前言
微软的 Jonathan Creamer 团队通过优化 Git 仓库管理和使用新的 Git 特性,成功将其巨大的 JavaScript 单体仓库(monorepo)大小减少了 94%。今日前端早读课文章由 @飘飘翻译分享。
正文从这开始~~
这不是为了吸引点击的。我们真的这样做了!我们在微软工作,使用一个非常庞大的 Javascript 单体代码库,我们俗称 "1JS"。它不仅在 GB 方面很大,而且在代码和贡献的绝对数量方面也相当庞大。我们最近达到了每月活跃用户数 1000 的里程碑,拥有约 2500 个包和 2000 万行代码!我最近克隆的代码库大小惊人,达到了 178GB。

由于种种原因,这个仓库实在太大了,我们在欧洲的人员甚至因为文件大小都无法克隆仓库。
问题是,这究竟是怎么发生的?!
原因一:单一文件夹存放过多文件
几年前我刚加入该仓库时,几个月后我注意到它在不断增长。我第一次克隆它时,只有一两个 G 的大小,但几个月后已经达到了大约 4GB。很难确切知道这是为什么。
以前我曾经使用过一个名为 git-sizer 的工具,它告诉我一些关于大型数据块的信息。当有人不小心将二进制文件提交到代码库时,就会出现大型 “blob” 的情况。除了在代码库中强制执行文件大小限制(这是 Azure DevOps 的一个功能)之外,这种情况下没有其他有效的解决方法。一旦文件被提交,它就无法被更改,只能在后续的版本控制操作中进行处理。
其次,它提醒我关于我们 Beachball 更改文件的问题,我们并没有删除这些文件。我们使用它们的方式与 Changesets 相同,目的是告诉包如何自动调整它们的 SemVer 范围,其目的与 semantic-release 类似。
有时,我们会在一个文件夹中积累多达 40,000 个这样的文件,我们发现每当向该文件夹添加一个新的文件时,就会创建一个庞大的树形对象。

所以,我们学到的第一课是...
不要把成千上万的东西都放在同一个文件夹里。
我们最终采取了两个措施来解决这个问题。一个是向 beachball 提交了一个请求,它在单个变更文件中进行了多项更改,而不是对每个包进行一次更改。
向 beachball 提交了一个请求:https://github.com/microsoft/beachball/pull/584
其次,我们编写了一个管道,该管道定期运行并自动清理那个更改文件夹,以防止其变得过大。
欢呼!我们解决了 git 膨胀问题!
原因二:Git算法缺陷
 我们解决了 Git 膨胀的问题!不,我们没有
我们解决了 Git 膨胀的问题!不,我们没有
我们在大规模部署中采用的版本控制流程会维护了一个名为 versioned 的 main 镜像,用于存储实际的包版本,这样我们就可以使 main 免受 git 冲突的影响,并准确地查看哪些 git 提交与我们通过 npm 包发布的哪些 semver 版本相对应。
我注意到,随着版本分支越来越大,它似乎越来越难克隆了。不过,我们已经解决了变更文件的问题, 在 versioned 分支中,唯一包含的提交就是对 CHANGELOG.md 和 CHANGELOG.json 文件的追加。
 蝙蝠侠挠着下巴
蝙蝠侠挠着下巴
时间流逝,尽管我们的仓库增长速度略有放缓,但它仍在持续增长。然而,很难确定这种增长是否仅仅是因为规模扩大,还是另有原因。自 2021 年以来,我们每年都在增加数十万行代码和数百名开发者,因此可以认为这是自然增长的结果。然而,当我们意识到我们的增长速度已经超过了微软最大的单体仓库 ——Office 仓库的增长速度时,我们意识到一定出了什么问题!
那时我们才请求增援...

由于我们在 Office 的单体仓库规模庞大而创造了诸如 git 浅层检出、git 稀疏索引以及各种其他特性的作者,在将这些特性推向世界后在 Github 工作了一段时间,如今又重新加入了我们的组织。
他看了一眼,立刻意识到这个增长速度肯定不对劲。当我们拉取版本分支时,那些只更改 CHANGELOG.md 和 CHANGELOG.json 的分支,竟然会下载 125GB 额外的 Git 数据?这是怎么回事?
好吧,经过一番深入的 git 挖掘,结果发现 Linux Torvalds(听说过这个人吗?🤷♂️)在很久以前提交的一些打包代码,实际上只在将差异推送到 Git 之前准备压缩文件时检查文件名的最后 16 个字符。通常情况下,Git 只会推送已更改文件的差异,但由于打包问题,Git 正在比较来自不同包的 CHANGELOG.md 文件!Stolee 在这里对此进行了很好的解释。
例如,如果你更改了 repo/packages/foo/CHANGELOG.json ,当 Git 准备执行推送操作时,它会生成与 repo/packages/bar/CHANGELOG.json 的差异!这意味着我们很多时候只是一遍又一遍地推送整个文件,在某些情况下,每个文件可能会有数十兆字节,你可以想象在我们这种规模的仓库中,这会是一个问题。
我们随后尝试使用更大的窗口 git repack -adf --window=250 重新打包我们的仓库,让 Git 能够更好地压缩仓库的打包文件,从而显著减小仓库的大小。这确实显著减小了仓库的大小,但是我们还可以做得更好!
此 PR https://github.com/git-for-windows/git/pull/5171 引入了一种新的打包方式,该方式基于遍历 Git 路径而不是默认的遍历提交。
结果令人震惊...
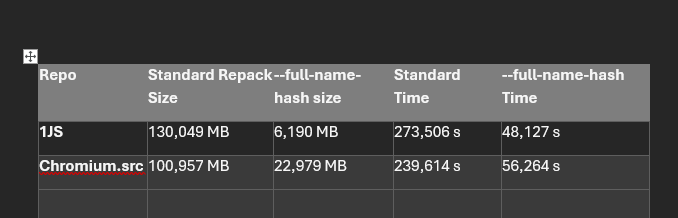
昨天在我的机器上运行了一个新的 git 克隆,尝试了微软 git 分支中的新版本 git(git 版本 2.47.0.vfs.0.2)...

