 点击 Chatbots技术与产品,快速关注本账号!
点击 Chatbots技术与产品,快速关注本账号!
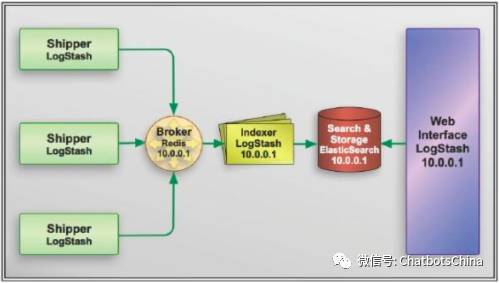
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK是Elasticsearch、Logstash、Kibana三个开源软件的组合而成,形成一款强大的实时日志收集展示系统。各组件作用如下:
Elasticsearch:日志分布式存储/搜索工具,原生支持集群功能,可以将指定时间的日志生成一个索引,加快日志查询和访问。
Logstash:日志收集工具,可以从本地磁盘,网络服务(自己监听端口,接受用户日志),消息队列中收集各种各样的日志,然后进行过滤分析,并将日志输出到Elasticsearch中。
Kibana:可视化日志Web展示工具,对Elasticsearch中存储的日志进行展示,还可以生成炫丽的仪表盘。
下图为整个系统流程图:
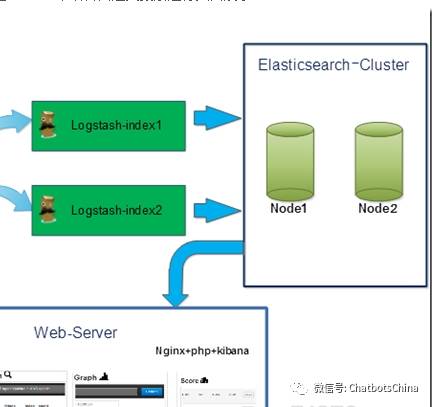
接下来我们对每个组件进行详细的介绍总结。
Elasticsearch:
在 《Elasticsearch : The Definitive Guide》里,这样介绍Elasticsearch,总的来说,Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一,Wikipedia、Stack Overflow、GitHub 等都基于 Elasticsearch 来构建他们的搜索引擎。 接下来我们具体介绍Elasticsearch的具体概念:
1. node:即一个 Elasticsearch 的运行实例,使用多播或单播方式发现 cluster 并加入。
2. cluster:包含一个或多个拥有相同集群名称的 node,其中包含一个master node。
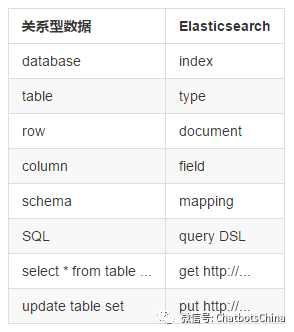
3. index:类比关系型数据库里的DB,是一个逻辑命名空间。
4. alias:可以给 index 添加零个或多个alias,通过 alias 使用index 和根据index name 访问index一样,但是,alias给我们提供了一种切换 index 的能力,比如重建了index,取名customer_online_v2,这时,有了alias,我要访问新 index,只需要把 alias 添加到新 index 即可, 并把 alias从旧的 index 删除。不用修改代码。 type:类比关系数据库里的Table。其中,一个index可以定义多个type,但一般使用习惯仅配一个type。
5. mapping:类比关系型数据库中的 schema 概念,mapping 定义了 index 中的 type。mapping 可以显示的定义,也可以在 document 被索引时自动生成,如果有新的 field,Elasticsearch 会自动推测出 field 的type并加到mapping中。
6. document:类比关系数据库里的一行记录(record),document 是 Elasticsearch 里的一个 JSON 对象,包括零个或多个field。
7. field:类比关系数据库里的field,每个field 都有自己的字段类型。
8. shard:是一个Lucene 实例。Elasticsearch 基于 Lucene,shard 是一个 Lucene 实例,被 Elasticsearch 自动管理。之前提到,index 是一个逻辑命名空间,shard 是具体的物理概念,建索引、查询等都是具体的shard在工作。shard 包括primary shard 和 replica shard,写数据时,先写到primary shard,然后,同步到replica shard,查询时,primary 和 replica 充当相同的作用。replica shard 可以有多份,也可以没有,replica shard的存在有两个作用,一是容灾,如果primary shard 挂了,数据也不会丢失,集群仍然能正常工作;二是提高性能,因为replica 和 primary shard 都能处理查询。另外,如上图右侧红框所示,shard数和replica数都可以设置,但是,shard 数只能在建立index 时设置,后期不能更改,但是,replica 数可以随时更改。但是,由于 Elasticsearch 很友好的封装了这部分,在使用Elasticsearch 的过程中,我们一般仅需要关注 index 即可,不需关注shard。
