在去年的谷歌 I/O 开发者大会上,谷歌宣布发布了一款新的定制化硬件——张量处理器(Tensor Processing Unit/TPU),参见机器之心当时的报道《谷歌发布 TPU 只是开始,是时候让英特尔害怕了》。但很长一段时间以来,谷歌并没有披露相关成果的细节。今天早些时候,谷歌终于打破了沉默,通过一篇论文介绍了这项研究的相关技术以及与其它硬件的比较。谷歌的硬件工程师 Norm Jouppi 也第一时间在谷歌云计算博客上刊文介绍了这一研究成果。机器之心在本文中对该博客文章进行了编译介绍,文后也摘取了原论文的部分内容,读者可点击阅读原文下载此论文。
过去十五年里,我们一直在我们的产品中使用高计算需求的机器学习。机器学习的应用如此频繁,以至于我们决定设计一款全新类别的定制化机器学习加速器,它就是 TPU。
TPU 究竟有多快?今天,联合在硅谷计算机历史博物馆举办的国家工程科学院会议上发表的有关 TPU 的演讲中,我们发布了一项研究,该研究分享了这些定制化芯片的一些新的细节,自 2015 年以来,我们数据中心的机器学习应用中就一直在使用这些芯片。第一代 TPU 面向的是推论功能(使用已训练过的模型,而不是模型的训练阶段,这其中有些不同的特征),让我们看看一些发现:
我们产品的人工智能负载,主要利用神经网络的推论功能,其 TPU 处理速度比当前 GPU 和 CPU 要快 15 到 30 倍。
较之传统芯片,TPU 也更加节能,功耗效率(TOPS/Watt)上提升了 30 到 80 倍。
