AI 圈有这样一句话:解决了自然语言处理问题,就解决了人工智能的大部分问题。如何提高机器的自然语言处理能力一直是 AI 工程师们不断努力想要解决的难题。本文作者将分享在自然语言处理的研究和学习的过程中自己的收获。
2016 年底,Yann LeCun 在 NIPS 大会中曾说到:“Predicting any part of the past, present or future percepts from whatever information is available.”,并提出预测学习(predictive learning)的概念。其实预测学习指的就是无监督学习,那为什么要强调预测呢?
现在市面上大部分的人工智能技术还是以有监督学习居多,如:目标识别、文本分类等,在大量数据驱动下,有监督学习能够达到非常可观的效果,但并不适用于所有情况,如图 1.1 中的情况。

图 1.1 取自 Yann LeCun PPT
当人看到这样的图片的时候,看到的是一个人拿着包裹,准备出门,如果用有监督的方法想要获得这个信息大概又需要重新标记图片训练模型了,而这样大量标记和训练工作却是无意义的。人之所以能够获得“出门”的信息,是因为我们看到过并且切身经历过,是因为我们从现实生活中获得了经验,这些经验逐渐的成为了我们的常识,这使得我们在看到事物的时候不自觉的就会知道后面可能发生的事,使得我们在看小说时头脑中能够想象出小说中的情景,使得我们在读书后能够学到知识,并应用于现实生活中。这,就是人的预测能力。
由此可以看出,智能的本质是预测能力,而预测能力是需要足够的先验知识作为前提的,也就是“常识”。于人类相比,AI 最大局限是没有人类的“常识”,在没有任何常识的情况下 AI 只能够完成人们让他完成的事,并且适应性较差。从古至今,最准确高效的存储知识的方式就是文字,如今,通过文字来存储大量的知识已经不构成问题,问题是,有了先验知识(不论是否结构化),如何准确地查询和运用,才是决定预测效果好坏的关键。这个过程就是记忆与推理。
神经网络的投入使用使得提取复杂的特征不再成为难题,其中最为精妙的设计之一是门结构的循环神经网络(Gated Recurrent Neural Network,Gated RNN)使用,典型的实现是 LSTM 和 GRU。门结构的循环神经网络要求输入序列化的数据,使用多种门结构的组合实现对序列上的内容的选择性记忆,并体现在特征向量中,也就是 RNN 的隐含层状态。但这只限于“近期”输入的序列中的内容,面对存储着大量信息的文本,现有的 RNN 技术不仅不能存储大量的历史信息,而且不能够对知识产生区分度,为此,记忆网络被提出。
2015 年,facebook 的 Jason Weston 等人提出了记忆网络(Memory Network)1 的概念,并构造了基于故事推理的 bAbI 问答任务,其 20 个推理任务内容如图 2.1 所示,任务中包涵三个部分:Story,Question 和 Answer。目标是让智能体(Agent)能够利用 Story 中的“常识”,经过多层的推理获得问题的答案。其思想是使用记忆网络“阅读”任务中给定的故事,并将故事的各个部分分别存储在记忆模块的不同区域,根据给定的问题,选中合适记忆来完成对问题的回答。


图 2.1 bAbI 20 Tasks
记忆网络的结构如图 2.2 所示,其中包含四个核心模块,分别为 I、G、O、R。
I 为输入模块。包括对输入的预处理(如句法解析、共指消解等使输入更佳规范的处理)和特征表示(一种在连续空间上的映射)。
G 为更新模块。用于更新记忆模块(Memory Slots),其功能包括 slot 的选择、记忆分组、记忆更新和遗忘。
O 为输出模块。用于对已存在记忆 slots 选择性调用,并根据当前的请求推理得到响应特征表示的模块。
R 为响应模块。用于“组织语言”把 O 得到的响应特征表示表达出来。