运行新的 git repack -adf --path-walk 之后...
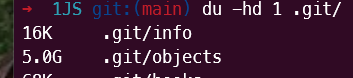
疯狂。从 178GB 变成了 5GB。😱

即将添加的另一个新配置选项将进一步确保在 git push 时间生成正确的 delta 类型...
git config --global pack.usePathWalk true
这将确保您的 git push 命令执行正确的压缩操作。
使用 git 版本 2.47.0.vfs.0.2 的任何开发者现在都可以在本地克隆后重新打包仓库,同时使用新的 git push 路径遍历算法来阻止增长速率。
在 GitHub 上,重新打包和 git 垃圾回收操作会定期发生,但是同样地,GitHub 所采用的打包方式无法正确计算这些 CHANGELOG.md 和 CHANGELOG.json 文件(或者任何具有相同 16 个字符名称的文件,这些文件的名称会随着时间的推移频繁变化)的增量。考虑像 i18n 这类大型字符串文件等。
我们使用的 Azure DevOps 目前还没有这样的重打包功能。因此,我们也在努力实现这一功能,以便在服务器端减少代码库的大小。
这些变化也将全部进入 git 的上游!为开源欢呼。
总结
如果你在一个较大的单体仓库中工作,并且有 CHANGELOG.md 或其他文件名较长(大于 16 个字符)的文件,并且这些文件经常被更新,那么你可能需要关注一下路径遍历相关的内容。
你也可以尝试使用新的 git survey 命令来查看各种新的启发式方法,例如按磁盘大小排序的顶级文件,按膨胀大小排序的顶级目录,或者按膨胀大小排序的顶级文件。
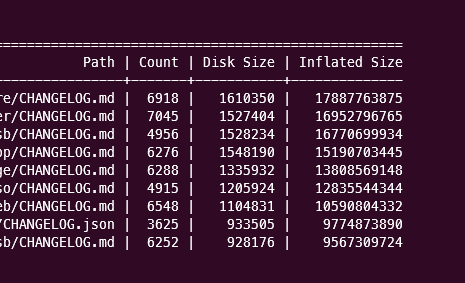
这些启发式方法将帮助你判断路径遍历工作是否也会对你的仓库大小产生影响。
总体而言,我对我们在尝试提供有助于微软扩大存储库并将其解决方案推广到全球的承诺感到非常印象深刻和兴奋。
如何检测和解决 Git 仓库中的大文件问题?
要检测和解决 Git 仓库中的大文件问题,可以遵循以下步骤:
检测大文件
使用 git-sizer 工具,它可以帮助你识别仓库中的大文件和其他空间占用问题。运行 git-sizer 后,它会生成一个报告,列出大文件和其他可能导致仓库膨胀的因素。
使用 git ls-tree -r -t -l -- 命令,可以查看指定路径下的所有文件及其大小,
git ls-tree -r -t -l -- /
分析历史版本
使用 git log -- 命令,可以查看特定文件或目录的提交历史。
git log -- /path/to/large/file
使用 git blame 命令,可以查看文件中每一行的最后提交信息,有助于找到添加大文件的提交。
git blame /path/to/large/file
移除大文件
如果大文件是错误地提交的,可以使用 git rm 命令将其从最新提交中移除。
git rm --cached /path/to/large/file
使用 git commit --amend 或 git rebase -i 来重写历史,将大文件的提交从历史中移除。
对于单个提交
git commit --amend -C HEAD
对于多个提交(交互式重写)
git rebase -i HEAD~<number_of_commits>
清理历史
使用 git filter-branch 或 git filter-repo(更现代的替代品)来重写仓库历史,从中完全移除大文件的痕迹。
git filter-branch --force --index-filter 'git rm --cached --ignore-unmatch /path/to/large/file' --prune-empty --tag-name-filter cat -- --all
或者
git filter-repo --invert-paths --path /path/to/large/file
强制推送更改
在本地仓库清理完成后,需要使用 git push --force 或 git push --force-with-lease 来更新远程仓库。
git push --force-with-lease
确保不会再次发生问题
在.gitattributes 文件中设置 *.bin 等大文件类型的 export-ignore 属性,以防止将来再次提交大文件。
*.bin export-ignore
在.gitignore 文件中添加大文件的路径,确保这些文件不会被意外地添加到版本控制中。
/path/to/large/file
定期维护
请注意,重写历史是破坏性的操作,可能会对团队成员的工作造成影响。在进行这些操作之前,确保与团队沟通,并在必要时创建仓库的备份。
关于本文
译者:@飘飘
作者:@Jonathan Creamer
原文:https://www.jonathancreamer.com/how-we-shrunk-our-git-repo-size-by-94-percent/

这期前端早读课
对你有帮助,帮” 赞 “一下,
期待下一期,帮” 在看” 一下 。









