©来源
|
新智元
只用 4500 美元成本,就能成功复现 DeepSeek?就在刚刚,UC 伯克利团队只用简单的 RL 微调,就训出了 DeepScaleR-1.5B-Preview,15 亿参数模型直接吊打 o1-preview,震撼业内。
强化学习迎来重大突破!
近日,来自 UC 伯克利的研究团队基于 Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的 DeepScaleR-1.5B-Preview。
在 AIME2024 基准中,模型的 Pass@1 准确率达高达 43.1% ——不仅比基础模型提高了 14.3%,而且在只有 1.5B 参数的情况下超越了 OpenAI o1-preview!
目前,研究团队已开源数据集、代码和训练日志。
只用不到 5000 美元的预算,团队就复现了 DeepSeek 的成功。至此,开源又赢下一局。
网友们称赞:当机器学习和数学相遇,就是超强组合的诞生!


1.5B 模型,通过 RL 训练,就能超越 o1-preview,进行数学推理?
简而言之,团队这次的训练策略就是四个字——先短后长。
第一步,研究人员会训练模来型进行短思考。他们使用 DeepSeek 的 GRPO 方法,设定了 8k 的上下文长度来训练模型,以鼓励高效思考。
经过 1000 步训练后,模型的 token 使用量减少了 3 倍,并比基础模型提升了 5%。
接下来,模型被训练进行长思考。强化学习训练扩展到 16K 和 24K token,以解决更具挑战性、以前未解决的问题。
随着响应长度增加,平均奖励也随之提高,24K 的魔力,就让模型最终超越了 o1-preview!

DeepScaleR-1.5B-Preview
最近,Deepseek-R1 开源发布,对推理模型技术普及来说,是个重要突破。不过,它具体的训练方法、超参数还有底层系统,都还没公开。
在扩展强化学习的时候,最大的难题之一就是计算成本太高。
就拿 DeepSeek-R1 的实验来说,要想完全复现,上下文长度得达到 32K 以上,训练大概 8000 步,就算是只有 1.5B 参数的模型,起码都得花 70,000 GPU 小时。
如何利用强化学习,把小型模型变成超厉害的推理模型呢?
为了解决这个问题,研究人员用了知识蒸馏模型,还创新性地引入了强化学习迭代延长方法。
团队推出了 DeepScaleR-1.5B-Preview 模型,它经过 4 万个高质量数学问题的训练,训练一共用了 3800 个 A100 GPU 小时。
最终,成本只需约 4500 美元,省了 18.42 倍!同时模型的性能还在几个竞赛级数学基准中,超过了 o1-preview。
研究表明,用强化学习开发定制化的推理模型,既能大规模进行,还能控制成本,性价比超高!
▲ AIME 2024测试集Pass@1准确率随训练进度而变:训练至第1040步,上下文长度扩至16K token;到第1520步,上下文长度增至24K token