驱动这些应用的神经网络只要求少量的代码,少的惊人:仅 100 到 1500 行。代码以 TensorFlow 为基础。
70 多个作者对这篇文章有贡献。这份报告也真是劳师动众,很多人参与了设计、证实、实施以及布局类似这样的系统软硬件。
TPU 的需求大约真正出现在 6 年之前,那时我们在所有产品之中越来越多的地方已开始使用消耗大量计算资源的深度学习模型;昂贵的计算令人担忧。假如存在这样一个场景,其中人们在 1 天中使用谷歌语音进行 3 分钟搜索,并且我们要在正使用的处理器中为语音识别系统运行深度神经网络,那么我们就不得不翻倍谷歌数据中心的数量。
TPU 将使我们快速做出预测,并使产品迅速对用户需求做出回应。TPU 运行在每一次的搜索中;TPU 支持作为谷歌图像搜索(Google Image Search)、谷歌照片(Google Photo)和谷歌云视觉 API(Google Cloud Vision API)等产品的基础的精确视觉模型;TPU 将加强谷歌翻译去年推出的突破性神经翻译质量的提升;并在谷歌 DeepMind AlphaGo 对李世乭的胜利中发挥了作用,这是计算机首次在古老的围棋比赛中战胜世界冠军。
我们致力于打造最好的基础架构,并将其共享给所有人。我们期望在未来的数周和数月内分享更多的更新。
论文题目:数据中心的 TPU 性能分析(In-Datacenter Performance Analysis of a Tensor Processing Unit)

