选自Nextplatform
作者:Linda Barney
参与:李泽南、晏奇、黄小天、吴攀
FPGA 会随着深度学习的发展占领 GPU 的市场吗?英特尔的研究人员对目前最好的两种芯片做了对比。
社交媒体和物联网正持续不断地以指数级方式产出语音、视频、图像等数字数据,这带动了对于数据分析(让数据变得可理解与可执行)的需求。数据分析经常依赖于机器学习(ML)算法。在众多机器学习算法中,深度卷积神经网络在重要的图像分类任务中具有当前最高的精确度,因而被广泛采用。
在最近的「2017 现场可编程门阵列国际大会(ISFPGA)」上,来自英特尔加速器架构实验室(AAL)的 Eriko Nurvitadhi 博士展示了有关「在加速新一代深度神经网络方面,FPGA 可否击败 GPU」的研究,其研究使用最新的 DNN 算法在两代英特尔 FPGA(Arria10 与 Stratix 10)与目前最高性能的英伟达 Titan X Pascal GPU 之间做了对比评估。
论文地址:http://dl.acm.org/citation.cfm?id=3021740
英特尔 Programmable Solutions Group 的 FPGA 架构师以及论文的联合作者之一 Randy Huang 博士说:
深度学习是人工智能之中一个最激奋人心的领域,其取得了人工智能领域的最大进展,并催生出了最多的应用。尽管人工智能和 DNN 研究者喜欢使用 GPU,但我们发现英特尔新一代 FPGA 架构与应用领域之间存在着一个完美的契合。我们关注着即将来临的 FPGA 技术进步,DNN 算法的快速进展,并考虑着未来的高性能 FPGA 在新一代 DNN 算法的表现上能否胜过 GPU。通过研究我们发现在 DNN 研究中 FPGA 表现很好,并可用在人工智能、大数据或机器学习等需要分析大量数据的研究领域。当使用剪枝过的或紧密的数据类型 VS 全 32 位浮点数(FP32)时,被测试的英特尔 Stratix 10 的表现胜过了 GPU。除了性能之外,FPGA 同样很强大,因为其适应性强,并且可通过复用一个现存的芯片而容易地实现变化——一块芯片就可帮助一个团队在 6 个月内把一个想法做成原型,而打造一个 ASIC 则需要 18 个月。
测试中使用的神经网络机器学习
神经网络可以被表示为由加权边(weighted edges)互连起来的神经元图。每个神经元(neuron)和边(edge)都分别与一个激活值与权重相关联。神经网络结构由多层神经元组成。如下图 1 所示:
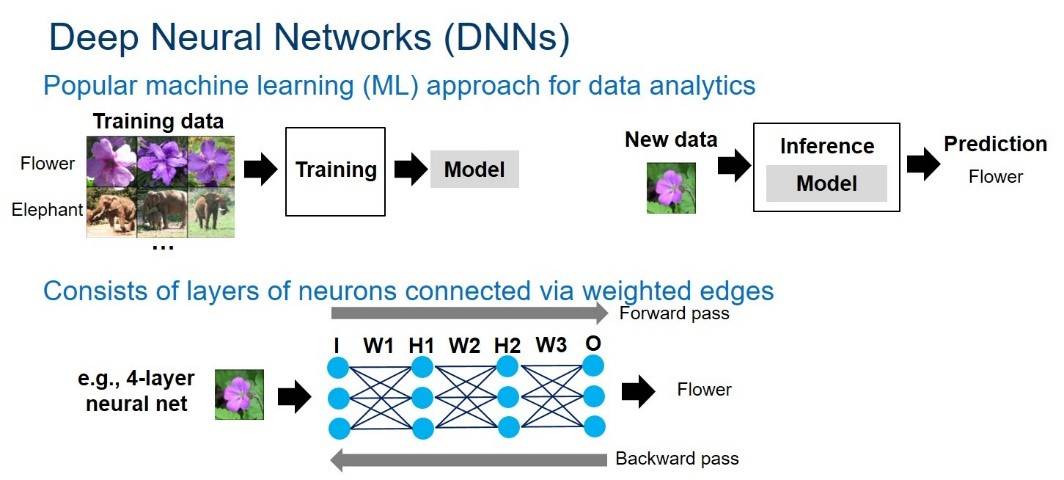
图 1:深度神经网络概观。该图由 Intel 提供。
神经网络的计算在网络中逐层传递。对于一个给定的层,每个神经元的值由前一层神经元的值与边权重(edge weight)累加相乘计算而成。计算在很大程度上基于乘积-累加操作。DNN 计算由正向与反向通过组成。正向通过在输入层获取一个样本,然后遍历隐藏层,在输出层产生一个预测。对于推理而言,只需要正向通过就能获得一个给定样本的预测结果。对训练而言,从正向通过中得到的错误预测接下来会在反向通过过程中被返回,以此来更新网络的权重——这被称为「反向传播算法(back-propagation algorithm)」。训练会反复进行正向与反向通过操作,从而以此来修正神经网络的权重直到模型可以产生理想精度的结果。
