昨天写了一个重删压缩承诺的文章,被骂惨。
没办法,今天继续。因为我就是喜欢各种对比,虽然你们不喜欢。
因为只有对比,我才能发现世界上还有别的实现方式,也许更好,也许更坏,但存在即合理。
还有我嘴碎,喜欢评价,给出我的意见。很多人就看不下去了,很奇怪,只是我个人意见,又不代表那个公司,至于这么激动吗?
不管了。今天我还是想讲讲AFA的在线重删压缩原理,顺便谈谈各家的实现。我们只讲在线的重删压缩,因为后处理的方式会影响闪存的寿命,不是AFA场景下的主流实现。重删压缩还有块和文件的区别,这里我们只讨论块的,因为很多AFA都不支持文件。
原理嘛,我就借用华为Dorado v3的产品文档里面对原理的描述。
重删压缩原理
原理
SmartDedupe&SmartCompression特性通过删除重复数据或对业务数据进行压缩,减少数据冗余,节省存储空间。并且通过减少对SSD盘的写入次数和数据量,提高SSD盘使用寿命。
相关概念
在了解SmartDedupe&SmartCompression特性的原理前,需要先了解相关概念:
-
重删数据块大小:用于指定存储系统进行重删的粒度。OceanStor Dorado5000 V3&Dorado6000 V3存储系统支持的重删数据块大小可以配置为8KB或4KB,默认为8KB。
-
压缩数据块大小:用于指定存储系统进行压缩的粒度。OceanStor Dorado5000 V3&Dorado6000 V3存储系统支持的压缩数据块大小与重删数据块大小一致。
-
定长重删:重删过程中,存储系统按照相同的重删数据块大小对写入LUN的数据进行重删。
-
重删域:存储系统查找重复数据块的范围。存储系统定义了两个重删域,根据LUN开启SmartDedupe和SmartCompression的状态来判断LUN所属重删域。只开启SmartDedupe功能的LUN属于一个重删域;同时开启SmartDedupe和SmartCompression功能的LUN属于另一个重删域。例如,存储系统中LUN1、LUN2、LUN3、LUN4和LUN5开启SmartDedupe和SmartCompression的状态及所属重删域的举例如表1所示。
表1
重删域划分举例
|
LUN名称
|
开启SmartDedupe和SmartCompression的状态
|
所属重删域(以下名称仅用作举例)
|
|
LUN1
|
仅开启SmartDedupe
|
重删域1
|
|
LUN2
|
仅开启SmartDedupe
|
重删域1
|
|
LUN3
|
同时开启SmartDedupe和SmartCompression
|
重删域2
|
|
LUN4
|
仅开启SmartDedupe
|
重删域1
|
|
LUN5
|
同时开启SmartDedupe和SmartCompression
|
重删域2
|
-
指纹信息:数据块的代表,是一个固定长度的二进制数值。OceanStor Dorado5000 V3&Dorado6000 V3存储系统采用弱哈希算法计算出数据块的指纹信息。存储系统为每个重删域分别保存了指纹库,用于记录该重删域中所有数据块的指纹信息和数据存储位置的映射关系。
