作者丨洪雨欣
编辑丨陈彩娴
3 月 4 日,MIT 计算机系的教授 Peter Holderrieth 和 Ezra Erives 在 YouTube 上传了其最新课程系列“Generative AI with Stochastic Differential Equations”,从数学的角度探讨了当前 AIGC 领域应用最广泛的两种算法:去噪扩散模型和流匹配。
生成模型将噪声逐步转换为数据来生成对象,这一系列的演化过程可以通过模拟常微分方程(ODE)或随机微分方程(SDE)实现。此外,Holderrieth 和 Erives 还讨论了如何利用深度神经网络大规模构建、训练和模拟这些微分方程。
该课程系列一共有 6 个章节,AI 科技评论针对原视频作了不改原意的整理如下:
比如我们想要生成一张狗的图片,在这一过程中,存在着一系列“可能是狗”的图片。
在机器学习中,通常将这种“可能合适”图片的多样性视为一个概率分布,我们称之为数据分布,这个分布会赋予那些看起来更像狗的图片更高的可能性。所以,
图片的准确度会被其在数据分布下的可能性所取代。
因此,我们可以从数学上将生成任务表达为从数据分布中进行采样 。
在机器学习中,我们需要数据来训练模型,包括互联网上公开可用的图像、YouTube视频、或者是蛋白质数据库。在生成建模中,一个数据集由来自数据分布的有限数量的样本组成,我们将其表示为集合 1 到集合 n。

在许多情况下,我们会希望基于特定条件来生成一个对象。例如,我们希望生成“一只狗在覆盖着雪的山坡上奔跑,背景是山脉”的图像 。我们可以从条件数据分布中进行采样,其中 y 是一个条件变量 ,它可能是狗,可能是猫,也可能是风景。条件生成模型通常可以对任意变量进行条件设定,我们希望用不同的文本提示进行条件设定,因此,我们要寻求一个能够针对任意变量进行条件设定的单一模型。

所以,生成模型可以总结为:
从数据分布中生成样本
。
那么我们该如何获取样本呢?
假设我们可以从一个初始分布中获取样本,比如高斯分布,那么生成模型的目标就是将初始分布中采样得到的样本转换为数据分布的样本。在大多数应用中,我们都会将初始分布设定为一个简单的高斯分布 。
接下来,我们将描述
如何通过微分方程模拟来获得流模型和扩散模型
。
首先,我们可以通过常微分方程(ODE)构建一个流模型,我们的目标是将一个初始分布转换为数据分布
。
常微分方程的存在性与唯一性定理是微分方程理论中的一个基本结果,所以在机器学习的实际过程中,常微分方程的解不仅存在,而且是唯一的。

在算法1中,我们总结了从流模型中进行采样的过程:

向量场是带有参数的神经网络。目前,我们将向量场看作是一个通用的神经网络,即一个带有参数的连续函数。要注意的一点是,
神经网络是对向量场进行参数化,而非对流进行参数化。
接下来,我们可以通过随机微分方程(SDE),用相同的方式来构建一个生成模型。SDE是通过布朗运动构建而成的,布朗运动是一项源于对物理扩散过程研究的基本随机过程,相当于一种连续的随机游走。与处理常微分方程类似,我们使用随机初始分布来模拟随机微分方程。为了参数化这个SDE,我们可以简单地参数化其核心组成部分———向量场。

在算法2中,我们总结了从SDE中进行采样的过程:

