我一直觉得,爬虫是许多web开发人员难以回避的点。我们也应该或多或少的去接触这方面,因为可以从爬虫中学习到web开发中应当掌握的一些基本知识。而且,它还很有趣。
我是一个知乎轻微重度用户,之前写了一只爬虫帮我爬取并分析它的数据,我感觉这个过程还是挺有意思,因为这是一个不断给自己创造问题又去解决问题的过程。其中遇到了一些点,今天总结一下跟大家分享分享。
它都爬了什么?
先简单介绍下我的爬虫。它能够定时抓取一个问题的关注量、浏览量、回答数,以便于我将这些数据绘成图表展现它的热点趋势。为了不让我错过一些热门事件,它还会定时去获取我关注话题下的热门问答,并推送到我的邮箱。
作为一个前端开发人员,我必须为这个爬虫系统做一个界面,能让我登陆知乎帐号,添加关注的题目、话题,看到可视化的数据。所以这只爬虫还有登陆知乎、搜索题目的功能。
然后来看下界面。
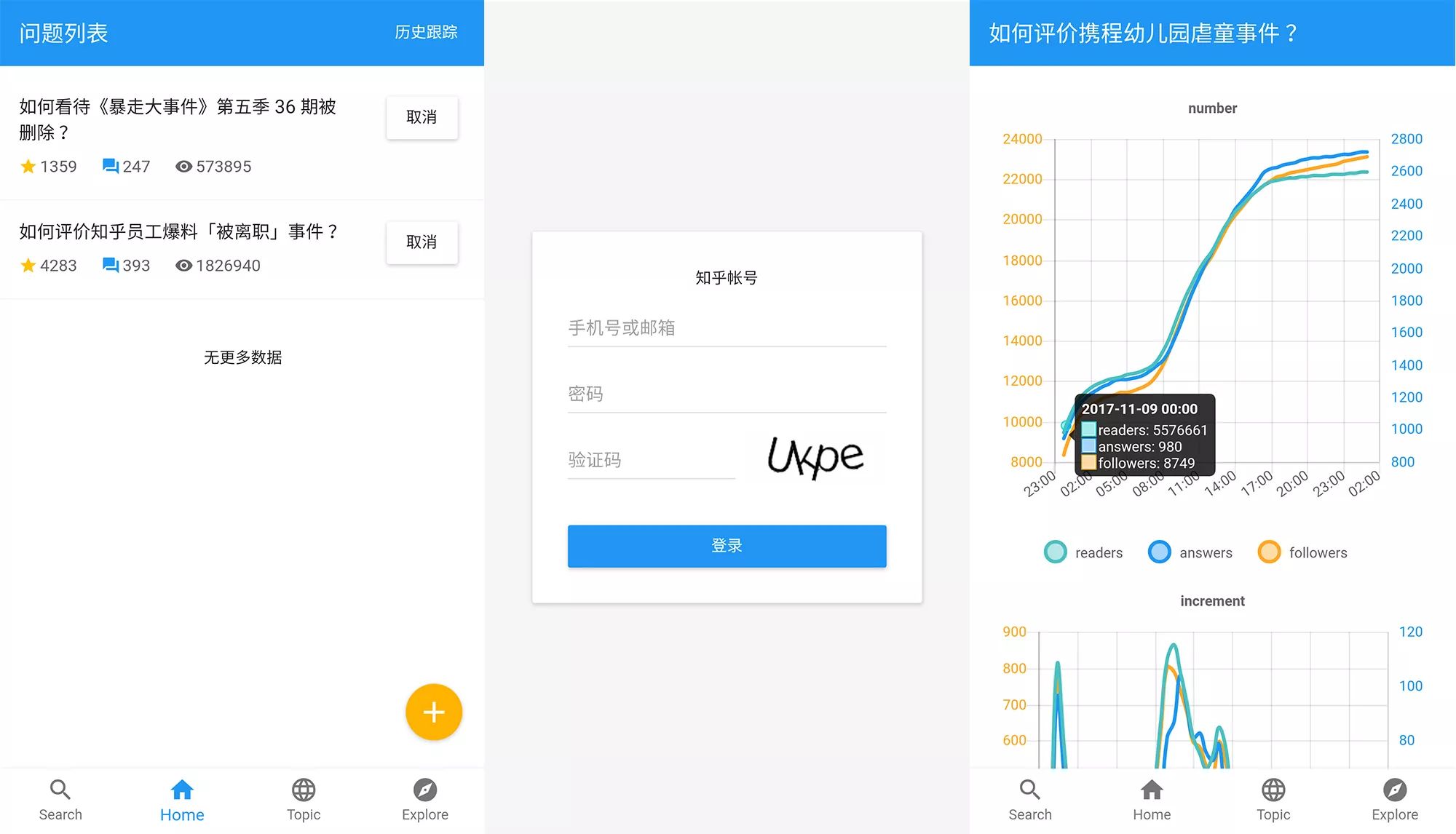
下面正儿八经讲它的开发历程。
技术选型
Python得益于其简单快捷的语法、以及丰富的爬虫库,一直是爬虫开发人员的首选。可惜我不熟。当然最重要的是,作为一名前端开发人员,node能满足爬虫需求的话,自然更是首选。而且随着node的发展,也有许多好用的爬虫库,甚至有puppeteer这样直接能模拟Chrome访问网页的工具的推出,node在爬虫方面应该是妥妥能满足我所有的爬虫需求了。
于是我选择从零搭建一个基于koa2的服务端。为什么不直接选择egg,express,thinkjs这些更加全面的框架呢?因为我爱折腾嘛。而且这也是一个学习的过程。如果以前不了解node,又对搭建node服务端有兴趣,可以看我之前的一篇文章-从零搭建Koa2 Server。
爬虫方面我选择了request+cheerio。虽然知乎有很多地方用到了react,但得益于它绝大部分页面还是服务端渲染,所以只要能请求网页与接口(request),解析页面(cherrio)即可满足我的爬虫需求。
其他不一一举例了,我列个技术栈
服务端
-
koajs 做node server框架;
-
request + cheerio 做爬虫服务;
-
mongodb 做数据存储;
-
node-schedule 做任务调度;
-
nodemailer 做邮件推送。
客户端
-
vuejs 前端框架;
-
museui Material Design UI库;
-
chart.js 图表库。
技术选型妥善后,我们就要关心业务了。首要任务就是真正的爬取到页面。
