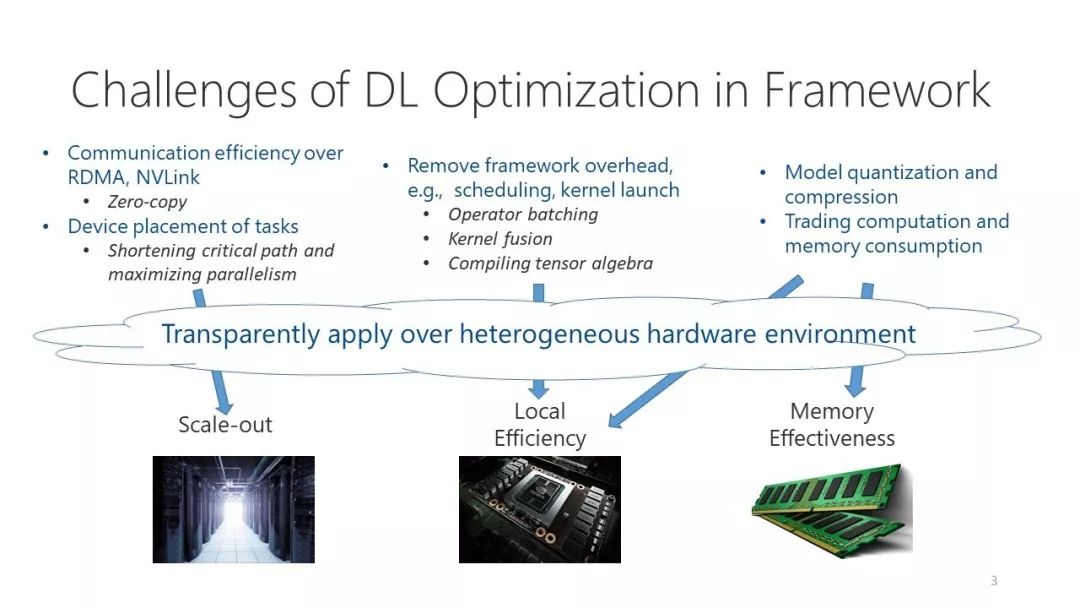
目前,优化深度学习的计算存在以下几个主要的挑战:
事实上,任何方面的优化问题都可以从模型算法和系统两个角度来看待。一方面,我们可以通过改变模型和算法来优化其对计算资源的使用效率从而改进其运行速度。这样的优化对特定的算法往往非常有效,但却不容易扩展应用到其它算法中。而另一方面,也就是微软亚洲研究院异构计算组正在进行的研究,则是在系统中实施模型算法无关的优化,这样的优化,通常可以为更多的应用带来性能的好处,同时也符合我们在前文提到的透明性的要求。
以系统优化助力深度学习计算
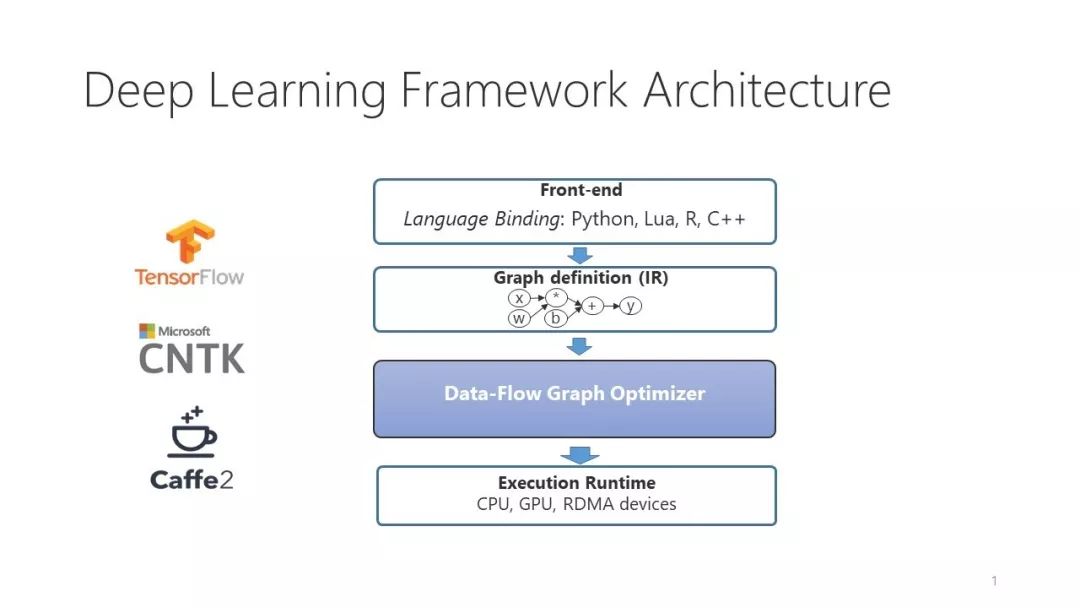
为了能够更好地理解系统这一层面的优化,我们先来简单介绍一下深度学习框架系统的背景知识。当今工业界流行的深度学习系统(包括TensorFlow、PyTorch、CNTK、MxNet、Caffe等)大都采用分层的体系结构设计。在前端提供高级语言(例如Python)的接口抽象,允许用户方便地描述神经网络结构,也就是深度学习的模型。描述好的模型在被系统运行前,首先会被转换成数据流图(Data-flow Graph)。在这个数据流图中,节点是特定的矩阵操作(也就是Operator,如Sigmoid、Matrix Multiplication等),而连接不同节点的边则是操作节点的输入和输出矩阵。这个数据流图也可以被看成是深度学习计算的中间表达。然后,深度学习系统的后端将这个数据流图映射到实际硬件上进行高效地执行,而大部分系统层面的优化就是在这个阶段完成的。
分布式训练的主要瓶颈在于多机之间的通信开销。如今计算机网络的硬件技术已经有了很大的发展,InfiniBand的RDMA网卡(Remote Direct Memory Access,这是一种硬件的网络技术,它使得计算机访问远程的内存时无需远程机器上CPU的干预)已经可以提供50~100Gbps的网络带宽和微秒级的传输延迟。目前许多以深度学习为目标应用的GPU机群都部署了这样的网络。然而深度学习系统如何才能充分利用好硬件提供的通信能力使分布式的训练获得更大的性能提升呢?另外,使用RDMA的软件接口进行通信能够绕过TCP/IP协议栈,减少了操作系统内核态的运行开销。在这样的网络通信技术的支持下,任何与通信相关的计算处理的开销都会变得非常显著,而这正是许多原先基于TCP/IP而设计的网络通信机制中所存在的问题。