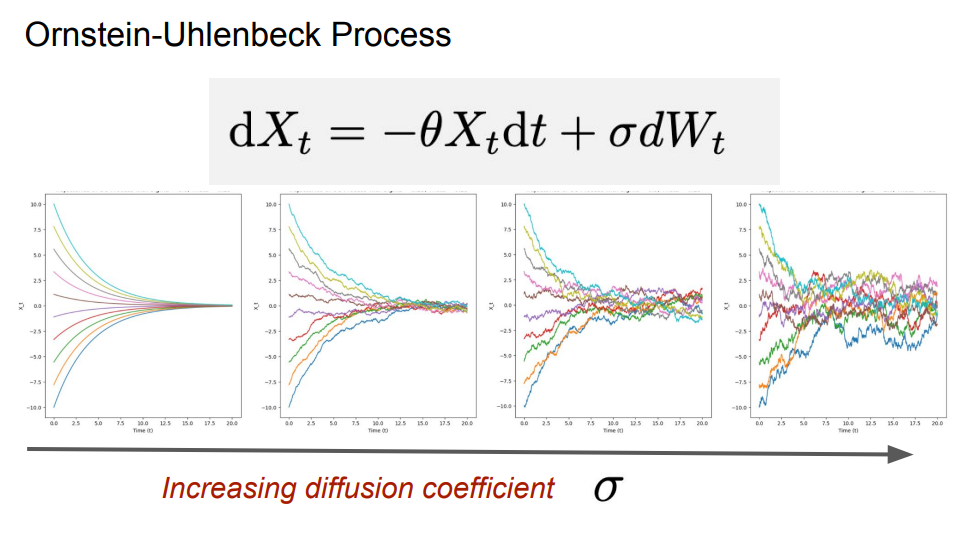
一个扩散模型由一个神经网络和固定的扩散系数组成,其中神经网络的参数可以用于参数化一个向量场 。当扩散系数为0时,扩散模型就成为了一个流模型 。
我们将通过最小化均方误差来训练目标。首先,我们需要设置一个训练目标。像神经网络一样,训练目标本身也应该是一个向量场。除此之外,它应该做到我们期望神经网络能做到的事情:将噪声转换为数据。

构建训练目标的第一步是指定一条概率路径。直观来讲,概率路径规定了从初始噪声分布到数据分布的逐步插值过程。

条件概率路径是一组关于数据点的随机分布,是针对单个数据点的性质或行为。换句话说,条件概率路径会逐渐将单个数据点转换为初始分布。而边缘概率路径则是跨越整个数据点分布的性质或行为,你可以将概率路径看成分布空间中的一条轨迹,每个条件概率路径都会诱导出一个边缘概率路径。
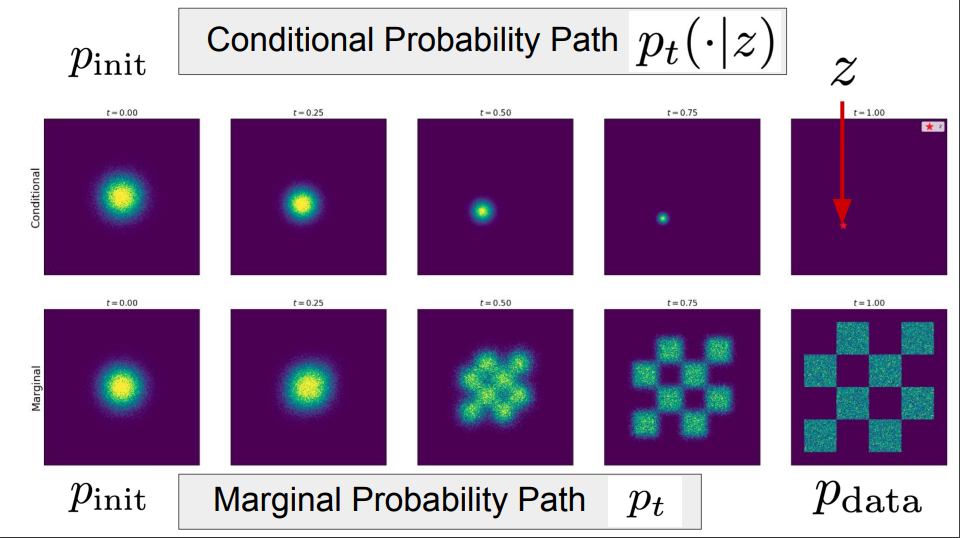
去噪扩散模型所使用的是高斯概率路径,条件概率路径会对高斯分布和单个数据点对应的随机分布进行插值 ,边缘概率路径会对整个数据点的分布进行插值。
现在我们通过使用定义的概率路径来构建流模型的训练目标。
每个数据点的训练目标表示一个条件向量场,定义为ODE产生条件概率路径。我们利用ODE模拟概率路径,蓝色背景为数据分布,红色背景为高斯分布。上排是条件路径,下排是边缘概率路径。可以看出,条件向量场沿着条件概率路径,边缘向量场沿着边缘概率路径。

