暑期Stata培训班招生啦!!!接力线上的网课培训,我们在今夏又开始新一轮的线下培训啦!
8月4日至12日
,爬虫俱乐部期待与您的相遇!培训具体内容详见推文
《暑期Stata编程技术定制培训班》
。
有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱
[email protected]
,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的
github
主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
好消息:爬虫俱乐部隆重推出数据定制及处理业务啦,您有任何网页数据获取及处理方面的难题,请发邮件至我们邮箱
[email protected]
,届时会有俱乐部资深高级会员为您排忧解难!
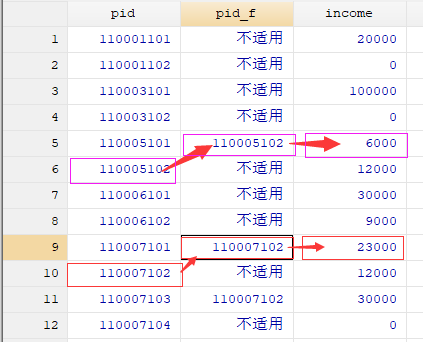
之前,有粉丝提问,如何处理变量之间跨行匹配的问题。见下图示例中标红的部分,就是将变量pid与pid_f下相同的身份代码匹配并保留与pid_f 相对应的income值。其中pid表示个人身份代码,pid_f表示其“爹“的身份代码,income表示“爹”的收入。通俗的讲就是给每个人找“爹”并把与之相对应“爹”的收入保留下来。我们将介绍两种方法解决这一问题(
原始数据链接
:
https://github.com/Stata-Club/Sharing-Center-of-StataClub/blob/master/article/2018uf%E5%8E%9F%E5%A7%8B%E6%95%B0%E6%8D%AE.dta?raw=true
,感兴趣的读者可以自行下载)。
思路分析:“当你解决不了问题的时候,别忘了post。”,我们利用循环将个人(pid)的每一个身份代码与其爹(pid_f)每一个身份代码进行匹配,如果个人(pid)的 身份代码等于其爹(pid_f)的身份代码,则通过post命令输出他们的身份代码及相对应的“爹“的收入。
我们先help一下post命令的用法:

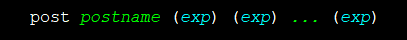
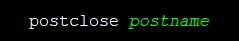
postname
:定义一个post的名称。
newvarlist
:定义输出变量的名称,可以是数值型,也可以是字符型。
filename
:指定输出结果的位置。
replace
:代替已有同名文件。
post
:输出结果。
postclose
:结束整个post过程。
我们可以把这整个使用过程当作一个
邮件寄送的过程
,首先定义一个邮件系统的名称(postname),其次,指定需要邮寄的信息(newvarlist)和收信位置(filename),然后,邮寄出指定的内容(post),最后结束邮递过程(postclose)。
接下来我们开始进行匹配工作。首先,用以下命令行对原始数据进行转码:
clear
cd E:\直播课程\qq群问答
unicode encoding set gb18030
unicode translate " 2018uf原始数据.dta", transutf8 invalid
unicode erasebackups, badidea
其次,建立循环匹配出我们需要的数值并输出。
use 2018uf原始数据.dta, clear
capture postclose mypost
postfile mypost long pid ///
long pid_f long income ///
using mypost.dta, replace
forvalues i = 1 (1)`=_N'{ // 对pid变量下的每个身份代码进行循环
forvalues j = 1/ `=_N'{ // 对pid_f变量的每个身份代码进行循环
while pid[`i'] == pid_f[`j']{ // 判断个人身份代码是否匹配其“爹“的身份代码
post mypost (pid[`i']) (pid_f[`j']) (income[`j']) // 输出符合判断语句的观测值
continue, break
}
}
}
postclose mypost
use mypost.dta,clear
br in 1/10
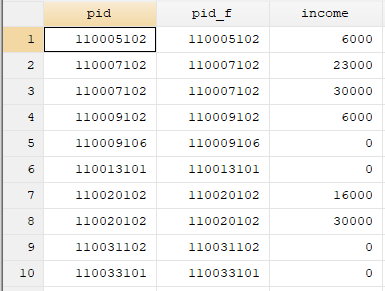
在上述循环过程中,由于pid下的每一个身份代码都要和pid_f下的每个身份代码相匹配,即要循环n*n次(n为样本值),如果样本值很大的话,这无疑会耗费大量时间。下面介绍另外一种方法。
利用merge命令,先保留一份个人身份代码(pid),然后再保留一份pid_f的身份代码及其相对应的收入(income),最后利用merge将二者合并保留完全匹配的数据。
代码如下:
use 2018uf原始数据.dta,clear
keep pid
rename pid id
save 1,replace
use 2018uf原始数据.dta,clear
drop pid
drop if pid_f == 0
rename pid_f id
save 2,replace
merge m:1 id using 1.dta
keep if _m == 3 drop _m
br in 1/10
结果如图所示(id为pid与pid_f都匹配上的变量)
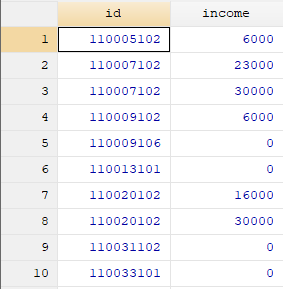
小结:以上两种方法都达到了匹配的效果,读者朋友们如有需求,可视具体情况选择其中一种方法使用。
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Hello,MySQL-odbc exec查询与更新
7.
Python第一天