-
逐字节比较策略:查找重复数据块时,进行指纹信息对比后,如果指纹信息一致,还会逐字节比较数据块中的数据。
-
重删元数据:保存重删处理相关信息。例如,数据块的指纹信息,重删后数据的存放位置等。
重复数据删除
OceanStor Dorado5000 V3&Dorado6000 V3存储系统实现了在线重删。如果创建LUN时对该LUN启开了重复数据删除(SmartDedupe)功能,后续存储系统会对写入该LUN的所有数据进行重复删除处理。存储系统会对新写入的数据进行数据分块,并将这些数据块与存储系统原有的数据块进行对比,如果识别出重复数据块,存储系统会删除新写入的数据块,并在指纹库中将该数据块的指纹和存储地址映射关系记录原有数据块的信息。
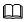 说明:
说明:
重复数据删除功能只能在创建LUN时开启或关闭,配置后不支持修改该功能。
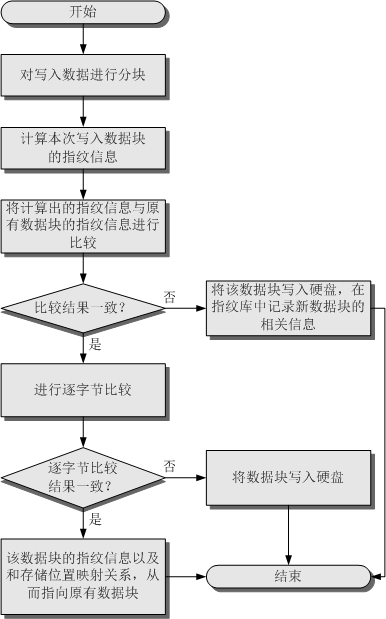
存储系统进行数据重删处理的流程如图1所示。
图1
重复数据删除流程
-
存储系统利用弱哈希算法计算新写入数据块的指纹信息。
-
对比新写入数据块的指纹信息与指纹库中的指纹信息是否一致。
通过逐字节比较结果确认新写入的数据块与原有数据块是否重复。
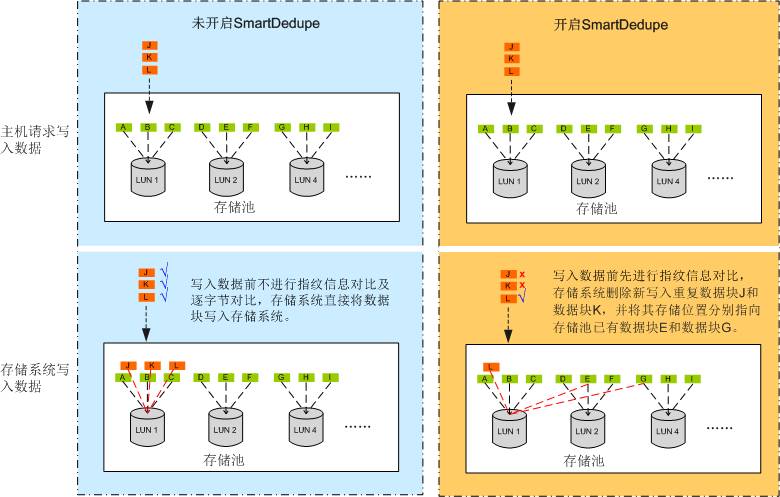
例如,存储系统中LUN1、LUN2和LUN4属于同一个重删域。LUN1、LUN2和LUN4中原有数据块,及LUN1新写入数据块J、数据块K、数据块L与原有数据的比较结果如表2所示。
表2
新写入数据块的特征
|
LUN名称
|
原有数据块
|
新写入数据块特征
|
|
LUN1
|
数据块A、数据块B、数据块C
|
-
数据块J与数据块E的指纹信息及逐字节比较结果都一致。
-
数据块K与数据块G的指纹信息及逐字节比较结果都一致。
-
数据块L与数据块F的指纹信息一致,但逐字节比较结果不一致。
|
|
LUN2
|
数据块D、数据块E、数据块F
|
-
|
|
LUN4
|
数据块G、数据块H、数据块I
|
-
|
存储系统采用不同的数据重删策略时,数据重删结果的示意图如图2所示。
图2
数据重删处理结果
数据压缩
OceanStor Dorado5000 V3&Dorado6000 V3存储系统实现了在线压缩。如果创建LUN时对该LUN开启了数据压缩(SmartCompression)功能,后续存储系统会对写入该LUN的所有数据进行数据压缩处理。存储系统会改变写入的数据块的存储格式,实现数据压缩,从而减少数据占用的存储空间。
数据压缩处理的示意图如图3所示。
图3
数据压缩处理结果

当某个LUN同时开启重复数据删除和数据压缩功能时,存储系统会对数据先进行重删,然后再对唯一数据块进行压缩后才将数据写入硬盘。
好,看完华为对原理的描述,我们来看AFA在线重删压缩的一些要点:
1、重删的粒度(即数据块的大小)和是否可变。
