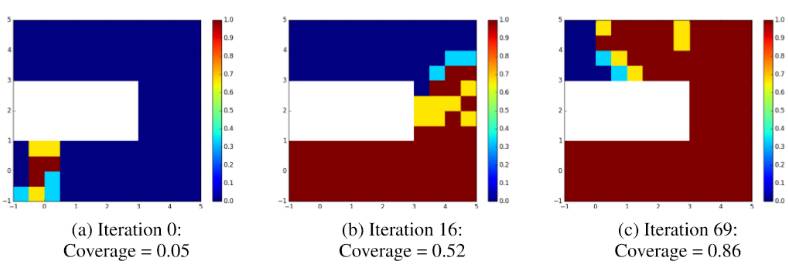
图 4:可视化状态空间不同部分的策略表现(与图 3 相同的训练策略)。说明一下,可行状态空间(即,迷宫内的空间)被划分为网格,并且从每个网格单元的中心选择目标位置。每个网格单元根据此目标实现的预期回报进行着色:红色表示 100% 的成功,蓝色表示 0% 成功。
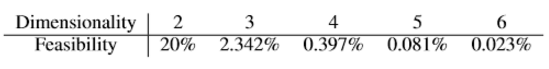
表 1:在完整的状态空间中可行目标的百分比
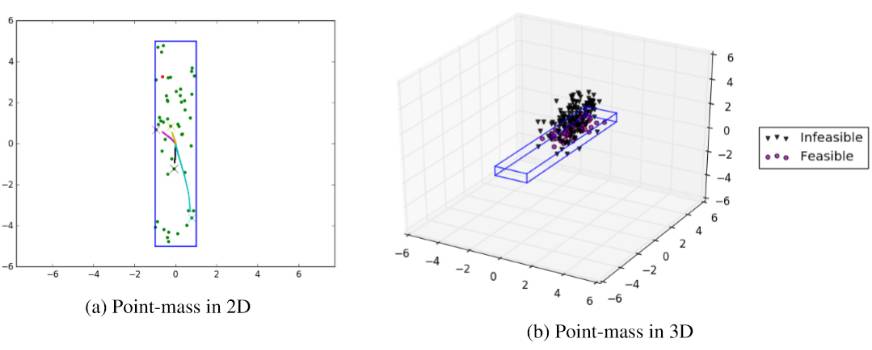
图 5:二维和三维点质量的可视化,可行区域以蓝色界定。在(a)中的点是均匀采样的可行位置。如果智能体可以到达它们,则点为绿色,否则为红色。图中的线是观察到的特定推出,并且颜色匹配交叉是智能体在每种情况下试图达到的特定目标。在(b)中,我们通过 Goal GAN 绘制初始采样生成,采用我们的技术初始化生成器。