摘要:许多架构师相信,现在要想在成本-能耗-性能(cost-energy-performance)上获得提升,就需要使用特定领域的硬件。这篇论文评估了一款自 2015 年以来就被应用于数据中心的定制化 ASIC,亦即张量处理器(TPU),这款产品可用来加速神经网络(NN)的推理阶段。TPU 的中心是一个 65,536 的 8 位 MAC 矩阵乘法单元,可提供 92 万亿次运算/秒(TOPS)的速度和一个大的(28 MiB)的可用软件管理的片上内存。相对于 CPU 和 GPU 的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种 TPU 的确定性的执行模型(deterministic execution model)能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为 CPU 和 GPU 更多的是帮助对吞吐量(throughout)进行平均,而非确保延迟性能。这些特性的缺失有助于解释为什么尽管 TPU 有极大的 MAC 和大内存,但却相对小和低功耗。我们将 TPU 和服务器级的英特尔 Haswell CPU 与现在同样也会在数据中心使用的英伟达 K80 GPU 进行了比较。我们的负载是用高级的 TensorFlow 框架编写的,并是用了生产级的神经网络应用(多层感知器、卷积神经网络和 LSTM),这些应用占到了我们的数据中心的神经网络推理计算需求的 95%。尽管其中一些应用的利用率比较低,但是平均而言,TPU 大约 15-30 倍快于当前的 GPU 或者 CPU,速度/功率比(TOPS/Watt)大约高 30-80 倍。此外,如果在 TPU 中使用 GPU 的 GDDR5 内存,那么速度(TOPS)还会翻三倍,速度/功率比(TOPS/Watt)能达到 GPU 的 70 倍以及 CPU 的 200 倍。
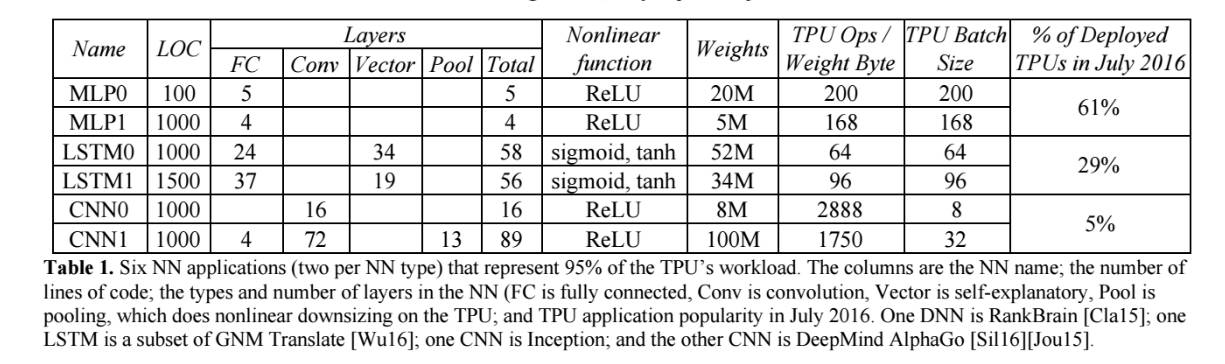
表 1:6 种神经网络应用(每种神经网络类型各 2 种)占据了 TPU 负载的 95%。表中的列依次是各种神经网络、代码的行数、神经网络中层的类型和数量(FC 是全连接层、Conv 是卷积层,Vector 是向量层,Pool 是池化层)以及 TPU 在 2016 年 7 月的应用普及程度。RankBrain [Cla15] 使用了 DNN,谷歌神经机器翻译 [Wu16] 中用到了 LSTM,Inception 用到了 CNN,DeepMind AlphaGo [Sil16][Jou15] 也用到了 CNN。
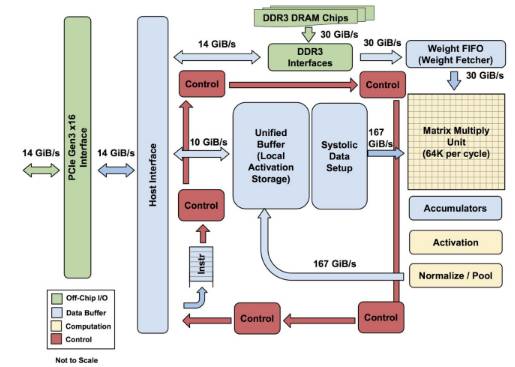
图 1:TPU 各模块的框图。主要计算部分是右上方的黄色矩阵乘法单元。其输入是蓝色的「权重 FIFO」和蓝色的统一缓存(Unified Buffer(UB));输出是蓝色的累加器(Accumulators(Acc))。黄色的激活(Activation)单元在Acc中执行流向UB的非线性函数。
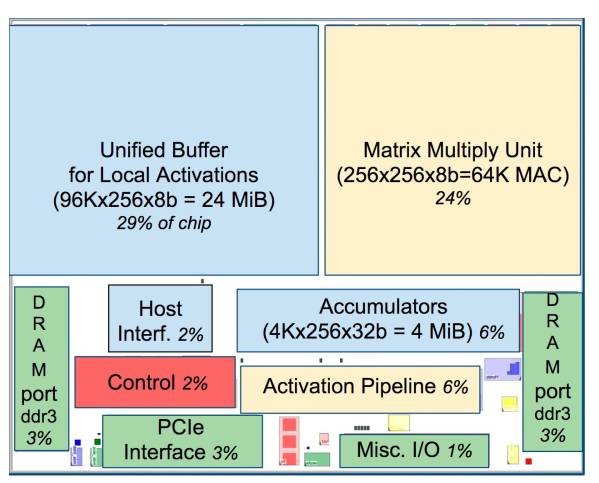