RPC(Remote Procedure Call,远程过程调用)是一个被广泛使用的多机之间的通信抽象原语,它的主要设计目标是通用性。在没有考虑RDMA的情况下,很多深度学习框架都会采用RPC的机制(例如gRPC)来实现多机之间的通信。然而,RPC需要维护一个内部的私有缓存,从而不得不引入用户数据的存储空间和内部缓存之间的数据拷贝。这种内存拷贝的开销在使用RDMA网络的情况下会变得非常明显。我们通过micro-benchmark观察到,跟使用基于TCP/IP的gRPC相比,直接通过RDMA的接口传输消息(对不同的消息大小)可以有2到10倍的性能提升。
那么针对深度学习的应用负载,如何才能更好地利用RDMA硬件的能力?首先,我们来分析一下深度学习应用的几个特点:
基于以上几个特点,我们可以对数据流图进行分析,找到那些可以静态决定shape信息的Tensor,以便在运行前,在接收端预先为其分配RDMA可访问的内存空间,并将其相应的可远程访问的地址传送给发送端。这样一来,在运行时,发送端可以通过单边的RDMA请求将Tensor的数据直接传输到接收端,从而完全避免了没有必要的额外内存拷贝,达到零拷贝的通信过程。我们将这种机制在TensorFlow上进行实验, 和基于TCP/IP的gRPC相比,这一方法在一系列典型模型上均取得了多倍的性能改进。甚至和针对RDMA优化过的gRPC相比,我们的方法仍然能够取得超过50%的性能提升。
另外,我们在分布式深度学习方向上关注的另一个问题是如何自动地对资源无关的数据流图做优化的分布式执行,也就是自动划分数据流图中的计算任务并为其分配相应的计算资源,以使计算效率最优化。Google的Jeff Dean团队在这个方向上已经做了很好的先驱性工作。但局限于模型并行和单机多卡的运行环境,目前这仍然是一个非常重要并且大有可为的方向,需要结合数据并行,分布式及异构环境来综合考虑。
2. 提升单个计算单元的运算效率
前面提到过,使用深度学习框架来实现的模型算法,在运行时前会被转换成数据流图。不少具有实际应用价值的模型都非常复杂,由它们所转换出来的数据流图通常是由成千上万的操作节点构成,其中包含了很多运算量非常小的节点,也就是说它们的输入矩阵的大小很小,或者是其计算逻辑的复杂度相对于对输入数据访问的复杂度来说很低。大量这样的操作节点会引入以下一些运行时开销,并且这样的开销会非常显著。