如何能爬取网站的数据?
知乎并没有对外开放接口能让用户获取数据,所以想获取数据,就得自己去爬取网页信息。我们知道即使是网页,它本质上也是个GET请求的接口,我们只要在服务端去请求对应网页的地址(客户端请求会跨域),再把html结构解析下,获取想要的数据即可。
那为什么我要搞一个登陆呢?因为非登陆帐号获取信息,知乎只会展现有限的数据,而且也无法得知自己知乎帐户关注的话题、问题等信息。而且若是想自己的系统也给其他朋友使用,也必须搞一个帐户系统。
模拟登陆
大家都会用Chrome等现代浏览器看请求信息,我们在知乎的登录页进行登陆,然后查看捕获接口信息就能知道,登陆无非就是向一个登陆api发送账户、密码等信息,如果成功。服务端会向客户端设置一个cookie,这个cookie即是登陆凭证。
所以我们的思路也是如此,通过爬虫服务端去请求接口,带上我们的帐号密码信息,成功后再将返回的cookie存到我们的系统数据库,以后再去爬取其他页面时,带上此cookie即可。
当然,等我们真正尝试时,会受到更多挫折,因为会遇到token、验证码等问题。不过,由于我们有客户端了,可以将验证码的识别交给真正的
人
,而不是服务端去解析图片字符,这降低了我们实现登陆的难度。
一波三折的是,即使你把正确验证码提交了,还是会提示验证码错误。如果我们自己做过验证码提交的系统就能够迅速的定位原因。如果没做过,我们再次查看登陆时涉及的请求与响应,我们也能猜到:
在客户端获取验证码时,知乎服务端还会往客户端设置一个新cookie,提交登陆请求时,必须把验证码与此cookie一同提交,来验证此次提交的验证码确实是当时给予用户的验证码。
语言描述有些绕,我以图的形式来表达一个登陆请求的完整流程。
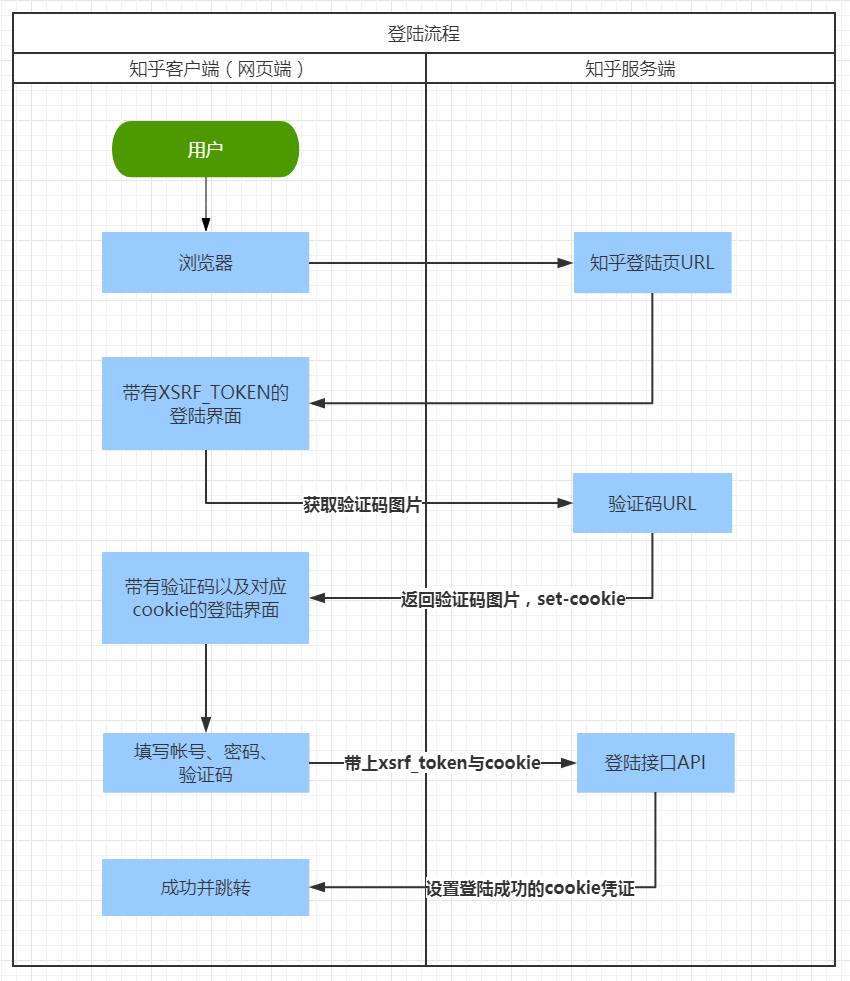
注:我编写爬虫时,知乎还部分采取图片字符验证码,现已全部改为“点击倒立文字”的形式。这样会加大提交正确验证码的难度,但也并非无计可施。获取图片后,由
人工
识别并点击倒立文字,将点击的坐标提交到登陆接口即可。当然有兴趣有能力的同学也可以自己编写算法识别验证码。
爬取数据
上一步中,我们已经获取到了登陆后的凭证cookie。用户登陆成功后,我们把登陆的帐户信息与其凭证cookie存到mongo中。以后此用户发起的爬取需求,包括对其跟踪问题的数据爬取都根据此cookie爬取。
当然cookie是有时间期限的,所以当我们存cookie时,应该把过期时间也记录下来,当后面再获取此cookie时,多加一步过期校验,若过期了则返回过期提醒。