图 2:TPU 芯片布局图。阴影同图 1。蓝色的数据缓存占芯片的 37%。黄色的计算是 30%。绿色的I/O 是 10%。红色的控制只有 2%。CPU 或 GPU 中的控制部分则要大很多(并且非常难以设计)。

图3:TPU印制电路板。可以插入服务器 SATA 盘的卡槽,但是该卡使用了 PCIe Gen3 x16 接口。
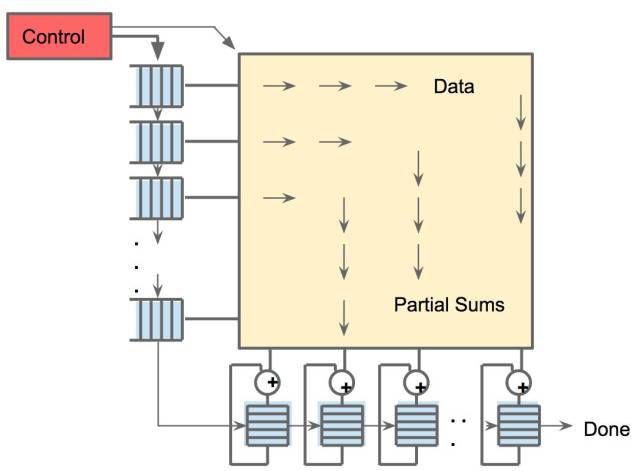
图4:矩阵乘法单元的 systolic 数据流。软件具有每次读取 256B 输入的错觉,同时它们会立即更新 256 个累加器 RAM 中其中每一个的某个位置。
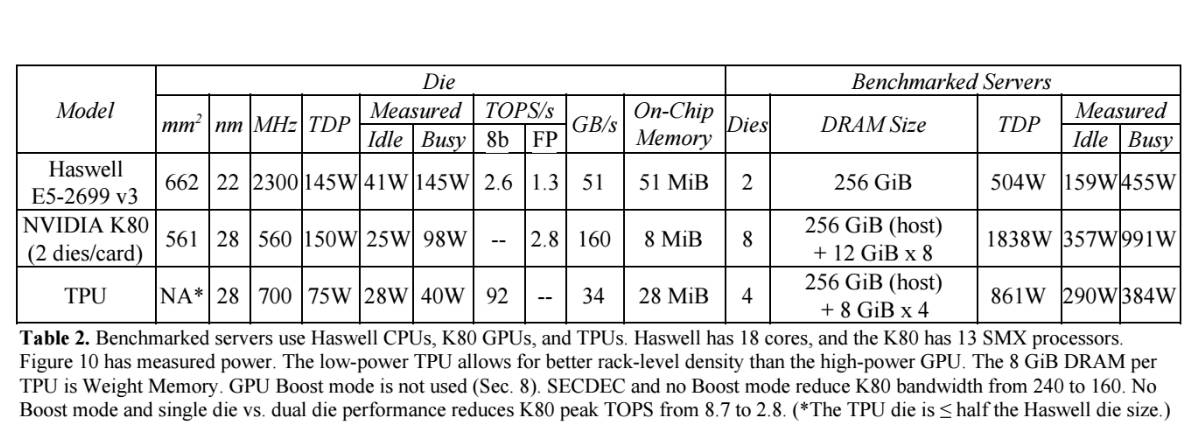
表2:谷歌 TPU 与英特尔 Haswell E5-2699 v3、英伟达Tesla K80 的性能对比。E5 有 18 个核,K80 有 13 个 SMX 处理器。图 10 已经测量了功率。低功率 TPU 比高功率 GPU 能够更好地匹配机架(rack)级密度。每个 TPU 的 8 GiB DRAM 是权重内存(Weight Memory)。这里没有使用 GPU Boost 模式。SECDEC 和非 Boost 模式把 K80 带宽从 240 降至 160。非 Boost 模式和单裸片 vs 双裸片性能把 K80 峰值 TOPS 从 8.7 降至 2.8(*TPU 压模小于等于半个 Haswell 压模大小)。
