点击上方“
朱小厮的博客
”,选择“
设为星标
”
回复”
1024
“获取独家整理的学习资料

这篇也是混沌工程相关的,之前写了《
看我如何作死| 将CPU、IO打爆
》和《
看我如何作死| 网络延迟、网络丢包、网络中断一个都没落下
》这两篇,不过这次不用作死,只是假死。
^-^
假死,有机器假死、进程假死和线程假死这几种。
让机器、进程之类的假死本身没有多大意义,探索当机器、进程之类的假死之后,其上游调用所接收到的状态(或者说得到的反馈)才有意义。
上游通过评估下游假死之后其本身所触发的动作反应以及导致的结果来分析其服务本身的质量,如果未达预期,那么就需要做进一步的整改优化。
现象
机器假死一般所表现的现象为机器本身可以ping通,但是任何其它操作没有反应,包括ssh无法登陆、内部部署的服务进程无法对外提供服务等。
对于某一台机器,首先可以开启一个服务进程,可以对外提供服务,这里假设服务端口是6666。
这个时候你可以启动一个脚本去fork 100个进程,这样来直接(如果100不够就多加一点)导致机器假死,最终ssh也登录不了这台机器。
如果还想要知道对于上游来说,下游的机器假死会得到什么样的现象的话,可以在这个时候去访问以下假死的这台机器的6666端口的服务。
这里就不卖关子了,最终上游所接收到的状态应该是会出现超时,即timeout。
一个进程结束后,它并不会立刻从内存中消失,它的进程控制块还驻留在内存中,此刻这个进程的状态变成EXIT_ZOMBIE,并且会给它的父进程发送SIGCHLD信号。
父进程收到信号后会做一些处理,然后子进程才会彻底被移除。
假死一般的进程并不会占用太多的系统资源,只会占用很少的内存。
不过,假死进程会占用PID,而Linux中的PID的数量是由限制的。
为了向下兼容,Linux中一般设定PID的上限为32767。
进程假死可以总结为不提供服务,但是还驻留在内存中。
我们可以在某台机器上运行一个主进程和一个子进程,子进程开启7777端口,对外正常提供服务。
之后关闭子进程,然后让主进程sleep一段时间,在这段时间里,子进程处于假死状态。
此时上游去访问这个7777端口的服务又会出现什么现象呢?
上游会发生connection refused。
线程假死会释放所使用的资源,但在进程表中还会保留其条目。
线程假死的时候上游会是timeout。
上面我直接告诉了各种假死场景下的测试结果,有兴趣的同学可以自行测试一下。
模拟
总结一下,假死之后上游得到的反馈要么是timeout,要么是connection refused。
这个可以让我们联想到iptables的reject和drop,他们彼此所呈现出来的状态是一样的。
模拟timeout:
iptables -A OUTPUT -p tcp --dport 6666 -j DROP
模拟connection refused:
iptables -A OUTPUT -p tcp --dport 7777 -j REJECT
我们在做故障注入或者故障演练的时候,并不是所有的时候都需要真的对某个下游服务做一些“出格”的动作。
有些故障场景下,我们可以事先测试出这个服务处于某种故障下时,上游所得到的反馈,然后通过其他的方式去模拟出同样的反馈即可。
这样当要终止故障的时候也容易快速恢复。