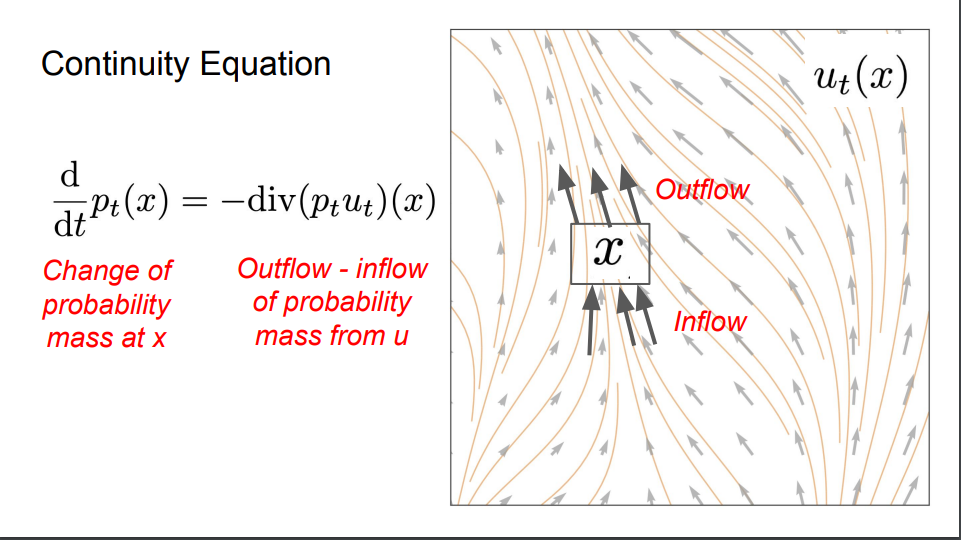
我们可以用连续方程来证明这一点。让我们考虑一个具有向量场训练目标的流模型,其中初始随机变量服从初始分布。连续性方程的公式为:在点
x
处概率质量的变化等于向量场u处概率质量的流出减去流入。
我们刚刚成功地为流模型构建了一个训练目标,我们可以通过Fokker - Planck方程将连续性方程从ODE拓展到SDE。
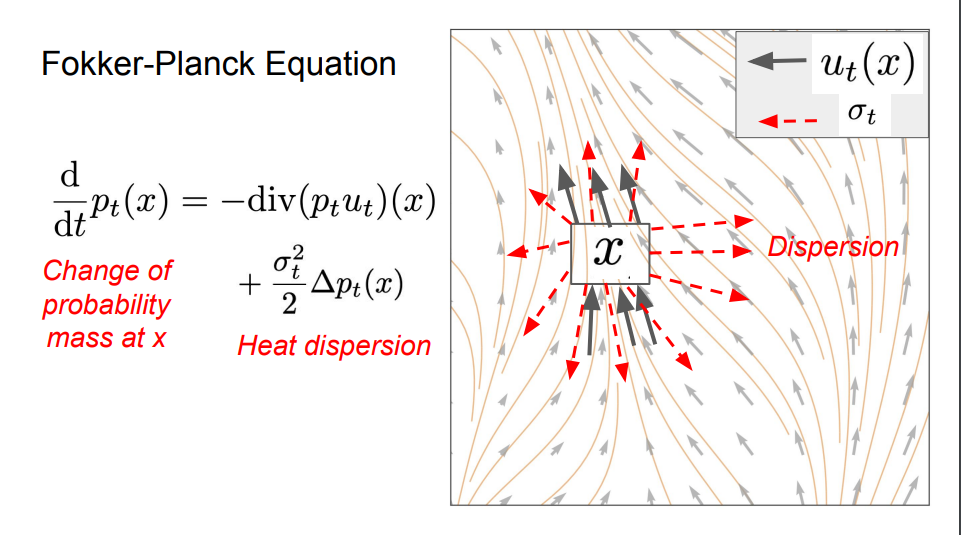
如示意图所示,我们使用ODE来模拟概率路径。蓝色背景为数据分布,红色背景为高斯分布。上排是条件路径,下排是边缘概率路径。可以看出,SDE将初始分布的样本传输到条件路径的样本和边缘路径的样本。

对于扩散系数,我们可以构造一个遵循相同概率路径的SDE。在这个场景下,用条件概率路径和条件向量场替换边缘概率和边缘向量场,相同的结论仍然成立,所以我们可以借助条件得分函数来表示边缘得分函数,这样该随机微分方程就如所期望的那样“将噪声转换为数据”。
像之前的流模型一样,我们希望神经网络等于边际向量场。换句话说,我们希望减小神经网络和边际向量场之间的均方误差。
首先,抽取一个随机时间。其次,我们从数据集中抽取一个随机点,从边际概率路径中进行采样,例如添加一些噪声,并计算神经网络。最后,计算神经网络的输出与边际向量场之间的均方误差。我们将利用条件速度场的可处理性定义条件流匹配损失。在这里,我们使用条件向量场而不是边际向量场,这是因为我们用条件向量场的解析公式最小化上述损失。
一旦神经网络被训练好了,我们就能够对流模型进行模拟以此来得到采样,这套流程就是流匹配。