解决这一问题的主要思路是内核融合(Kernel Fusion)。一些手工的优化方法就运用了这一思想,比如NVIDIA基于CuDNN的RNN库函数。它把整个循环神经网络实现成一个GPU的内核函数,因此获得了非常好的性能。然而它的缺点也非常明显,那就是不够灵活和通用,无法应用在其它网络或一些变种的循环神经网络中。而我们更加关注的是如何在深度学习的系统中自动地对任意的网络模型实施优化。
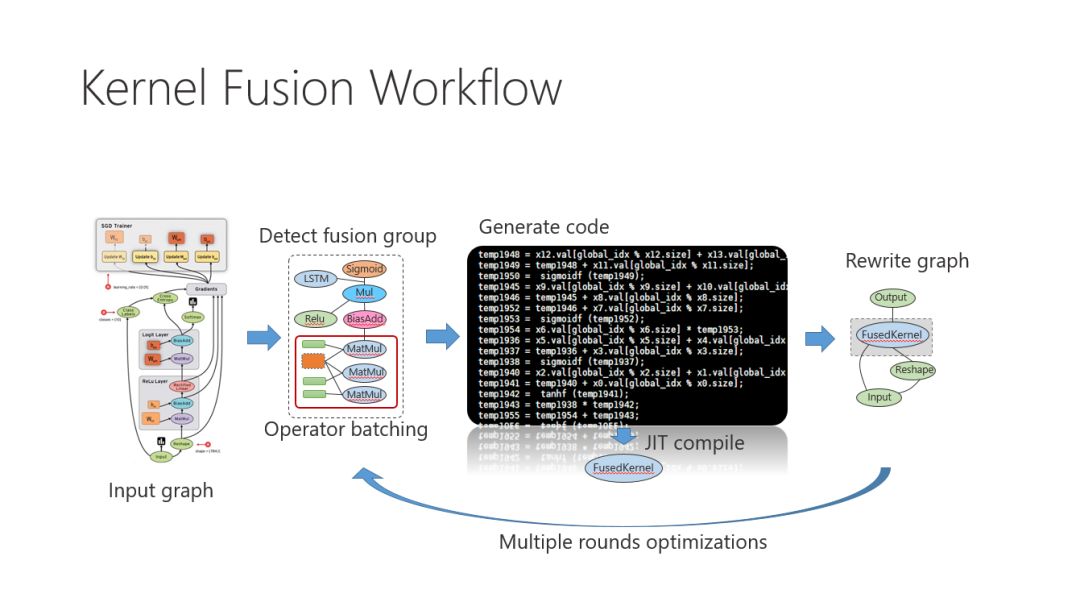
目前在学术界和工业界已经存在一些系统采用编译的方法生成融合的内核代码,比如TVM、Halide和Taco等。这些系统使用Tensor Algebra作为前端表示方法,每个Tensor Algebra表达式进而可以被编译成相应的内核代码。而Tensor Algebra可以作为更低一层的中间表达被集成到深度学习系统中,也就是说高层的数据流图可以先转换成由Tensor Algebra表达式组成的代码块,再被编译成可执行的代码。然而,这些系统对于可以进行融合的操作节点有很多限制,不能很好地融合多个非pointwise的操作,例如多个矩阵乘操作。然而,我们发现如果打破这一限制从而融合更多操作节点是可以带来更多显著的性能提升的。
在GPU的运行环境下融合多个非pointwise的操作具有一定的挑战性,因为非pointwise的操作中输入矩阵的每个元素都可能依赖于前一个操作的输出矩阵中的许多不同位置的元素值,所以在这两个操作之间需要插入Barrier同步原语。而在GPU中实现Barrier需要保证该内核的所有线程块在运行时都是保持活动状态的,这意味着我们必须要求融合后的内核采用有限个数的线程块,但同时又能够处理远超过线程块数量的数据块。
为了解决这一问题,我们尝试采用persistent-thread的线程块模型,也就是说在融合后的内核的整个生命周期启动固定数目的线程块并让它们保持活动状态。我们的优化系统在产生融合的内核代码的过程中类似于解决一个装箱(bin-pack)问题,即把待融合的子数据流图中的每一个操作节点所要处理的数据块分派给适当的活动线程块,从而使得每个线程块的负载尽可能均衡,并且保持操作节点的运算在原数据流图中的并行性。
为了生成优化的GPU内核函数,一个重要的考虑因素是线程块和数据块的合理划分。然而这又依赖于一些非常复杂的因素,比如操作节点运算中计算和访存复杂度的比率、GPU的shared memory的大小、寄存器文件的大小及分配方法等等。因此一个最优的选择是很难通过静态的方法决定的。幸运的是,深度学习的迭代性以及需要相当多的迭代才能收敛的特性使得我们可以利用早期的迭代过程来收集运行时的动态信息以帮助优化系统做更明智的决定。