shard、node、cluster 在物理上构成了Elasticsearch 集群,field、type、index 在逻辑上构成一个index的基本概念,在使用 Elasticsearch 过程中,我们一般关注到逻辑概念就好,就像我们在使用MySQL 时,我们一般就关注DB Name、Table和schema即可,而不会关注DBA维护了几个MySQL实例、master 和 slave 等怎么部署的一样。
为了更好的理解Elasticsearch中的一些概念,下面我们将Elasticsearch中的一些概念和关系数据数做了类比:
Logstash:
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件,Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。在logstash中,包括了三个阶段:
输入input --> 处理filter(不是必须的) --> 输出output
Input:用于接收数据,可以接收三个来源的数据分别为:stdin(标准输入),socket,file
Filter:用于过滤数据主要结合grok中的正则进行过滤,如果数据格式直接为JSON格式则直接在Logstash的配置中设置codec 为JSON
Output:用于输出数据,可以输出到hdfs,file,elasticsearch(主要),stdout(标准输出)
Kibana:
Kibana 是为 Elasticsearch 设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
Kibana 让海量数据变得更容易理解。简单的基于浏览器的界面让你可以快速创建并分享动态的仪表板,用以实时修改 Elasticsearch 请求。
依据你的分析需求Kibana可以轻松为你绘制如:柱状图,折线图,扇形图以及纯表格等常用图表。当然你还可以在Kibana中进行具体日志的查询(类似sql),最后将建好的图表都展示在同一个darshboard中统一展示。
传统日志分析 VS ELK日志分析 :
传统日志分析:
1. 线上日志逐个tail+grep
2. 编写脚本,下载某个时间范围内的全部日志到本地再搜索,tail+grep或者把日志下载下来再搜索,可以应付不多的主机和应用不多的部署场景。但对于多机多应用部署就不合适了。这里的多机多应用指的是同一种应用被部署到几台服务器上,每台服务器上又部署着不同的多个应用。可以想象,这种场景下,为了监控或者搜索某段日志,需要登陆多台服务器,执行多个tail -F和grep命令。一方面这很被动。另一方面,效率非常低,数次操作下来,程序员的心情也会变糟。
ELK日志分析:
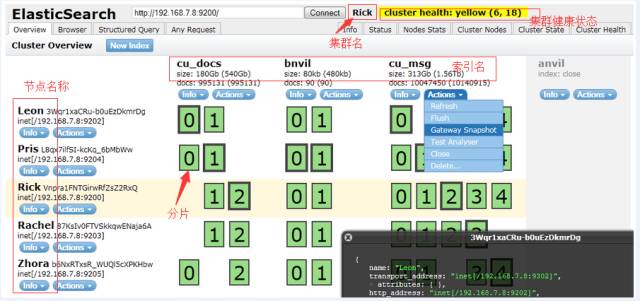
1. 在浏览器中利用Elasticsearch 的head 插件查询相关索引,如图所示:
2. 在浏览器中利用Kibana进行查询,如想看最近一段时间内的数据量:
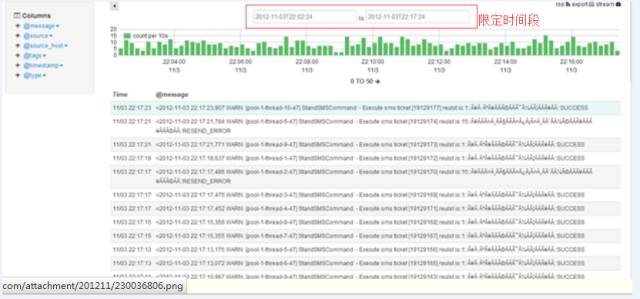
这里支持的图标有多种,可以将所有创建好的图表进行保存,然后在Dashboard中进行显示如:
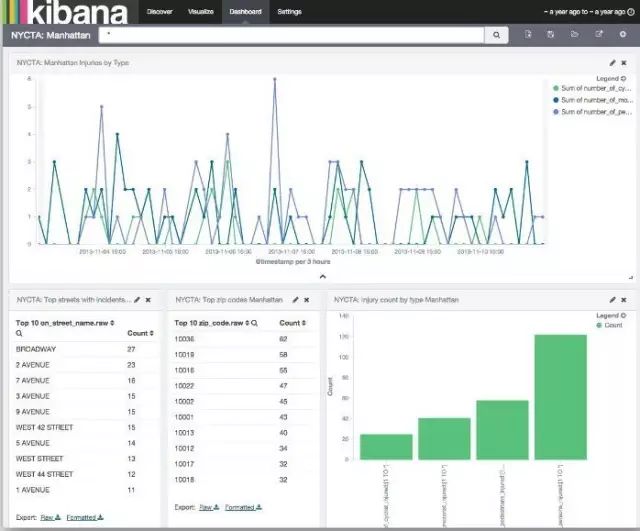
最后总结ELK的优点:
1. 处理方式灵活:Elasticsearch 是实时全文索引,不需要像 Storm 那样预先编程才能使用。
2. 配置简易上手:Elasticsearch 全部采用 Json 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
3. 检索性能高效:虽然每次查询都是实时计算,但是优秀的设计和实时基本可以达到全天数据查询和秒级响应;
4. 集群线性扩展:不管是 Elasticsearch 集群还是 Logstash 集群都可以线性扩展;
5. 前端操作绚丽:Kibana 界面上,只要点击鼠标,就可以完成搜索、聚合功能、生成绚丽仪表板。
- END -
非常欢迎加入我们的微信群一起讨论分享!
新浪微博:ChatbotsChina
微信号:Chatbots01


关注我们,一起学习机器人