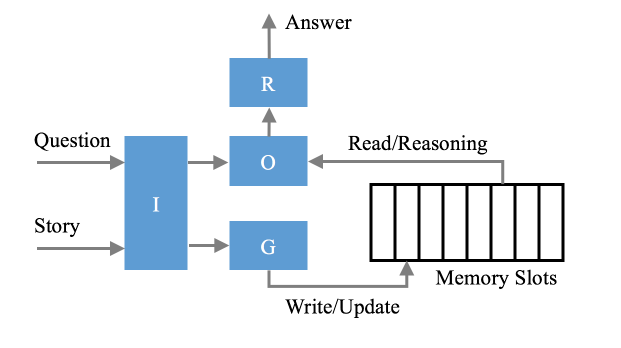
图 2.2 记忆网络结构
运行时,G 会根据输入即使更新 Memory 中存储的内容,随后经过 O 的多层推理,精准的为问题找到答案。
Jason Weston 等人的记忆网络结构只是提出了一种基于长期的结构化记忆和推理的机制,其中的 I/G/O/R 可以为任何的模型,并没有给出构造这些模型效果最优方法。基于记忆网络的思想,很多的“外挂”存储结构的神经网络结构和机制被提出,其思想可以分为两种,一种以 Multiple-hops 为核心的 End-to-End 的机制;另一种则是利用了现有的 RNN 的记忆功能,来实现对“记忆”模块的更新和查询。
2015 年,Sainbayar Sukhbaatar 等人提出了一种 Multiple-hops 记忆网络 2,其结构如图 2.3 所示,它将记忆网络的 I/G/O/R 融合在了一起组成了一个端到端(End-to-End)的网络。该结构中的每一层采用了两个不同的 Embedding 矩阵来表示 Memory 中的 slots,如图 3(a)所示,其中蓝色的 Embedding 起到了 Attention 的作用,生成了每个 slots 上面的概率分布,黄色的 Embedding 用于输入对 Memory slots 的选择,最后通过 Softmax 实现通过所选中的“记忆”对给定问题的答案预测功能。参考 RNN 的机制,将多个这样的结构串联起来,并保持每层的 Embedding 是不同的,就构成了 Multiple-hops 的端到端记忆网络。这种结构的优势在于能够充分的实现 Memory 的特征表示,使得记忆网络更佳容易通过 BP(反向传播)训练。该方案(Hop3)通过了 bAbI 20 项任务中的 14 项(accuracy>95% 记为通过测试)。
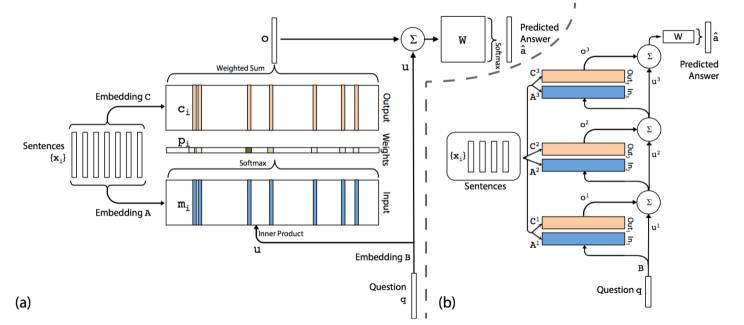
图 2.3 End-to-End Memory Networks
另一种思想是利用 RNN 的循环机制和门结构,实现对“记忆”模块的控制。在 RNN 基础上改进的方案较多,例如 2015 年 Armand Joulin 等人提出的 Stack-Augmented RNN3,文中使用外挂的栈式的记忆模块帮助 RNN 实现更稳定的长期记忆。2016 年 Ankit Kumar 等人利用 Attention+RNN 组成的动态记忆网络(DMN)实现对 Memory slots 的更新和使用 4,改方案通过了 bAbI 任务中的 18 项(accuracy>95% 记为通过测试)。
到目前唯一一个通过全部的 bAbI 20 项测试是 2017 年 Jason Weston、Yann LeCun 等人提出的 EntNet5,与 Ankit Kumar 等人的思想类似,文中利用了 RNN 实现了动态的记忆模块,即将 RNN 部分用于对不同实体的记忆存储,不同之处在于,该方案调整了 RNN 中的门结构,以实现通过对“事件”的充分的观察、记忆和推理来不断地改变智能体对“世界状态”(文中叫法)的认知和预测。
EntNet 的结构如图 2.4 所示,其结构的目的是实现对概念或实体的多层关系的记忆。如,当我们看到“小明打开了家里的门,走进了自己的卧室”,智能体就知道了小明当前的位置,如果同时得知“小明一直背着书包”,则智能体就知道了书包的位置。并且,随着智能体对“文档”的阅读,其记忆也在不断的更新。通过这种学习方式,智能体能够获得一些常识性的信息。如,当一个人走进了屋子,它会知道屋子里的人数增加了;它可能还会知道老虎和羊不能够放在一个笼子里等。
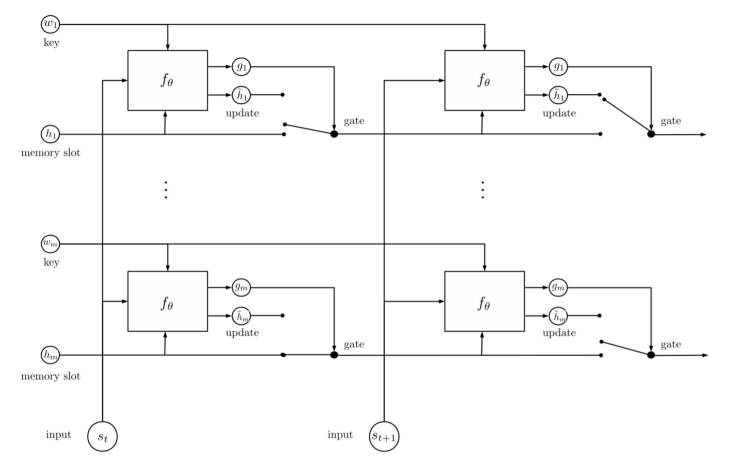
图 2.4 Tacking the World State with Recurrent Entity Networks