设备内存的大小往往限制了可以处理的模型规模,解决这一问题的一个思路是对模型进行压缩和量化。如今学术界和工业界已经有大量的研究工作提出不同的压缩和量化的方法,然而,在实际的应用场景中使用压缩和量化仍然是个繁琐的迭代过程。在这个过程中,用户可能会进行以下几个方面的尝试。
显然,这样一个繁琐的过程需要一个好的工具来使之变得方便。这也是我们组正在关注的一个问题。我们正在尝试扩展TensorFlow的API来使用户可以在模型脚本中直接控制量化和压缩的方法、对象、程度和过程。
压缩和量化通常是用来解决模型部署时的性能和内存资源不足的问题,而解决模型训练时内存不够的问题的思路之一是用计算来换内存。比如,如果数据流图中某一个操作节点的计算量很小,但是输出的中间结果数据量很大,一个更好的处理方式是不在内存中保存这个中间结果,而在后面需要用到它的时候再重新执行这个操作节点的计算。当然,重新计算还是引入了一定的额外开销。
事实上,还存在另外一种解决这个问题的思路,就是将大的输入数据就保存在CPU端的主存里,并将操作节点实现成流式的处理,将大的输入数据分段拷贝进GPU的设备内存,并通过异步的拷贝使得对每一分段的计算时间和下一分段的拷贝时间能够重叠起来,从而掩盖住数据拷贝的开销。对于矩阵乘法这样的操作,由于计算复杂度相对于访存复杂度较高,当分段较大的时候,计算时间和拷贝时间是可以达到完美重叠的。然而,如果所要进行的操作不是矩阵乘法,而是一些简单的pointwise操作,计算的复杂度就没有办法和内存拷贝的开销相抵消。所以这种做法还需要跟内核融合相结合。比如将矩阵乘法和后续的pointwise操作相融合,每一个分段的计算都会把该分段的矩阵乘和pointwise操作都做完,然后再处理下一个分段。
作者简介

伍鸣,微软亚洲研究院资深研究员。2007年于中科院计算所取得计算机系统结构博士学位后加入微软亚洲研究院。期间主要的研究兴趣及参与的研究方向包括分布式事务处理系统、图计算引擎和人工智能平台。近年来在多个系统领域的顶级会议(如SOSP、OSDI、NSDI、ATC、EuroSys、SoCC、VLDB等)中发表多篇论文,并担任过OSDI、ASPLOS、HotDep、MiddleWare等会议的程序委员会委员,以及SOSP’17的Publication Chair。










