据IDC预测,到2021年,至少
50%
的全球GDP将由数字化驱动。面对海量数据,企业亟需通过更加现代化、敏捷、高性能的IT基础设施来推进业务持续发展。
当今世界,只有很少的数据得到了分析,还有巨大的待开发潜能,在高达
3000亿美元
的以数据为驱动的市场中,中国在人工智能、物联网和5G等技术方面已经逐渐成熟,为中国数字经济蓬勃发展奠定了基础,而那些尚未被充分利用的数据,就是新商业价值的关键元素。
数据湖支持以其本机或接近本机的格式存储数据,从而为高技能的数据科学家和分析师提供了未完善的数据视图。数据湖提供了一个没有折衷的环境,以及相应的记录分析系统所共有的保证和利益,即语义一致性,治理和安全性。
因此,数据湖特别适合科学家对未知数据和未知问题的探索。很多暂时得不到分析的数据,可以暂时统一保存在数据湖里。
Hadoop的一个主要优势是支持围绕未知数据和未知问题的这些探索性用例。它在LDW(逻辑数据仓库)中扮演的角色在基于数据管理基础设施模型的右上象限 - 未知数据领域和未知问题。由于Hadoop技术针对语义灵活性进行了优化,因此它可以与传统的结构化数据仓库并列,从而实现更广泛的数据类型,最终用户和用例。
虽然现在Hadoop没有前几年那么热,但是,它依然是数据湖最常用的解决方案。最近的Gartner研究数据表明,Hadoop的部署和需求仍然很大并且正在增长。在最近的一项调查中,有235名受访者表示,34%的受访者目前正在使用Hadoop进行数据和分析工作,另有55%的受访者计划在未来24个月内进行调查,总计达到
89%
。这是Gartner 2016年研究以来的需求最大幅度增加。
Apache Hadoop是一个高度可扩展的系统,广泛应用于大数据存储和分析。Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件上的分布式文件系统。
-
NameNode:NameNode 上保存着整个HDFS的命名空间和数据块映射关系。所有的元数据操作都将在NameNode中处理;
-
DataNode:DataNode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息;
-
DFSClient:HDFS的客户端,在Hadoop文件系统中,它封装了和HDFS其他实体的复杂交互关系,为应用提供了一个标准的、简单的接口。
Hadoop为大数据分析带来便利的同时,也面临着一些挑战:
NameNode是HDFS中的管理者,主要负责文件系统的命名空间、集群配置信息和数据块的复制等。NameNode在内存中保存文件系统中每个文件和每个数据块的引用关系,也就是元数据。
在运行时,HDFS中每个文件、目录和数据块的元数据信息(大约150字节)必须存储在NameNode的内存中。根据Cloudera的描述,默认情况下,会为每一百万个数据块分配一个最大的堆空间1GB (但绝不小于1GB)。这导致实际限制了HDFS中可以存储的对象数量,也就意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈。
