加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都点了这里。
今天大家讨论比较多的人工智能,包括深度学习等这些技术为什么会对我们有帮助?究竟背后在什么地方能够去改变这个世界?在今天于深圳举办的中国人工智能产业大会上,人工智能公司第四范式创始人兼CEO戴文渊就其专业研究以及产业实践对这些问题做了阐述。雷锋网也与其进行了访谈。
第四范式是一家利用机器学习、迁移学习等人工智能技术进行大数据价值挖掘的公司,其CEO戴文渊被业内认为是迁移学习全球领军学者。据雷锋网了解,戴文渊2005年曾获得ACM国际大学生程序设计竞赛世界总冠军。他2009-2013年就职于百度,是百度广告变现算法的核心负责人,也是百度凤巢的总架构师,是最年轻的百度高级科学家,2012年获得百度最高奖(百万美元奖)。在其后的2013-2014年,戴文渊就职华为,任华为诺亚方舟实验室主任科学家。
戴文渊表示,大数据不再是AI发展瓶颈,未来企业的机遇在于赢在“维度”。如果企业内部用人工智能知道企业经营,最重要的就是要去做高VC维模型,我们要不断地提高模型的维度,使得training loss和test loss不断的降低。VC维度是什么?大脑的维度大概就是大脑脑细胞的个数,所以可以把VC维度理解为脑细胞维度。而机器的维度也需要更多的脑细胞,才能更聪明,才能学习更多的知识。机器的误差随着模型维度的提升而降低。
“VC维”是什么?

VC维度是什么东西?学术一点来说是“Vapnik-Chervonenkis Dimension”,一个由Vapnik和Chervonenkis于1960年代至1990年代建立的统计学习理论,它反映了函数集的学习能力——VC维越大则模型或函数越复杂,学习能力就越强。

戴文渊以一个比喻解释:大脑的维度大概就是大脑脑细胞的个数,所以为什么人比狗聪明,狗比蟑螂聪明,因为人的脑细胞比狗多,所以可以把VC维度理解为脑细胞维度。同时这就可以理解:为什么要把机器的维度做高——因为机器的维度也需要更多的脑细胞,才能更聪明,才能学习更多的知识。
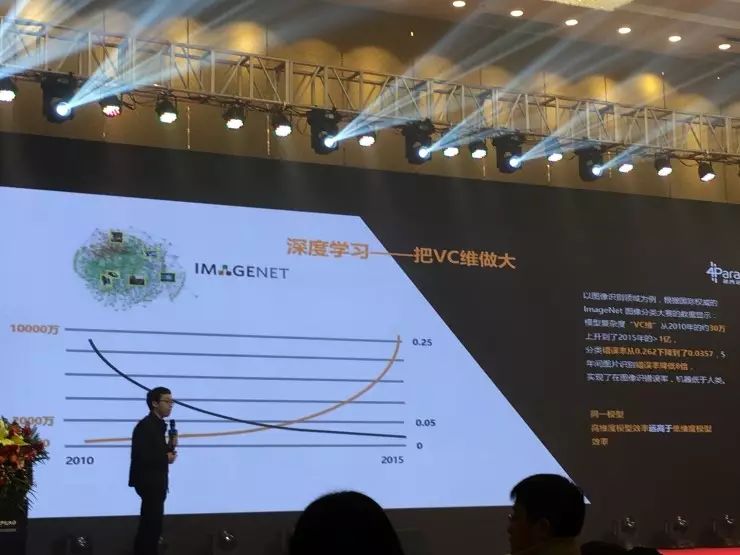
上图是IMGENET比赛的结果示意图。过去对于这个比赛,大家关心最多的是黑线曲线——它表示着是每年冠军的错误率。因此大家都知道,每年冠军的错误率误差都在降低。但是戴文渊看到的是另一个问题:很少有人关心黄色的曲线——它代表着每年冠军模型的VC维。所以这是我们也可以发现,为什么错误率会降低?是因为模型的维度在提升。随着模型维度的提升,我们的误差开始降低。