比如机器假死的故障,如果直接让机器假死,然后实验之后恢复时需要重启机器,反之只需要简单的撤销iptables的策略即可。
混沌工程知识补充
“故障是注定的,随着时间的流逝,一切终将归于失败”。
我们必须接受故障发生是新常态的想法,处在部分故障的系统正常运行是完全可行的。
当我们处理多达几十个服务实例的小型系统时,100%的健康运行通常是正常状态,故障则是一种特殊情况。
然而,在处理大规模系统时,即100%的健康运行几乎是不可能实现的。
因此,运维的新常态便是接受部分故障。
处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力,这里的Resilient即为韧性(具备恢复能力)。
混沌工程就是利用实验提前探知系统风险,通过架构优化和运维模式的改进来解决系统风险,真正实现上述韧性架构,降低企业损失,提高故障免疫力。
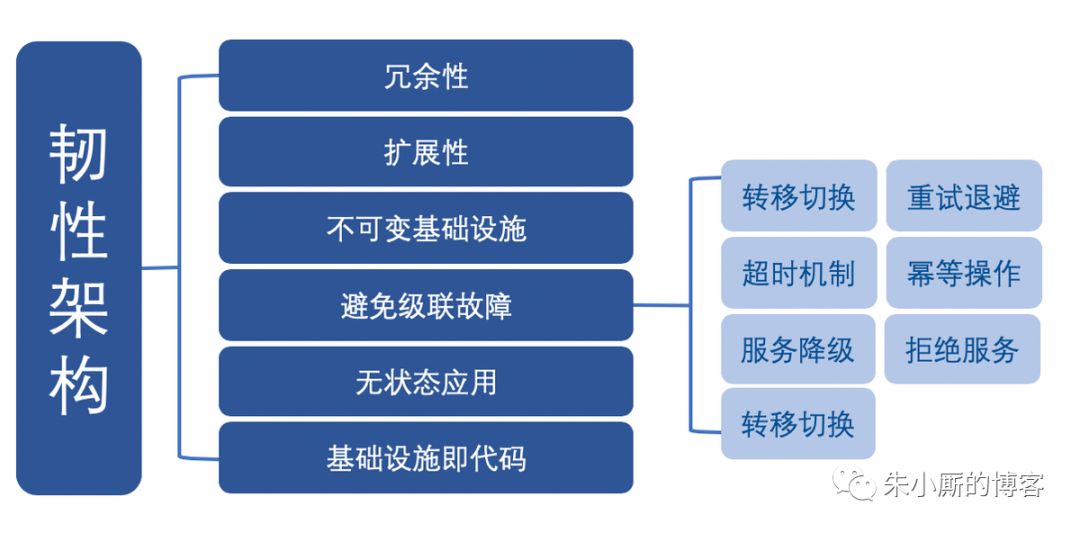
韧性架构的重要特征:
-
冗余性。架构的设计要增加冗余性,以便提高该系统的整体可用性。
-
扩展性。架构的设计必须要考虑扩展性,即启用 Auto Scaling ,根据需求动态扩展资源( 而不是手动执行) ,确保可以满足各种流量模式。
-
不可变基础设施。不可变基础设施指的是,每次部署都会替换相应的组件,不做更新。应用部署则使用金丝雀发布(俗称灰度发布),以减少部署新版本应用时出现故障的风险。使用这种技术,可以在真实的生产环境中进行测试,并在需要时进行快速回滚。
-
避免级联故障。
级联故障指的是因依赖关系引发的局部故障导致整个系统崩溃(俗称蝴蝶效应)。
架构设计必须考虑级联故障的处理方式:
-
转移切换:当一个集群宕机时,所有的流量都转移到另一个集群,如跨可用区切换,或者跨区域切换。
-
重试退避:指数退避算法逐渐对客户端重试请求减速,避免网络拥塞,同时添加抖动保证性能。
-
超时机制:过载请求会将连接耗尽,导致系统宕机。超时机制的引入,服务的质量会下降但不至于系统全面崩溃。
-
幂等操作:由于暂时的错误,客户端可能多次发送相同的请求,可能导致系统处理错误。幂等操作,一种可以反复重复的操作,没有副作用或应用程序的失败,可以消除上述隐患。
-
服务降级:当服务器压力剧增的情况下,有策略地减少或退化部分服务,以此释放服务器资源以保证核心任务的正常运行,如只读模式、停用耗时耗资源的功能等等。
-
拒绝服务:请求过载时,按优先级开始丢弃相应的请求。
-
服务熔断:若某个目标服务调用过慢或者有大量超时,直接熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回响应,快速释放资源,待目标服务情况好转则恢复调用。
-
无状态应用。无状态应用是自动扩展和不可变基础设施的先决条件,要求应用必须独立于先前的请求或会话,处理所有客户端请求,并且不会存储在本地磁盘或内存中。
-
基础设施即代码。基础设施即代码可减轻繁琐的手工配置和部署任务,由于可用完全相同的方式反复执行,因此解决了随时间推移引发的配置漂移问题,当有故障发生,基础设施的恢复快速且有效。同时可对基础架构以代码的形式进行版本控制,管理其更新、审核、验证和回溯分析。

相关推荐:
>>>Learn More
<<
点个
"在看"
呗^_^