使 FPGA 成为可选项的改变
硬件:尽管和高端 GPU 相比,FPGA 的能量效率(性能/功率)会更好,但是大多数人不知道它们还可以提供顶级的浮点运算性能(floating-point performance)。FPGA 技术正在快速发展。即将上市的 Intel Stratix 10 FPGA 能提供超过 5000 个硬浮点单元(DSP),超过 28MB 的片上内存(M20K),同时整合了高带宽内存(最高可达 4x250GB/s/stack 或 1TB/s),以及由新的 HyperFlex 技术的改善了的频率。英特尔 FPGA 能提供全面的从软件生态系统——从低级硬件描述语言到 OpenCL、C 和 C++的高级软件开发环境。使用 MKL-DNN 库,英特尔将进一步将 FPGA 与英特尔机器学习生态系统和诸如 Caffe 这样的传统架构结合起来。Intel Stratix 10 基于英特尔的 14 纳米技术开发,拥有 FP32 吞吐量上 9.2TFLOP/s 的峰值速度。相比之下,最新的 Titan X Pascal GPU 提供 FP32 吞吐量 11TLOP/s 的速度。
新兴的 DNN 算法:更深的网络可提升精确度,但需要极大地增加参数数量,模型也随之变大;而这一切将对计算力、内存带宽和存储提出更苛刻的要求。如此,人们开始转向更高效的 DNN。采用比 32 位更少的紧密低精度数据类型成为了一个新兴趋势;由 DNN 软件框架(即 TensorFlow)支持的 16 位和 8 位的数据类型正在成为新标准。此外,研究者已经在极低精度 2 位三进制与 1 位二进制 DNN(其值分别地被限制为 (0,+1,-1) 或 (+1,-1))中取得了连续的精度提升。最近 Nurvitadhi 博士合写的一篇论文首次表明,三进制 DNN 能在众所周知的 ImageNet 数据集中取得当前最高的(即,ResNet)精确度。稀疏性(零的存在)是另一个新兴趋势,其可以通过剪枝、ReLU 和 ternarization 等技术被引入到 DNN 的神经元和权重之中,并产生带有 50% 至 90% 零的 DNN。因为没必要在这样的零值上计算,所以如果执行稀疏 DNN 的硬件可以有效地跳过零值计算,那么性能势必提升。
新兴的低精度和稀疏 DNN 算法相比于传统的密集 FP32 DNN 能更大地提升巨型算法的效率,但也带来了 GPU 难以应对的不规律并行和自定义数据类型。相反,FPGA 专为极端的自定义性设计,并在运行不规律并行和自定义数据类型时表现出众。这些趋势将使未来的 FPGA 在运行 DNN、人工智能和机器学习应用方面成为一个可行的平台。Huang 说,FPGA 专用机器学习算法还有更多的峰值储备。
图 2 表示 FPGA 的极端自定义性 (2A),使新兴 DNN (2B) 的高效实现成为可能。