所以,今天的深度学习、强化学习都是要把维度做大。“深度学习其实是一种更好的去把VC维做高的算法,”戴文渊说道,“而为什么要做强化学习?强化学习是一个不断VC维做得越来越大的模型。举个例子——谷歌的阿尔法狗,如果只做深度学习,它是基于KJS的网站上棋局做的模型,那只有30万局棋;强化学习以后,通过自己和自己下,不断地去提升,最后能够达到8000万局棋,所以这就是今天强化学习要做的事情,这都是要把维度越做越大。”
三个案例说明:为什么需要把VC维做大
维度做得更高更细,分析才能做得更精细,效率才能够提高。
去年亚马逊的市值超过了沃尔玛,更多的人会觉得亚马逊超过沃尔玛是互联网颠覆传统企业的。但这真的是互联网方面带来的厉害?“其实这背后是人工智能。在2010年前亚马逊做的并不是比沃尔玛成功的,但之后,亚马逊基于其数据能够让大家看到亚马逊的商品都是不一样的,亚马逊实际上是给每个人开了一家店。”
一家企业如何能同时开出3亿多家个性化的店?亚马逊有3亿多的用户,而沃尔玛有一万多家店,亚马逊显然是要解决一个比沃尔玛复杂3万多倍的问题。
“要解决3亿多家店,就不是那么好解决,不太可能人工去设计布置3亿多家店,这由谁来解决?由机器解决。机器没有精力的局限,人不是说如何去开更多的店,而是人没有精力开那么多店,用机器解决就是人工智能帮助亚马逊超过沃尔玛最重要的地方。”
所以,维度做得更高更细,分析才能做得更精细,效率才能够提高。
除了客户管理方面,仓储也体现了亚马逊人工智能分析维度的作用。

戴文渊介绍,沃尔玛的仓储是所有的保管员、仓库配货员都会去仓库整理东西,但是亚马逊的机器人是——需要这个货物就搬过来,如果亚马逊有个N个配货员就有N种不一样的货架,这样的摆放也是基于数据来做的,最后造成的一个差别就是——亚马逊比沃尔玛提升4倍。
过去我们谈互联网,移动互联网,现在谈人工智能,其实互联网和移动互联网时代,有大量的空地,我们做一个网站,可以圈一批客户,我们做一个APP可以圈一批客户,而到今天这个机会已经没有了,未来的机会在哪?不是说还有更多的客户可以去圈,而是我可以做得更好。如果要让一家企业做得比竞争对手更好,就会把预算抢过来,就像亚马逊从沃尔玛那边抢过来一样。
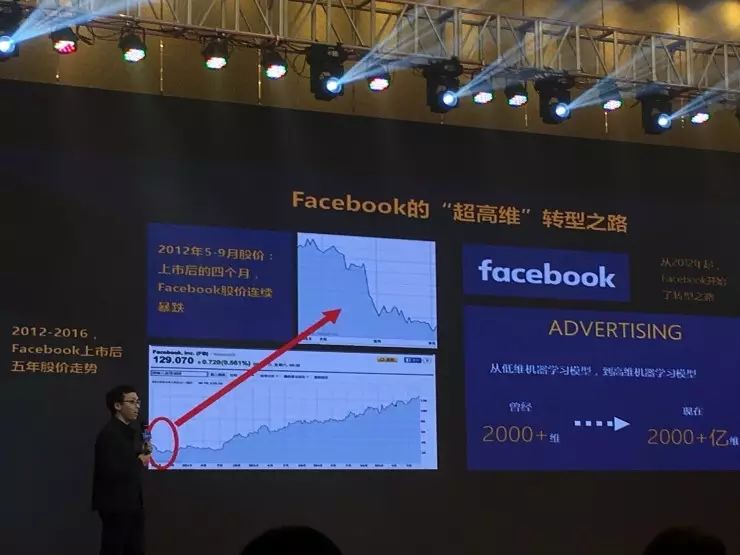
另外一个案例是脸书(Facebook),此前该公司因为变现能力受到质疑而股价一直往下走,但现在是很风光的状态。戴文渊讲起这背后的故事:
在2012年,戴文渊面试过一些来自脸书的工程师,面完了以后他发现,不是脸书不能赚钱,而是当时的技术不足以(实现)很高的变现效率。“我当时问了工程师一个问题‘脸书的广告有多少的变量?’,他们告诉我有两千多的变量,于是他就没有通过面试,因为我们当时已经做到了一百多亿的变量,这是巨大的差别。”
但是脸书发生了一个很大的变化,这是谷歌帮了他们。当年谷歌印度人与白人团队的战争,导致白人团队离开谷歌到了脸书,帮助他们把变量数从两千多个提升多了两千多亿个。这一下子让脸书的变现能力大幅度提升,之后他们的财报都超过了华尔街的预期。
所以这里很关键的地方是维度。原来是用机器学习——也是用大数据做的广告模型,但是做得不够高不够细,如果能够把维度做得更高,你就能做得更精细,你的效率就能提升,获得更多的广告市场。
VC维做高做大后还让AI产业有更大的想象空间
除了互联网IT这些数据密集型的行业,金融业也是数据量不可小觑、用户群体涉及广泛的行业,因此,这首先也成为了AI产业应用孵化的首选之地。