爬虫的基础搞定后,就可以真正去获取想要的数据了。我的需求是想知道某个知乎问题的热点趋势。先用浏览器去看看一个问题页面下都有哪些数据,可以被我爬取分析。举个例子,比如这个问题:有哪些令人拍案叫绝的推理桥段。
打开链接后,页面上最直接展现出来的有
关注者
,
被浏览
,
1xxxx个回答
,还要默认展示的几个高赞回答及其点赞评论数量。右键查看网站源代码,确认这些数据是服务端渲染出来的,我们就可以通过request请求网页,再通过cherrio,使用css选择器定位到数据节点,获取并存储下来。代码示例如下:
async getData (cookie, qid) {
const options = {
url: `${zhihuRoot}/question/${qid}`,
method: 'GET',
headers: {
'Cookie': cookie,
'Accept-Encoding'
: 'deflate, sdch, br' // 不允许gzip,开启gzip会开启知乎客户端渲染,导致无法爬取
}
}
const rs = await this.request(options)
if (rs.error) {
return this.failRequest(rs)
}
const $ = cheerio.load(rs)
const NumberBoard = $('.NumberBoard-item .NumberBoard-value')
const $title = $('.QuestionHeader-title')
$title.find('button').remove()
return {
success: true,
title: $title.text(),
data: {
qid: qid,
followers: Number($(NumberBoard[0]).text()),
readers: Number($(NumberBoard[1]).text()),
answers:
Number($('h4.List-headerText span').text().replace(' 个回答', ''))
}
}
}
这样我们就爬取了一个问题的数据,只要我们能够按一定时间间隔不断去执行此方法获取数据,最终我们就能绘制出一个题目的数据曲线,分析起热点趋势。
那么问题来了,如何去做这个定时任务呢?