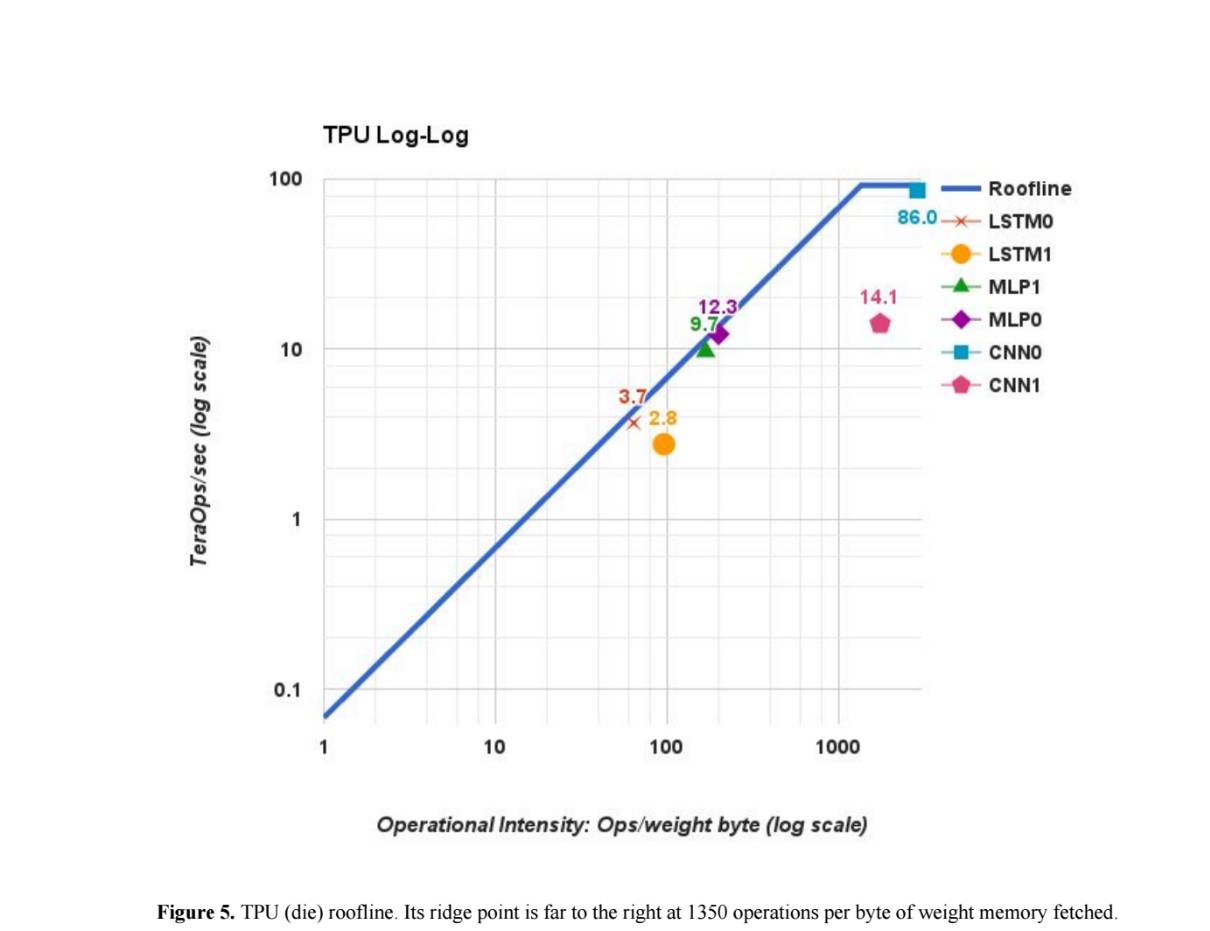
图5:TPU (die) roofline。 其脊点位于所获权重内存每字节运行 1350 次的地方,距离右边还比较远。
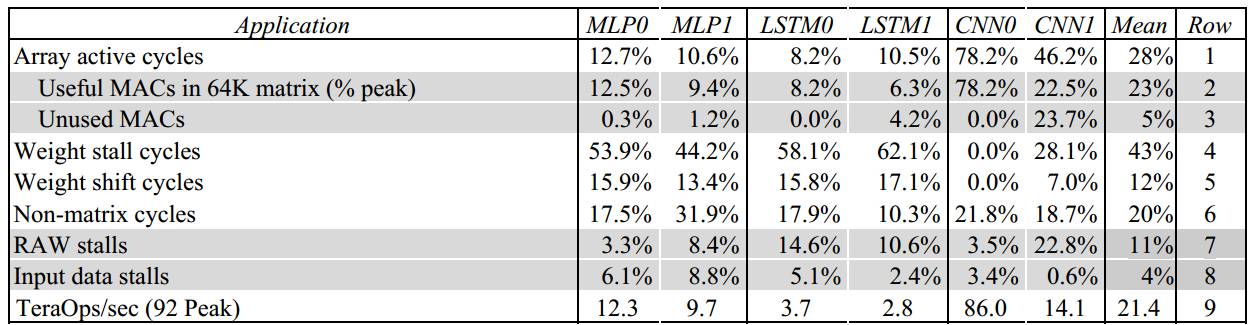
表格3:TPU 在神经网络工作载荷中性能受到限制的因素,根据硬件性能计数器显示的结果。1,4,5,6行,总共100%,以矩阵单元活动的测量结果为基础。2,3行进一步分解为64K权重的部分,我们的计数器无法准确解释矩阵单元何时会停顿在第6行中;7、8行展示了计数器结果,可能有两个原因,包括RAW管道危害,PCIe输入停止。9行(TOPS)是以产品代码的测量结果为基础的,其他列是以性能计数器的测量结果为基础的,因此,他们并不是那么完美保持一致。这里并未包括顶部主服务器。MLP以及LSTM内存带宽有限,但是CNN不是。CNN1的测试结果会在文中加以分析。
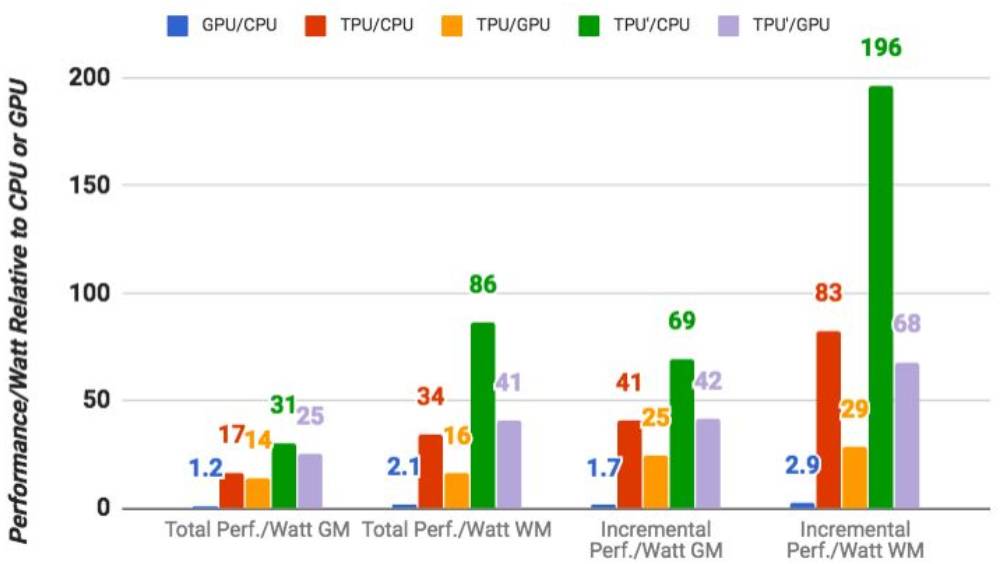
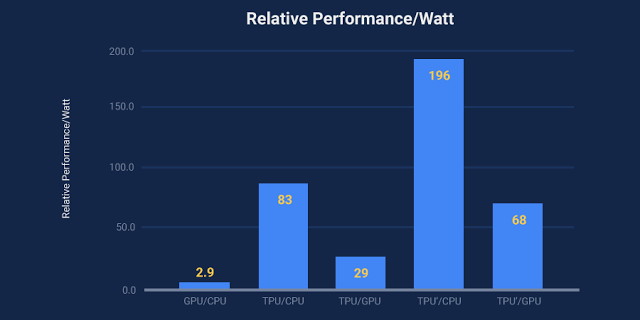
图 9:GPU 服务器(蓝条)对比 CPU、TPU 服务器(红条)对比 CPU、TPU 服务器对比 GPU(橘黄)的相对性能表现/Watt(TDP)。TPU' 是改进版的 TPU(Sec.7)。绿条显示了对比 CPU 服务器的比例,淡紫色显示了与 GPU 服务器的关系。整体包括了主服务器的能耗,但不包括增量(incremental)。GM 和 WM 分别是几何学图形与加权平均值。