同时,作为一个可扩展的文件系统,单个集群中支持数千个节点。在单个命名空间中DataNode可以扩展的很好,但是NameNode并不能在单个命名空间进行横向扩展。通常情况下,HDFS集群的性能瓶颈在单个NameNode上。
在Hadoop 2.x发行版中引入了联邦HDFS功能,允许系统通过添加多个NameNode来实现扩展,其中每个NameNode管理文件系统命名空间中的一部分。但是,系统管理员需要维护多个NameNodes和负载均衡服务,这又增加了管理成本。
在传统的Apache Hadoop集群系统中,计算和存储资源是紧密耦合的。在这样的集群中,当存储空间或计算资源不足时,只能同时对两者进行扩容。假设用户对存储资源的需求远大于对计算资源的需求,那么用户同时扩容计算和存储后,新扩容的计算资源就被浪费了,反之,存储资源被浪费。这导致扩容的经济效率较低,增加成本。
独立扩展的计算和存储更加灵活,同时可显著降低成本。因此,现在Hadoop采用存算分离的架构的趋势越来越明显,Hadoop社区普遍采用S3A客户端来对接外部对象存储。
HDFS核心组件NameNode的全局锁问题一直是制约HDFS性能,尤其是NameNode处理能力的主要因素。
HDFS在锁机制上使用粒度较粗的全局锁来统一来控制并发读写,这样处理的优势比较明显,全局锁可以简化锁模型,降低复杂度。但是由全局锁的一个比较大的负面影响是容易造产生性能瓶颈。
NameNode核心处理逻辑上涉及到两个锁:
FSNamesystemLock
(HDFS把所有请求抽象为全局读锁和全局写锁)和
FSEditLogLock
(主要控制关键元数据的修改,用于高可用),一次RPC请求处理流程经过了两次获取锁阶段,虽然两个锁之间相互独立,但如果在两处中的任意一处不能及时获取到锁,RPC都将处于排队等待状态。等锁时间直接影响请求响应性能。
再有,因为写锁具有排他性,所以对性能影响更加明显。当有写请求正在被处理,则其他所有请求都必须排队等待,直到当前写请求被处理完成释放锁。当集群规模增加和负载增高后,全局锁将逐渐成为NameNode性能瓶颈。
原生的Hadoop中包含一个的S3A连接器,基于Amazon Web Services (AWS) SDK实现的。Hadoop S3A允许Hadoop集群连接到任何与S3兼容的对象存储。
XSKY的对象存储产品XEOS兼容S3协议,所以可以通过S3A连接器与Hadoop应用进行交互,但这种方式存在比较大的局限性。
通过上图,可以看到Hadoop应用通过S3A客户端上传数据时,需要调用S3 SDK把请求封装成HTTP然后发送给XEOS对象路由,然后再由对象路由转发到XEOS的S3网关,最后通过S3网关将数据写入XEOS存储集群,从而达到数据上传的目的。下载文件也是一样的道理。
S3A虽然同样可以实现计算和存储分离,但基本架构和协议兼容性上还是存在一些问题:
为了解决S3A的问题,XSKY开发了
XSKY HDFS Client
——XEOS存储集群和Hadoop计算集群量身打造的连接器。
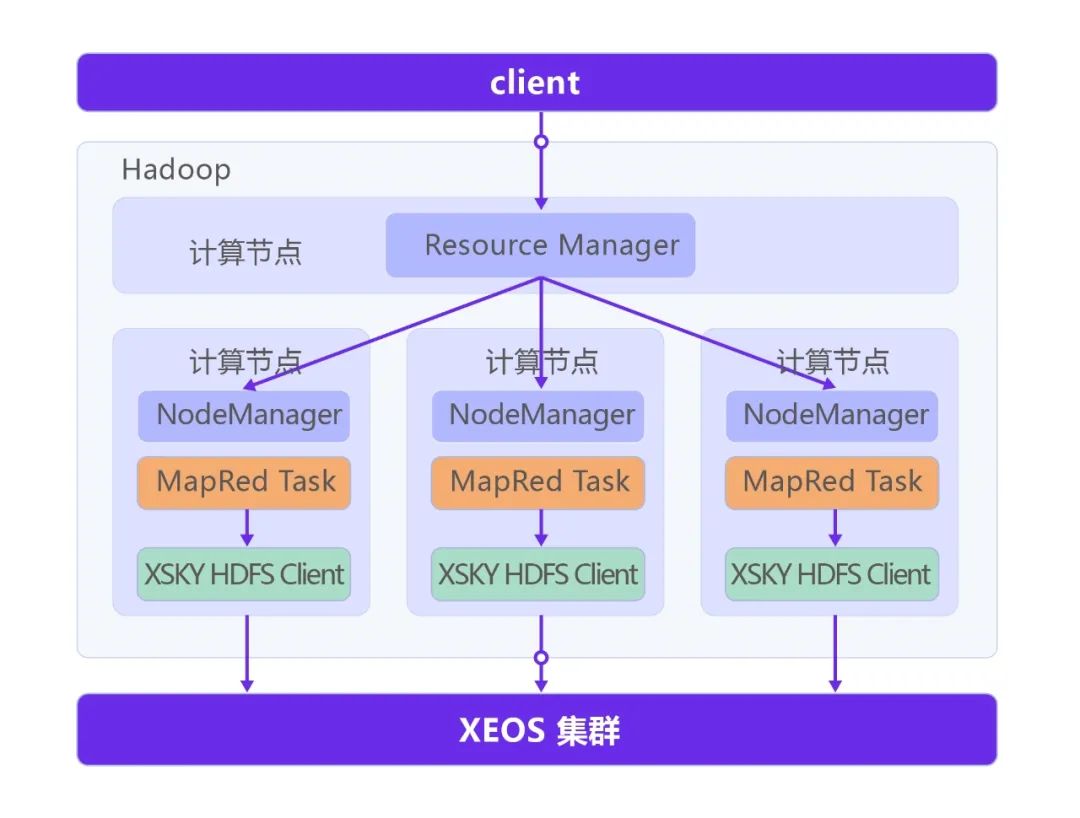