图 3. 矩阵乘法(GEMM)测试的结果,GEMM 是 DNN 中的关键部分
测试 1:矩阵乘法(GEMM)
DNN 严重依赖于矩阵乘法运算(GEMM),常规 DNN 依赖于 FP32 密集 GEMM。而更低精度和稀疏的新 DNN 方法则依赖于低精度(或)稀疏的 GEMM。英特尔的团队评估了两种类型的 GEMM。
FP32 密集 GEMM:团队对比了 FPGA 和 GPU 的数据峰值。结果显示:Stratix 10 和 Titan X Pascal 的峰值理论性能为 11 TFLOPs 和 9.2 TFLOPs。如图 3A 显示,英特尔 Stratix 10 相比 Arria 10 具有更多数量的 DSP,这大大提升了它的 FP32 性能,使其达到了狙击 Titan X 的实力。
低精度 INT6 GEMM:为了展示 FPGA 可定制性带来的优势,实验小组研究了将四个 Int6 封装到 DSP 模块中用于 FPGA 的 6 位(Int6)GEMM 的方式。GPU 并没有对 Int6 的原生支持,在实验中它们使用峰值 Int8 进行比较。图 3B 中的数据显示英特尔 Stratix 10 的表现优于 GPU。同时 FPGA 的能效也占据优势。
超低精度 1 位二进制 GEMM:二进制 DNN 提出了非常紧凑的 1 位数据类型,可通过 xnor 和位计数操作替代乘法,非常适合 FPGA。图 3C 展示了二进制 GEMM 的测试结果,FPGA 的表现优于 GPU(在不同频率目标中可达后者 2 倍-10 倍表现)。
稀疏 GEMM:新出现的稀疏 DNN 包含了大量的零。研究小组测试了稀疏 GEMM 在包含 85% 零的矩阵中的表现(基于剪枝 AlexNet)。团队测试了 FPGA 的灵活性设计——细粒度的方式跳过零计算。该团队还在 GPU 上测试了稀疏 GEMM,但发现性能比在 GPU(相同矩阵大小)上执行密集 GEMM 要差。英特尔的稀疏 GEMM 测试(图 3D)表明,FPGA 的表现优于 GPU,这取决于目标 FPGA 频率。
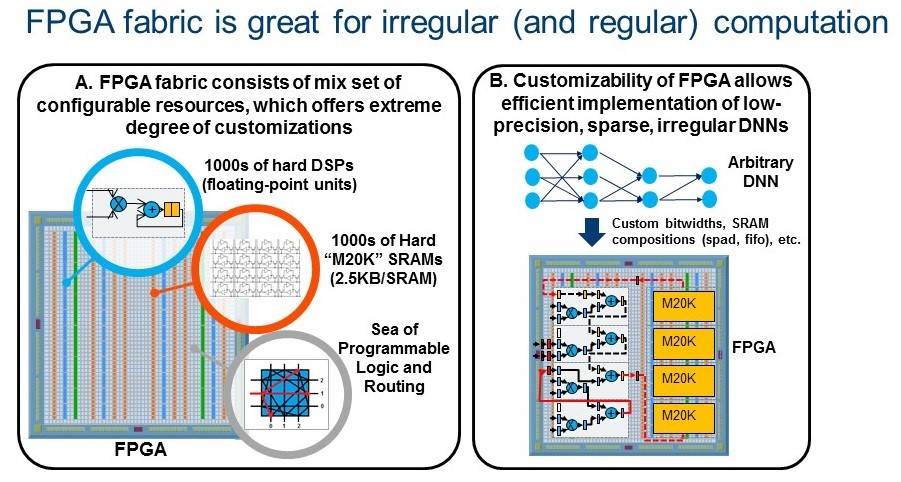
图 4. FPGA 与 GPU 在三元 ResNet DNN 测试中的精度趋势和结果
测试 2:使用三元 ResNet DNNs
三元 DNN 提出了将神经网络权重约束为+1、0 或-1。这允许稀疏的 2 位权重,并用符号位操作替换了乘法。在测试中,研究小组使用了零跳过、2 位权重和无乘法器的 FPGA 设计来优化三元 ResNet DNN 的运行。
与其他很多种低精度稀疏 DNN 不同,三元 DNN 提供了与现有最强 DNN(如 ResNet)相近的准确率,正如图 4 所示。「目前存在的 GPU 和 FPGA 研究注重在 ImageNet 上'能做到多好?',这些研究基于 2012 年的 AlexNet。在 2015 年,最好的方法是 ResNet,图像识别准确率比前者提升了 10%。在 2016 年下半年的另一个研究中,我们第一次展示了 ResNet 的低精度和稀疏三元版本 DNN 算法可以达到和全精度 ResNet 相差大约 1% 的表现。三元 ResNet 是我们在 FPGA 研究中希望达到的目标。我们的实验结果第一次证明 FPGA 可以提供一流的(ResNet)ImageNet 精度,而且它可以做得比 GPU 更好。」Nurvitadhi 指出。