数据集构建
在训练数据集方面,研究人员收集了 1984 至 2023 年的美国国际数学邀请赛(AIME)、2023 年之前的美国数学竞赛(AMC),以及来自 Omni-MATH 和 Still 数据集的各国及国际数学竞赛题目。
数据处理流程包含三个核心步骤:
1. 答案提取:
对于 AMC 和 AIME 等数据集,使用 gemini-1.5-pro-002 模型从 AoPS 官方解答中提取答案。
2. 重复问题清理:
基于 RAG,并结合 sentence-transformers/all-MiniLM-L6-v2 的词向量嵌入来消除重复问题。
同时,对训练集和测试集进行重叠检测,以防止数据污染。
3. 不可评分题目过滤
:
数据集(如 Omni-MATH)中的部分问题,无法通过 sympy 数学符号计算库评估(得靠 LLM 判断)。
这不仅会降低训练速度,还会引入不稳定的奖励信号,因此需要增加额外的过滤步骤,来剔除无法自动评分的问题。
在经过去重和过滤之后,就得到了约 4 万个独特的问题-答案对作为训练数据集。
奖励函数设计
按 Deepseek-R1 的经验,用结果奖励模型(ORM)而不是过程奖励模型(PRM),来避免模型通过投机取巧得到奖励。
奖励函数返回值如下:
迭代增加上下文长度:从短到长的思维扩展
推理任务由于会生成比标准任务更长的输出,计算开销较大,这会同时降低轨迹采样(Trajectory Sampling)和策略梯度(Policy Gradient)更新的速度。
与此同时,上下文窗口大小翻倍,则会导致训练计算量至少增加 2 倍。
这种情况产生了一个根本性的权衡取舍:较长的上下文能为模型提供更充足的思维空间,但会显著降低训练速度;而较短的上下文虽然可以加快训练进度,但可能会限制模型解决那些需要长上下文的复杂问题的能力。
因此,在计算效率和准确性之间找到最佳平衡点至关重要。
基于 Deepseek 的广义近端策略优化(GRPO)算法的训练方案包含两个主要步骤:
-
首先,使用 8K token 的最大上下文长度进行强化学习训练,从而实现更有效的推理能力和训练效率。
-
随后,将上下文长度扩展到 16K 和 24K token,使模型能够解决更具挑战性的、此前未能攻克的问题。
用8K上下文构建高效思维链推理
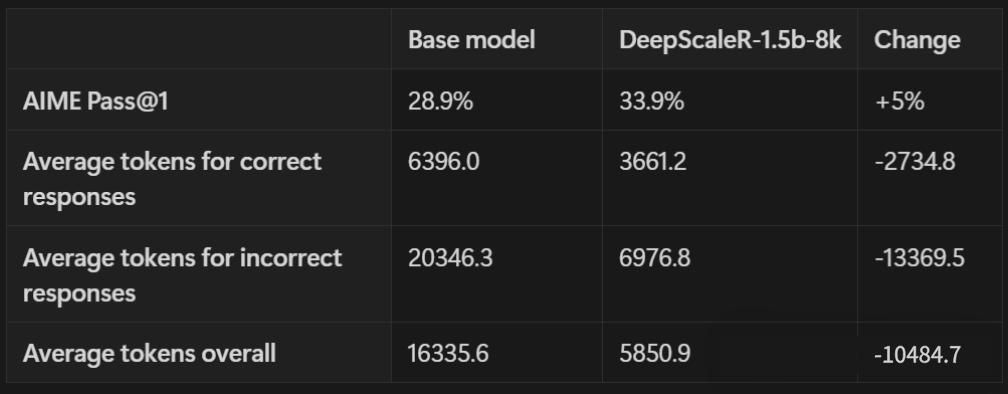
正式训练之前,先用 AIME2024 测试集对 Deepseek-R1-Distilled-Qwen-1.5B 模型进行评估,并分析它的推理轨迹数据。结果发现,错误答案里平均包含的 token 数量,是正确答案的三倍。这说明回答越长,越容易出错。
因此,直接采用长上下文窗口进行训练效率可能不高,因为大部分 token 都没有被有效利用。此外,冗长的回答还会表现出重复性模式,这表明它们并未对对思维链推理(CoT)产生实质性的贡献。
基于这些发现,团队决定先从 8K token 的上下文长度开始训练。在 AIME2024 测试里,获得了 22.9% 的初始准确率,只比原始模型低 6%。
事实证明这个策略很有效:训练的时候,平均训练奖励从 46% 提高到了 58%,平均响应长度从 5500 token 减少到了 3500 token。
把输出限制在 8K token 以内,模型能更高效地利用上下文空间。如下表所示,不管是生成正确答案还是错误答案,token 数量都大幅减少了。
在 AIME 准确率上,比原始基准模型还高了 5%,用的 token 数量却只有原来的 1/3 左右。
扩展至16K token上下文,关键转折点出现
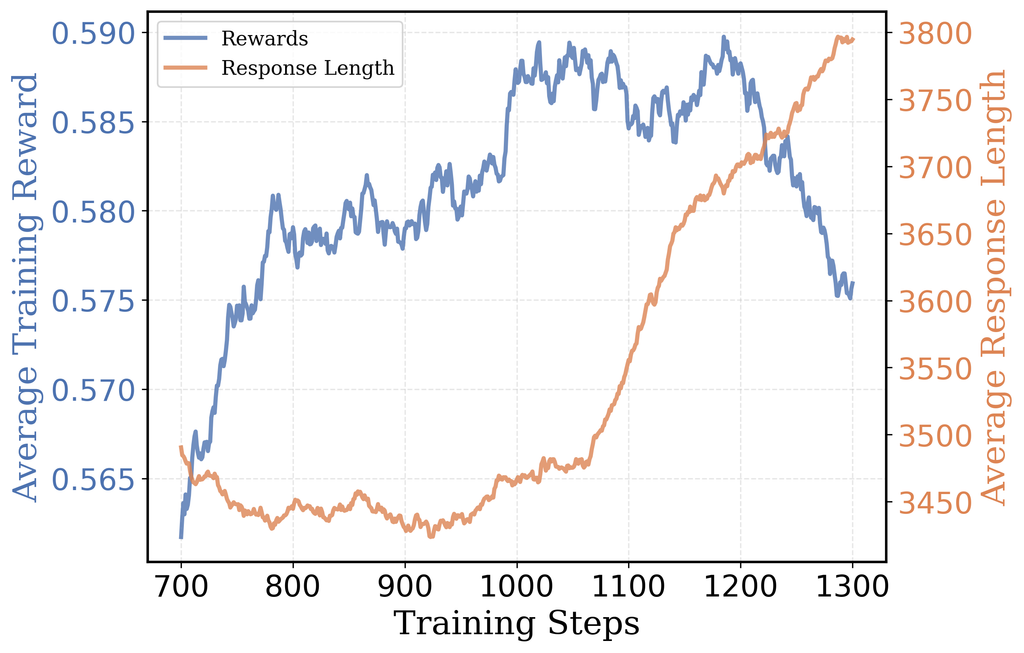
在大约 1000 步后,8K token 运行中发生了一个有趣的变化:响应长度再次开始增加。然而,这却没有增加收益——输出准确率达到了平台期,并最终开始下降。
与此同时,响应截断比例从 4.2% 上升到 6.5%,这表明更多的响应在上下文长度的限制下被截断。