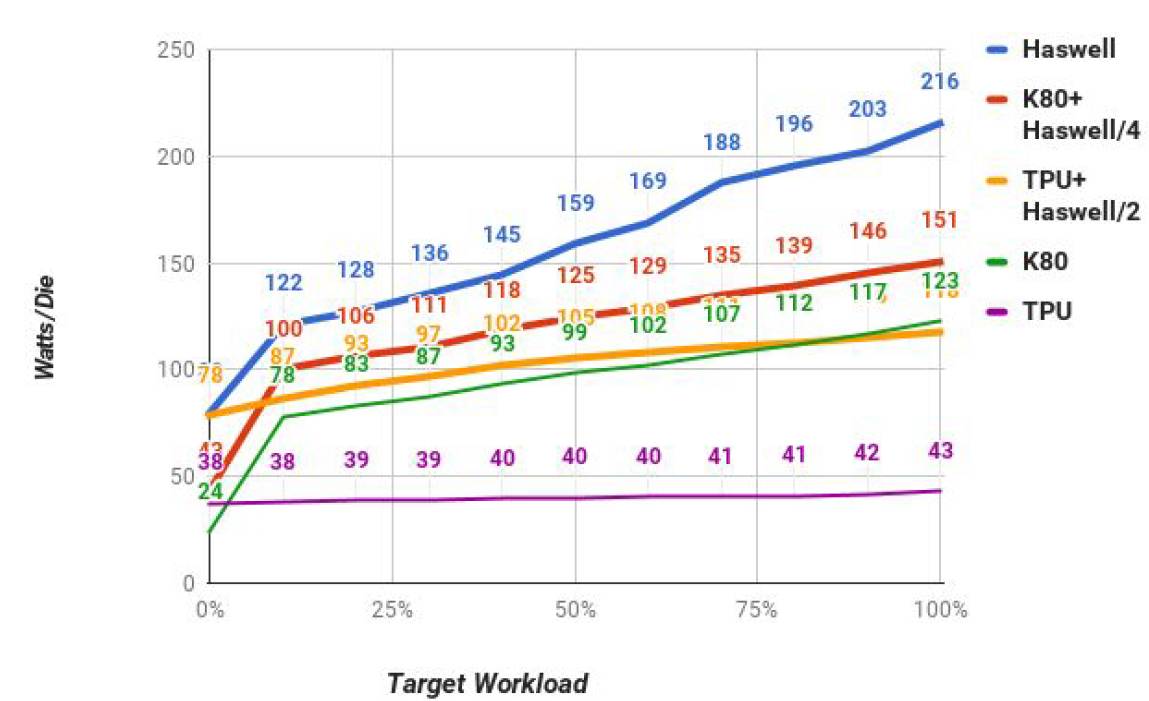
图10:CNN0 平台的单位功耗对比,其中红色和橙色线是 GPU 加 CPU 系统的功率。蓝色是英特尔 E5-2699 v3 Haswell CPU 的功率,绿色是英伟达 Tesla K80 的功率,紫色为谷歌 TPU。每个服务器通常有多个芯片组,以上所有数字都已被整除成单芯片功率。
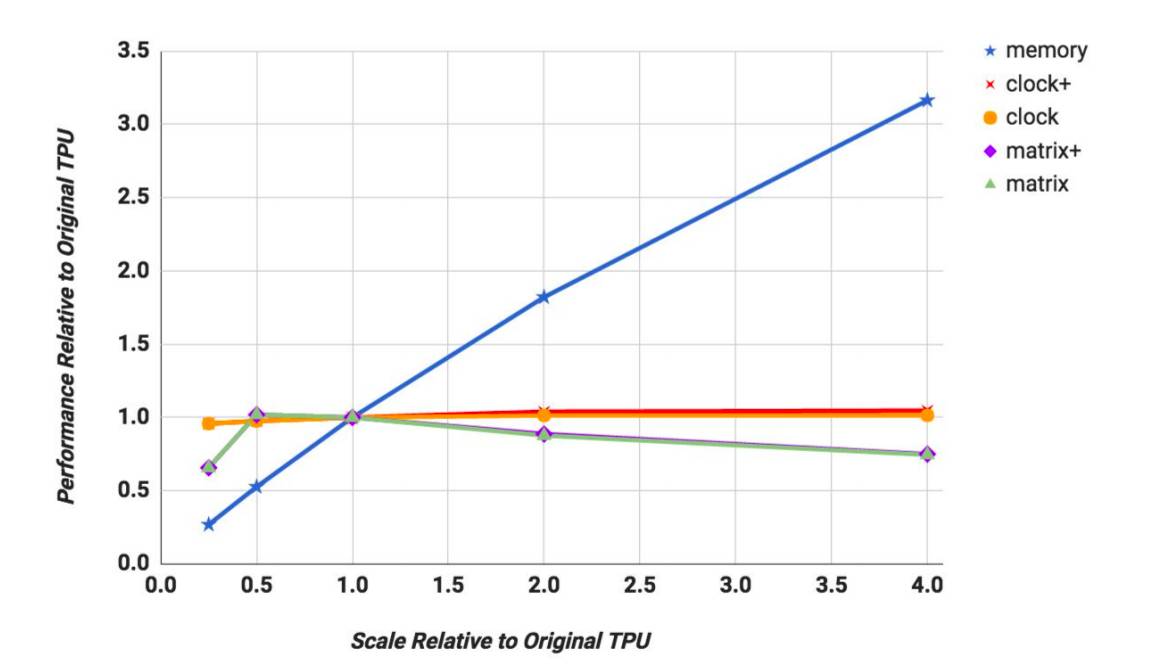
图11:加权平均 TPU 性能作为度量单元,从 0.25 倍扩展到了 4 倍:内存带宽,时钟频率+累加器,时钟频率,矩阵单元维度+累加器,以及矩阵单元维度。加权均值使得我们很难看出单个 DNN 的贡献,但是,MLP 以及 LSTM 提升了 3 倍到 4 倍的内存带宽,但是,更高的时钟频率并没带来任何效果。对于 CNN 来说,结果反之亦然;4 倍的时钟率,2 倍的效果。但是,更快的内存并没带来什么好处。一个更大的矩阵乘法单元并不能对任何 DNN 有帮助。
谷歌博客:https://cloudplatform.googleblog.com/2017/04/quantifying-the-performance-of-the-TPU-our-first-machine-learning-chip.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