通过XSKY HDFS Client(简称“XHC”),Hadoop应用可以访问存储在XEOS中的所有数据,这就避免了传统的Hadoop应用在进行数据分析前,还要将数据由业务存储移动到分析存储HDFS中,也就是常见的ETL过程。
XSKY HDFS Client相当于HDFS的DFSClient,为Hadoop应用提供了标准的 Hadoop文件系统API。在每个计算节点上,Hadoop应用都将使用XSKY HDFS Client (JAR) 执行 Hadoop文件系统的操作,并且屏蔽了Hadoop应用与XEOS集群交互的复杂性。在XEOS集群中,每一个存储节点都等效于HDFS的NameNode和DataNode。
相比于S3A通过S3 SDK封装HTTP请求的方式访问XEOS不同,XSKY HDFS Client可以直接访问存储集群的OSD,IO路径上要短得多。
XSKY HDFS Client通过
XEOS提供的NFS风格的接口与XEOS集群进行交互
,这种实现方式的优势主要体现在:
XSKY HDFS Client本身是一个由Java实现的JAR包。作为Hadoop兼容的文件系统,XSKY HDFS Client需要按照Hadoop FileSystem API规范来实现,也就是实现抽象的Hadoop FileSystem、OutputStream和InputStream。其中,XSKY HDFS Client的FileSystem主要实现了Hadoop FileSystem的list、delete、rename、mkdir等接口,而InputStream和OutputStream主要实现了对XEOS对象的读写功能。
XSKY HDFS Client会将Hadoop应用的Java调用,通过JNI (Java Native Interface) 技术转换为本地librgw.so的调用,并最终访问到XEOS集群。在计算节点上,需要部署XSKY HDFS Client JAR包、librgw.so及其依赖的so库和配置文件。
XSKY HDFS Client应该在所有需要访问XEOS存储的计算节点部署。XSKY提供了自动化部署工具,用于简化部署的过程。
在使用时,需要将XSKY HDFS Client配置到计算节点的core-site.xml文件中。Hadoop应用加载core-site.xml配置后,便会获得scheme与XSKY HDFS Client的映射关系。如访问时使用“eos://localhost/user/dir/”,Hadoop会获取到“eos”这个scheme并通过映射关系,选择XSKY HDFS Client来处理请求。最终XSKY HDFS Client调用XEOS的NFS接口来处理完成与XEOS的通讯。
以YARN(MapReduce2)为例,在Hadoop中使用XEOS的示例如下。JobClient将Job提交给YARN,YARN将Job拆分成多个Map和Reduce子任务并执行。在Map或Reduce阶段均可通过XSKY HDFS Client访问XEOS,进行读写等操作。