图 4 显示了英特尔 Stratix 10 FPGA 和 Titan X Pascal 在 ResNet-50 任务中的性能和性能/功耗比。即使保守地估计,英特尔 Stratix 10 FPGA 也已经比实现比 Titan X GPU 高出 60%的表现。中性或乐观的估计则更加亮眼(2.1 倍和 3.5 倍速度提升)。有趣的是,英特尔 Stratix 10 在最高 750MHz 的频率上可以比英伟达 Titan X Pascal(1531 MHz)提供多出 35% 的 性能。在性能/功耗方面,英特尔 Stratix 10 比 Titan X 高出 2.3 到 4.3 倍。
FPGA 在测试中的表现
测试结果显示,英特尔 Stratix 10 FPGA 在 GEMM 稀疏、Int6 和二值化 DNN 中的表现(TOP/sec)比英伟达 Titan X Pasacal GPU 分别要好 10%、50% 和 5.4 倍。在 Ternary-ResNet 中,Stratix 10 FPGA 可以输出超过 Titan X Pascal 60% 的表现,而功耗效率则比对手好上 2.3 倍。实验结果表明:FPGA 可以成为下一代 DNN 的最佳计算平台之选。
FPGA 在深度神经网络的未来
FPGA 在下一代深度神经网络出现时能否击败 GPU 成为主流?英特尔对两代 FPGA(英特尔 Arria 10 和英特尔 Stratix 10)与英伟达 Titan X Pascal 在不同最新 DNN 上的评估表明:DNN 算法的发展趋势或许有利于 FPGA,这种架构在某些任务上的表现大幅超越对手。尽管这些测试是在 2016 年进行的,英特尔的团队已经开始对自家 FPGA 在最新 DNN 算法上的运行和优化开始了研究(如 FFT/winograd 数学变换,主动量化(aggressive quantization)和压缩)。英特尔的团队同时指出,除 DNN 以外,FPGA 在各种对延迟敏感的应用(如自动驾驶辅助系统和工业系统)中也有广泛的前景。
Huang 说道:「目前的机器学习任务都在使用 32 位密度矩阵乘法,这是 GPU 占优势的领域。我们正在鼓励开发者和研究人员加入我们重构机器学习的行列,这样才能让 FPGA 的优势发挥出来,因为 FPGA 可以适应向低精度的转变。」 
原文地址:https://www.nextplatform.com/2017/03/21/can-fpgas-beat-gpus-accelerating-next-generation-deep-learning/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