“今天已经不再是亚马逊、谷歌或者BAT的时代,如果退回五六年前做AI,就只能去BAT,在美国可能是谷歌脸书这样的公司,但今天其实有更多的企业拥有数据。”
戴文渊介绍了第四范式与银行合作的案例,其客户是一家深圳的股份制商业银行。作为一家商业银行,他们也有很多营销数据,需要通过这些数据去精准识别所有客户当中有哪些是分期客户,历史上有大量的客户办分期或者不办分期,第四范式的任务是基于银行的数据帮助他们更好地识别。
“过去他们不是不做营销,他们也是做营销的,但是他们的模型维度只有两百多个,而我们通过数据,通过机器学习,帮助他把维度提升到了五千万,从两百到五千万的精细营销,甚至我们可以帮他发现一些业务规律。比如当有一笔交易出现在某一个POS机,这个POS机一个月只有两百人使用的时候,是一个商机。所以,通过机器就能够用更高效、更低成本的方式来识别出这些场景。”
做高维度是与过去理论相悖的,为什么今天可以做到?
根据前面讲到几个案例,戴文渊表示,最大的差别就是过去我们在做的事情是低维的事情,而现在做的是高维的事情。“这可能跟我在学生时代学习的一些基本原理是相违背的——过去我们学数据挖掘的时候,有一个叫奥卡姆剃刀原理,它讲的是尽可能简单,而不是做深维的事情,而我们现在不是做化繁为简,而是把问题做复杂。”

他继续解释说:
比如说(图右)奥卡姆剃刀原理区分红点和蓝点的时候,到底是选择绿色的线区分还是黑色线区分?过去的教科书是说黑色比绿色好,现在我们认为是绿色比黑色好。为什么呢?过去的奥卡姆原理在做神经网络的时候,为什么我们要把神经网络控制在三层以内?是因为那个年代的数据量不够。
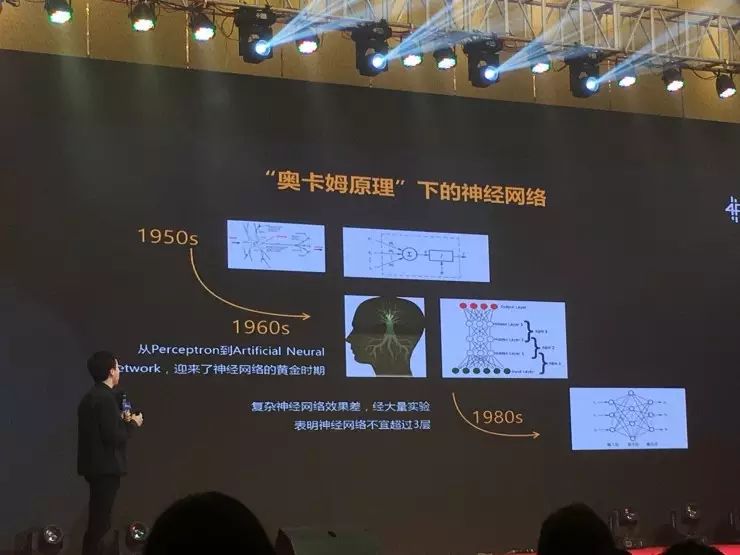
那个年代的数据不多,所以数据不足以支撑我们把数据做大。在数据量不大的时候,我们要化繁为简。而真正统计学习的基石并不是奥巴姆剃刀,不是说要控制三层,真正统计学习的原理叫VALIANT引理——这个公式我们可以就理解成,其实要做到的是模型的复杂度和规则数或者变量数,这样一个数据量相匹配。