一般AFA都是8KB的定长重删,因为为了保证一致的时延,采用定长重删比较有优势。个别AFA采用变长重删,做得不好时延会抖动,但做得好的话一般重删比比较高,因为可以和应用I/O匹配起来。
华为Dorado v3虽然原理写支持4KB/8KB(默认)的定长重删,但是我看配置界面并不能配置重删粒度的大小。听人说可能是可以识别4KB的负载,但是还是采用8KB来生成指纹(即两个4KB合在在一起),这其实还是8KB的定长重删啊?建议改一下手册,别误导了客户。
2、重删域大小,即是全局还是局部的。
这个实现方式也很重要,即涉及效率的问题。重删域越大,重删率就越高,但是系统需要查找的指纹也就越多,处理不好可能影响重删的速度。
我看华为的实现,虽然是全局的,但又有点不像全局的。可能由于实现原因,只重删的数据是一个重删域,重删压缩都打开的数据又是一个重删域。也就是说,带压缩的和不带压缩的不能在同一个重删域里。因此,如果你想只有一个重删域,就把所有的LUN的重删压缩都打开吧,O(∩_∩)O哈哈~
业界的AFA实现,有一大半实现应该都是采用全局的重删域吧,但也有一些做不到的。
3、重删压缩是否可以选择关闭。
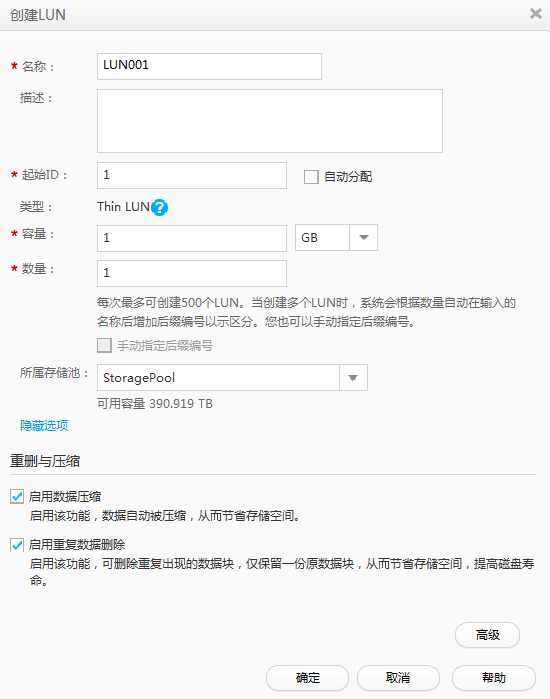
我们从华为的LUN配置界面可以看到,华为Dorado v3可以以LUN的粒度选择是否开启重删或者压缩。
有些负载是不能压缩的,如图片和视频,因此,这些数据打开压缩没有效果,纯粹浪费系统的资源。也有一些负载重删效果不明显,如数据库,数据库写数据的时候都喜欢带一个时间戳,这个时间戳不可能有重复的,因此,使得重删效率不高。因此,这样的负载一般建议关闭重删,节省系统的资源。压缩主要占用的是CPU资源,而重删除了占用CPU资源外,还会占用大量的内存资源。因为为了快速的查找,一般厂商都会把指纹放在内存或者SCM上,这些都是系统非常宝贵的资源。
4、重删的指纹冲突处理。
我们看到,华为Dorado v3采用弱hash算法生成指纹,但发现指纹一致的时候,会对数据采用位XOR来比对,确认是一样的数据才进行重删,确保没有指纹冲突的问题。
弱hash+数据比对的方法,是目前市场大部分厂商采用的方式。个别厂商为了减少数据对比这个步骤,采用强hash算法生成指纹,这样发生指纹冲突的概率很小,当然是在一定的数据量级下。
5、压缩的算法选择和实现。
压缩其实大家玩的花样不多,基本都是采用LZ算法或者其变种来实现。我记得华为选择的也是比较通用的LZ4算法。LZ算法最大的特点就是解压缩很快,这个非常重要。大家知道,写的时候可以先写到内存里,因此写时延都比较好控制,但是读的时候,现在的I/O混杂,特别是虚拟机环境,Cache的作用不明显了,这个数据解压速度对读时延就非常重要了。
虽然压缩算法都比较成熟,大家都差不多,但是在实现上,有些厂商还是做出了一些变化。比如在压缩的粒度上,有些厂商采用滑动窗口的方式实现变长压缩。有些厂商在压缩的时候会评估压缩率,如果发现压缩率不理想,会中途中断压缩,减少对系统资源的消耗。还有一些厂商把压缩分成两阶段,第一阶段采用LZO算法进行快速的压缩,然后等系统空闲再采用自己改进的算法(一般基于哈夫曼编码)来进一步压缩。特别像我们现实中的反刍动物,比如牛。