为了更靠近边缘得分,我们可以使用一个
称之为得分网络的神经网络
。我们可以设计一个得分匹配损失和一个条件得分匹配损失。理想情况下我们希望最小化得分匹配损失,由于我们不知道边缘得分,我们可以使用条件得分匹配损失来实现这一点。

训练完成后,我们可以选择任意扩散系数,然后模拟该随机微分方程以生成样本。
理论上,在完美训练的情况下,每个扩散系数都应该给出服从真实数据分布的样本。但在实际中,我们会遇到两类错误:
第一,由于对SDE的模拟不完善而产生的数值误差;第二,训练误差,即训练模型并不完全等同于目标模型。因此,存在一个最优但未知的噪声水平系数——这可以通过实际测试不同的值来凭经验确定。
我们可以通过高斯概率路径来训练得分匹配模型,条件得分匹配损失也被称为去噪得分匹配,它是用于学习扩散模型的最早程序之一。我们可以看到,当beta接近0时,条件得分损失在数值上是不稳定的,也就是说,只有添加足够多的噪声,去噪得分匹配才有效。

虽然流匹配仅允许通过ODE进行确定性的模拟过程,但去噪扩散模型允许进行确定性(概率流常微分方程)或者随机性(随机微分方程采样)的模拟。然而,不同于流匹配或随机插值,后者能够通过任意的概率路径将初始分布转换为数据分布。
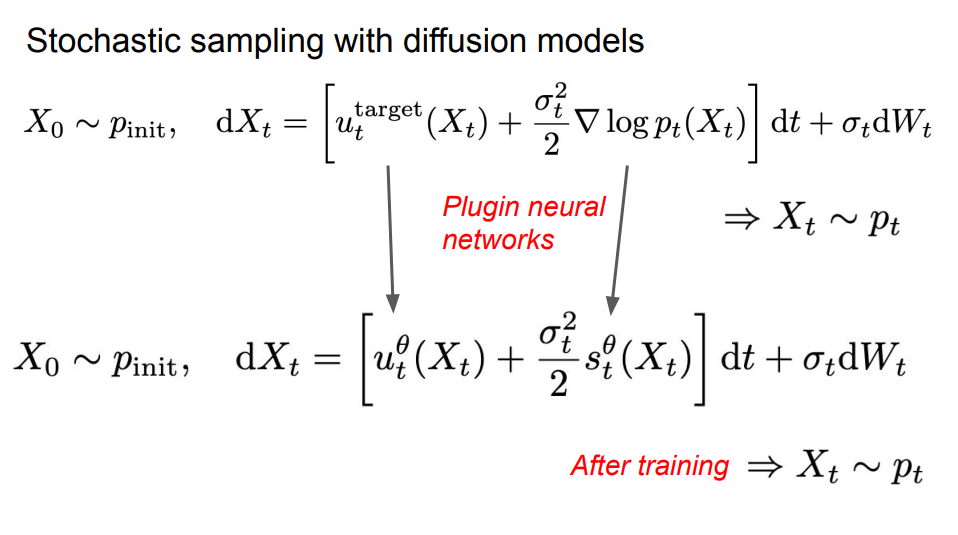
去噪扩散模型仅适用于高斯初始分布和高斯概率路径。对于高斯概率路径来说,我们无需分别训练向量场和得分网络,它们可以在训练后相互转换。