定时任务
我使用了node-schedule做任务调度。如果之前做过定时任务的同学,可能对其类似cron的语法比较熟悉,不熟悉也没关系,它提供了not-cron-like的,更加直观的设置去配置任务,看下文档就能大致了解。
当然这个定时任务不是简单的不断去执行上述的爬取方法
getData
。因为这个爬虫系统不仅是一个用户,一个用户不仅只跟踪了一个问题。
所以我们此处的完整任务应该是遍历系统的每个cookie未过期用户,再遍历每个用户的跟踪问题,再去获取这些问题的数据。
系统还有另外两个定时任务,一个是定时爬取用户关注话题的热门回答,另一个是推送这个话题热门回答给相应的用户。这两个任务跟上述任务大致流程一样,就不细讲了。
但是在我们做定时任务时会有个细节问题,就是如何去控制爬取时的并发问题。具体举例来说:如果爬虫请求并发太高,知乎可能是会限制此IP的访问的,所以我们需要让爬虫请求一个一个的,或者若干个若干个的进行。
简单思考下,我们会采取循环await。我不假思索的写下了如下代码:
// 爬虫方法
async function getQuestionData () {
// do spider action
}
// questions为获取到的关注问答
questions.forEach(await getQuestionData)
然而执行之后,我们会发现这样其实还是并发执行的,为什么呢?其实仔细想下就明白了。forEach只是循环的语法糖,如果没有这个方法,让你来实现它,你会怎么写呢?你大概也写的出来:
Array.prototype.forEach = function (callback) {
for (let i = 0; i < this.length; i++) {
callback(this[i], i, this)
}
}
虽然
forEach
本身会更复杂点,但大致就是这样吧。这时候我们把一个异步方法作为参数
callback
传递进去,然后循环执行它,这个执行依旧是并发执行,并非是同步的。
所以我们如果想实现真正的同步请求,还是需要用for循环去执行,如下:
async function getQuestionData () {
// do spider action
}
for (let i = 0; i < questions.length; i++) {
await getQuestionData()
}
除了for循环,还可以通过for-of,如果对这方面感兴趣,可以去多了解下数组遍历的几个方法,顺便研究下ES6的迭代器
Iterator
。
其实如果业务量大,即使这样做也是不够的。还需要更加细分任务颗粒度,甚至要加代理IP来分散请求。
合理搭建服务端
下面说的点跟爬虫本身没有太大关系了,属于服务端架构的一些分享,如果只关心爬虫本身的话,可以不用再往下阅读了。
我们把爬虫功能都写的差不多了,后面只要编写相应的路由,能让前端访问到数据就好了。但是编写一个没那么差劲的服务端,还是需要我们深思熟虑的。
合理分层
我看过一些前端同学写的node服务,经常就会把系统所有的接口(router action)都写到一个文件中,好一点的会根据模块分几个对于文件。
但是如果我们接触过其他成熟的后端框架、或者大学学过一些J2EE等知识,就会本能意识的进行一些分层:
-
model
数据层。负责数据持久化,通俗说就是连接数据库,对应数据库表的实体数据模型;
-
service
业务逻辑层。顾名思义,就是负责实现各种业务逻辑。
-
controller
控制器。调取业务逻辑服务,实现数据传递,返回客户端视图或数据。
当然也有些框架或者人会将业务逻辑
service
实现在
controller
中,亦或者是
model
层中。我个人认为一个稍微复杂的项目,应该是单独抽离出抽象的业务逻辑的。
比如在我这个爬虫系统中,我将数据库的添删改查操作按
model
层对应抽离出
service
,另外再将爬取页面的服务、邮件推送的服务、用户鉴权的服务抽离到对应的
service
。
最终我们的
api
能够设计的更加易读,整个系统也更加易拓展。
分层在koa上的实践
如果是直接使用一个成熟的后端框架,分层这事我们是不用多想的。node这样的框架也有,我之前介绍的我厂开源的api-mocker采用的egg.js,也帮我们做好了合理的分层。