从这个原理我们会知道——为什么过去做的模型简单,为什么神经网络要深度学习?重点的原因就是现在数据量变大了。数据量变大了,模型的复杂度要和数据量成匹配,要相关。
所以,以往的定律、原理也许都是局限下的产物。“牛顿三大定律交给计算机做会怎么做?可能不是三大定律,可能是做速度区间划分,如果说总结出三千万个定律的时候可能就不需要相对论了,这就是大数据时代,我们怎么让机器做到一些不一样的事情。”
“从VALIANT引理来看,为什么牛顿提的是三大定律而不是三百三千定律?就是人的记忆是有局限的,人脑里面装不了大数据,所以人能产出的就是简单的模型。为什么说过去的算法也很简单?过去做决策,要减到五千以内,其实很重要的原因是过去的数据量有限。”

今天整个时代变了,我们从互联网上可以获得大量的数据,传统企业其实也有大量的数据,比如说华大基因要测百万人的基因,中石油每天探测回来的地震波有500T,招行每月会有几亿的交易,这些都是非常大的数据。这时候如果还是套用valiant引理的话,数据量大了,模型会复杂。
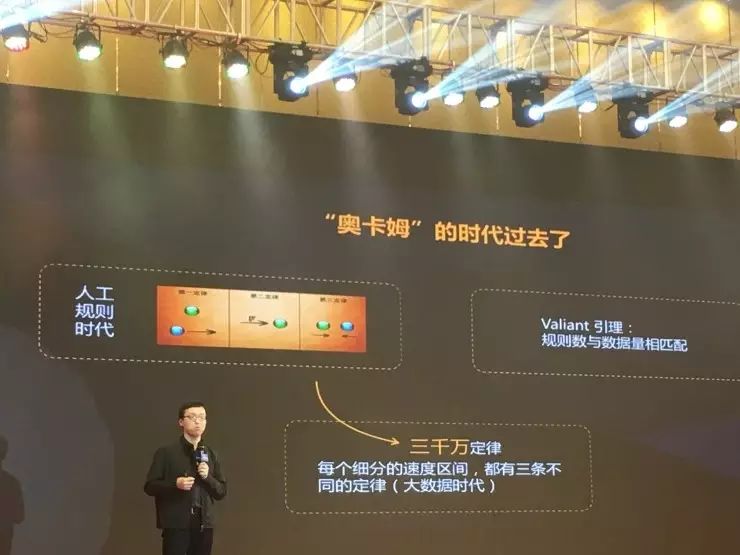
“‘奥卡姆’时代过去了。从工业界来说,如果我们企业内部做人工智能指导企业经营,最重要的就是我们要去做高VC维模型,我们要不断的去提高模型的维度,使得training loss和test loss不断的降低。”
用小数据实现超高维的迁移学习,是下一个研究风向?
现在也有在讨论迁移学习,迁移学习要做的是什么呢?

戴文渊向雷锋网表示,迁移学习最佳的应用场景在于医疗。“不是所有场景都有大数据的,比如说医疗。再比如,很多人觉得今日头条做的是个性化推荐,千人千面。其实他们不是在做个性化,而是做迁移学习。如果头条只有你的数据,绝对不可能给你服务得好,服务得好是因为有了你的数据,可以找到很多跟你相近的数据。今日头条最强的是在于他能够拿和你相近的哪些人的数据来帮助到你。所以它是一个迁移学习的问题,因为每个人提供的数据是有限的,不是一个大数据,真正的帮助是来自于周围,迁移学习就是说小数据也能做到高纬度。”

上述是人与人之间的迁移,另外一个例子是领域的迁移。领域的迁移是什么呢?举例来说,像金融。金融资产管理中,做一个业务资产也许几十亿上百亿,但是如果换一个视角看,上百亿的资产做小额信贷,数据量非常非常大。但是如果上百亿资产拿来做大额信贷,比如说房贷,每个人贷几百万并没有多大数据,那么问题来了——大额信贷没有大数据就很难用现在的深度学习来做。
“我们现在也在关注金融领域。迁移学习恰恰是可以帮助金融业企业利用各种各样的信贷数据,无论是大额信贷还是小额信贷,来提升模型的效果。比如在银行中,我们利用其小额消费金额的数据,帮助他做汽车贷款,也就是用别的领域的数据来提升效果,最后能够帮助他的营销提升。”
所以迁移学习要解决的是小数据实现超高维。另外一个数据是专家经验,如果说既没有数据,又没有其他领域的知识,我们还可以用专家经验来降低数据的使用量,提升小数据的模型维度。
我们今天会发现很多的话题在讨论人脸识别或者无人车,个性化推荐,有人讨论深度学习、强化学习,最关键的是所有事情都在解决一个问题就是维度。