文献中流行的扩散模型的替代公式有:
-
离散时间:通常使用通过离散时间得出SDE的近似值。
-
倒置时间约定:一种流行的做法是采用倒置时间约定,其中时间对应数据分布。
-
正向过程:正向过程(或加噪过程)是构建高斯概率路径的方法。
-
通过时间反转构建训练目标:也可以通过对SDE进行时间反转来构建训练目标。
假如要构建Stable Diffusion 3和Meta Movie Gen Video这样的图像生成模型,我们首先需要构建条件生成引导机制。我们还将了解无分类器引导,这是一种用于提高条件生成质量的流行技术。
我们选择使用“引导”一词来代替“条件”,以指代基于
y
进行条件化的操作。引导式生成建模的目标是能够针对任意
y
从数据分布中进行采样。
在流匹配和得分匹配的语言体系中,我们定义一个引导扩散模型是由一个引导向量场和一个时间相关的扩散系数共同组成的。如果我们设想固定标签
y
的取值,那么我们就回到了无引导的生成问题。我们可以相应地使用条件流匹配目标来构建一个生成模型。
请注意,因为
y
不影响条件概率路径或条件向量场,所以在所有
y
以及所有时间里面都可以得到一个引导条件流匹配目标。引导目标与无引导目标的主要区别之一在于,引导目标是从数据分布中采样z和y,而不仅仅是采样
z
。原因在于,我们的数据分布现在原则上是一个关于图像和文本提示的联合分布,这样会让生成过程更准确。
虽然上述条件训练程序在理论上是有效的,但这种程序得到的图像样本与期望标签的拟合度不够好。由于人为强化引导变量
y
的影响可以提高感知质量,这一见解被提炼成一种无分类器引导的技术,该技术在最先进的扩散模型领域得到了广泛应用。
为简单起见,我们在此仅关注高斯概率路径的情况。在一个模型中同时训练条件模型和无条件模型,这被称为无分类器引导。算法8展示了如何将无分类器引导构造扩展到扩散模型的环境中:
在扩散模型的开发中,我们需要介绍一种特定类型的卷积神经网络U-Net。它最初是为图像分割而设计的,其关键特征在于输入和输出都具有图像的形状,这使得它非常适合将向量场参数化。
U-Net由一系列编码器
Ei
、相应的一系列解码器
Di
以及位于它们之间的一个潜在处理块组成,我们将这个潜在处理块称为中编码器。随着输入通过编码器,其表示形式中的通道数量增加,而图像的高度和宽度减小。编码器和解码器通常都由一系列卷积层(其间包含激活函数、池化操作等)组成。输入在到达第一个编码器块之前,通常会先被送入一个初始预编码块以增加通道数量。
U-Net的一种替代方案是扩散Transformer(DiTs),它摒弃了卷积操作,纯粹使用注意力机制。扩散Transformer基于视觉Transformer(ViTs),其主要思想本质上是将图像分割成多个图像块,对每个图像块进行嵌入,然后在图像块之间进行注意力计算。例如,Stable Diffusion 3就采用条件流匹配进行训练,它将速度场参数化为一种改进的DiT。
大规模应用的一个常见问题是
数据维度极高,导致消耗过多内存
。例如,我们想要生成分辨率为1000×10000像素的高分辨率图像,这会产生100万个维度。
为了减少内存使用量,一种常见的设计模式是
在潜在空间中进行操作
,该潜在空间可被视为分辨率较低的数据的压缩版本。
具体而言,通常的方法是
将流模型或扩散模型与自编码器相结合
。首先通过自编码器将训练数据集编码到潜在空间中,然后在潜在空间中训练流模型或扩散模型。
采样时,首先使用训练好的流模型或扩散模型在潜在空间中进行采样,然后通过解码器对输出进行解码。
直观地说,一个训练良好的自编码器能够过滤掉语义上无意义的细节,从而使生成模型能够聚焦于重要的、感知上相关的特征。
到目前为止,几乎所有用于图像和视频生成最先进的方法都涉及在自编码器的潜在空间中训练流模型或扩散模型——这就是所谓的潜在扩散模型。
然而,需要注意的是,在训练扩散模型之前也需要训练自编码器,模型的性能也取决于自编码器将图像压缩到潜在空间以及恢复美观图像的能力。
Stable Diffusion 3 使用了我们在这项研究中的条件流匹配目标。正如他们的论文所概述的,他们对各种流和扩散替代方案进行了广泛的测试,并发现流匹配表现最佳。在训练方面,它使用了无分类器指导训练。
为了增强文本条件作用,Stable Diffusion 3 利用了三种不同类型的文本嵌入,其中包括 CLIP 嵌入和谷歌 T5-XXL 编码器预训练实例产生的序列输出。
CLIP 嵌入提供了输入文本的粗略、总体嵌入,而 T5 嵌入提供了更细粒度的上下文层次,使模型能够关注条件文本的特定元素。为了适应这些序列上下文嵌入,扩散 Transformer不仅要关注图像,还要关注文本嵌入,从而将条件能力从最初为 DiT 提出的方案扩展到序列上下文嵌入。
这种修改后的 DiT 被称为多模态 DiT(MM-DiT)。他们最大的模型拥有 80 亿个参数。