这些结果表明,模型试图通过「延长思考时间」来提高训练奖励。然而,随着更长的输出,模型越来越频繁地触及到 8K token 上下文窗口的上限,从而限制了性能的进一步提升。
研究人员意识到这是一个自然的过渡点,于是决定「放开笼子,让鸟儿飞翔」。
他们选择了在第 1040 步的检查点——即响应长度开始上升的地方——重新启动训练,并使用了 16K 上下文窗口。
这种两阶段的做法比从一开始就用 16K token 训练效率高得多:8K 的预热阶段让平均响应长度保持在 3K token 而不是 9K,这使得此阶段的训练速度至少提高了2倍。
在扩展上了下文窗口后,研究人员观察到训练奖励、输出长度和 AIME 准确率都呈现稳定提升趋势。经过额外的 500 步训练,平均输出长度从 3.5K 增加至 5.5K token,AIME2024 的 Pass@1 准确率达到了 38%。
24K魔法,超越o1-preview
在 16K token 上下文环境下额外训练 500 步后,研究人员发现模型性能开始趋于平稳——平均训练奖励收敛在 62.5%,AIME 单次通过准确率徘徊在 38% 左右,输出长度再次呈现下降趋势。同时,最大输出截断比率逐渐升至 2%。
为了最终推动模型性能达到 o1 级别,研究人员决定决定推出「24K 魔法」——将上下文窗口扩大到 24K token。
首先,将 16K 训练时的检查点设定在第 480 步,并重新启动了一个 24K 上下文窗口的训练。
随着上下文窗口的扩展,模型终于突破了瓶颈。在大约 50 步后,模型的 AIME 准确率首次超过了 40%,并在第 200 步时达到了 43%。24K 的魔力发挥得淋漓尽致!
总体来看,训练历时约 1750 步。最初的 8K 阶段使用了 8 块 A100 GPU 进行训练,而 16K 和 24K 阶段则扩展到 32 块 A100 GPU 进行训练。
整个训练过程共耗时约 3800 个 A100 小时,相当于 32 块 A100 GPU 上运行了大约 5 天,计算成本约为 4500 美元。
研究人员用多个竞赛级别的数学评测基准来测试模型,像 AIME 2024、AMC 2023、MATH-500、Minerva Math 还有 OlympiadBench。
这里报告的是 Pass@1 准确率,简单说,就是模型第一次就答对的概率。每个问题的结果,都是 16 次测试取平均值得到的。
将 DeepScaleR 和 DeepSeek 模型,以及近期专注推理任务强化学习的成果对比。DeepScaleR 在所有评测里,都比基础模型强很多。
在 AIME 2024 测试中,成绩更是大幅提升了 14.4%,整体性能也提高了 8.1%。
DeepScaleR 比最新模型的表现还好,像从 7B 参数模型微调来的 rSTAR、Prime 和 SimpleRL。DeepScaleR 只用 1.5B 参数,就达到了 o1-preview 的性能水平——这是模型效率的重大突破!

AIME 准确率与模型规模对比,DeepScaleR 实现性能与规模最佳平衡(帕累托最优)。

很多人认为强化学习只对大型模型有用,其实强化学习在小型模型上也能发挥显著作用。
Deepseek-R1发现,直接在小型模型上用强化学习,效果不如知识蒸馏。在 Qwen-32B 模型上做对比实验,强化学习只能让 AIME 测试的准确率达到 47%,但只用知识蒸馏就能达到 72.6%。
不过,要是从更大的模型中,通过蒸馏得到高质量的 SFT 数据,再用强化学习,小模型的推理能力也能大幅提升。
研究证明了这一点:通过强化学习,小型模型在 AIME 测试中的准确率从 28.9% 提高到了 43.1%。
不管是只用监督微调,还是只用强化学习,都没办法让模型达到最佳效果。只有把高质量的监督微调蒸馏和强化学习结合起来,才能真正发挥 LLM 的推理潜力。
之前的研究发现,强化学习直接在 16K token 的上下文环境里训练,和 8K token 比起来,效果并没有明显提升。这很可能是因为计算资源不够,模型没办法充分利用扩大后的上下文。
最近的研究也指出,模型回复太长,里面就会有很多冗余的推理内容,这些内容容易导致错误结果。本文的实验证实了这些发现。
团队先在较短的 8K token 上下文里,优化模型的推理能力,这样一来,后续在 16K 和 24K token 的环境里训练时,就能取得更快、更明显的进步。
这种一步一步增加长度的方法,能让模型在扩展到更长的上下文之前,先建立起稳定的推理模式,从而提高强化学习扩展上下文长度的效率。