但是如果自己基于koa从零搭建一个服务端,在这方面上就会遇到一些挫折。koa本身逻辑非常简单,就是调取一系列中间件(就是一个个function),来处理请求。官方自己提供的koa-router,即是帮助我们识别请求路径,然后加载对应的接口方法。
我们为了区分业务模块,会把一些接口方法写在同一个
controller
中,比如我的questionController负责处理问题相关的接口;topicController负责处理话题相关的接口。
那么我们可能会这样编写路由文件:
const Router = require('koa-router')
const router = new Router()
const question = require('./controller/question')
const topic = require('./controller/topic')
router.post('/api/question', question.create)
router.get('/api/question', question.get)
router.get('/api/topic', topic.get)
router.post('/api/topic/follow', topic.follow)
module.exports = router
我的question文件可能是这样写的:
class
Question {
async get () {
// return data
}
async create () {
// create question and return data
}
}
module.exports = new Question()
那么问题就来了
单纯这样写是没有办法真正的以面向对象的形式来编写
controller
的。为什么呢?
因为我们将question对象的属性方法作为中间件传递到了
koa-router
中,然后由
koa
底层来合并这些中间件方法,作为参数传递到
http.createServer
方法中,最终由node底层监听请求时调用。那这个
this
到底会是谁,不进行调试,或者查看koa与node源代码,是无从得知的。但是无论如何方法调用者肯定不是这个对象自身了(实际上它会是
undefined
)。
也就是说,我们不能通过
this
来获取对象自身的属性或方法。
那怎么办呢?有的同学可能会选择将自身一些公共方法,直接写在
class
外部,或者写在某个
utils
文件中,然后在接口方法中使用。比如这样:
const error = require('utils/error')
const success = (ctx, data) => {
ctx.body = {
success: true,
data: data
}
}
class Question {
async get () {
success(data)
}
async create () {
error(result)
}
}
module.exports =
new Question()
这样确实ok,但是又会有新的问题---这些方法就不是对象自己的属性,也就没办法被子类继承了。
为什么需要继承呢?因为有时候我们希望一些不同的
controller
有着公共的方法或属性,举个例子:我希望我所有的成功or失败都是这样的格式:
{
success: false,
message:
'对应的错误消息'
}
{
success: true,
data: '对应的数据'
}
按照
koa
的核心思想,这个通用的格式转化,应该是专门编写一个中间件,在路由中间件之后(即执行完controller里的方法之后)去做专门处理并response。
然而这样会导致每有一个公共方法,就必须要加一个中间件。而且
controller
本身已经失去了对这些方法的控制权。这个中间件是执行自身还是直接
next()
将会非常难判断。
如果是抽离成
utils
方法再引用,也不是不可以,就是方法多的话,声明引用稍微麻烦些,而且没有抽象类的意义。
更理想的状态应该是如刚才所说的,大家都继承一个抽象的父类,然后去调用父类的公共相应方法即可,如:
class
AbstractController {
success (ctx, data) {
ctx.body = {
success: true,
data: data
}
}
error (ctx, error) {
ctx.body = {
success: false,
msg: error
}
}









