本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博 @唐僧_huangliang,以便更好地与读者互动。
适逢一年一度的
全球超算(
HPC
)大会
期间,看到有朋友撰写了
IO500
存储排行榜相关的文章,我也下载了数据表简单学习下,本文就给大家分享下收获体会。
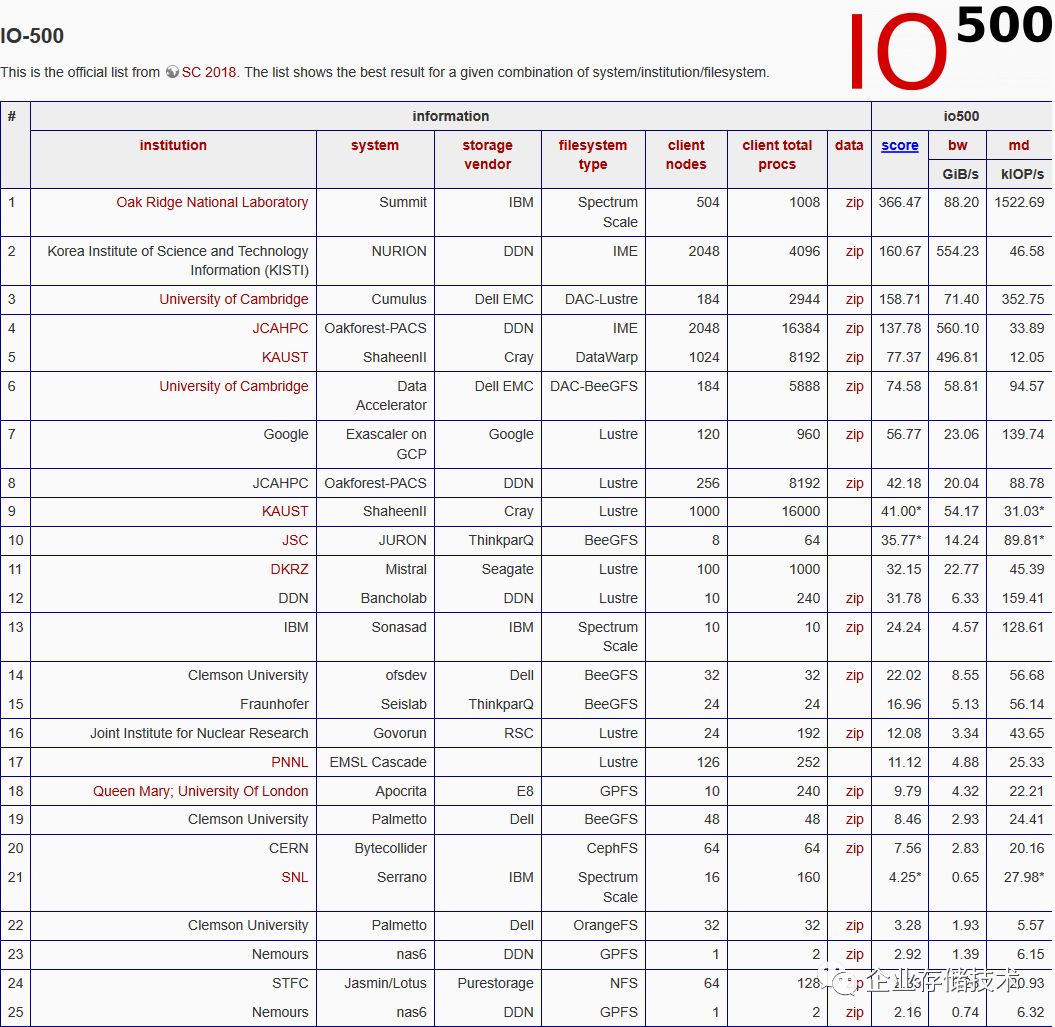
下面我是扩大到
60
套
HPC
存储来统计分析
首先,
IO500
测试的得分应该是由带宽(
GiB/s
)和每秒操作数(
kIOP/s
)计算而来。当前我下载到的完整数据表格(链接如下)中并没有
500
套系统的成绩,而是
60
多套,估计是在参加者还不够多的情况下
先借用
TOP500
的命名风格
。
https://www.vi4io.org/lib/exe/fetch.php?tok=ee54aa&media=https%3A%2F%2Fwww.vi4io.org%2Fassets%2Fio500%2F2018-11%2Fdata.csv
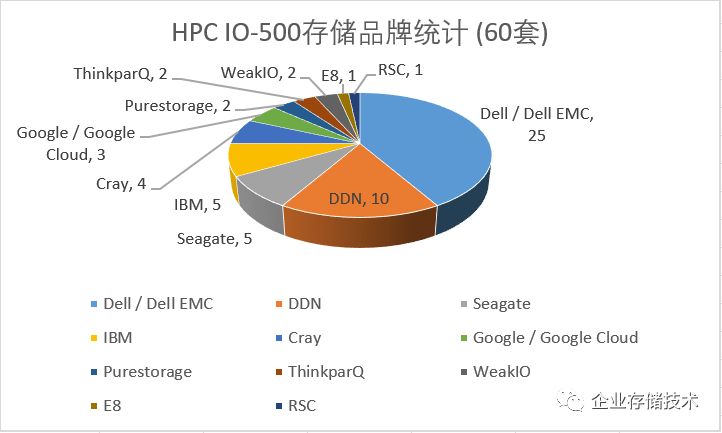
在这份由
TOP25
套扩大到
TOP60
的参测系统名单中,
Dell
(
Dell EMC
)占据
25
套,就像友人所说的那样,至少是代表积极参与;套数排第二的
DDN
为
10
套;剩下的
IBM
和希捷各
5
套、
Cray 4
套、
Google 3
套
…
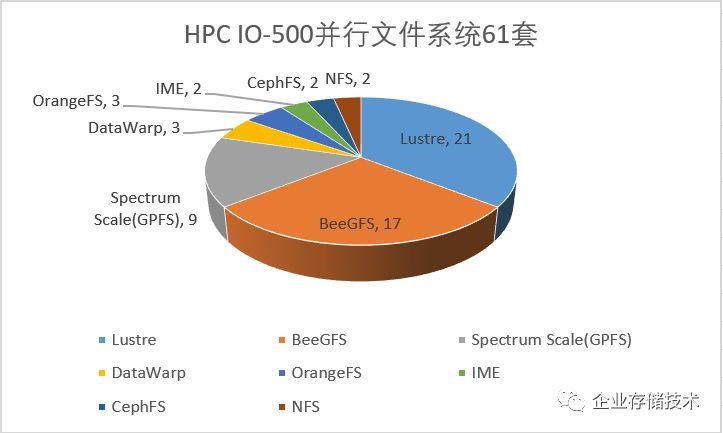
上面我总结这个图表应该也有一定参考价值。按照文件系统来分,
61
套参测存储中
Lustre
以
21
套
排名第一,紧接着就是
BeeGFS
的
17
套
,然后
IBMSpectrum Scale(GPFS)
有
9
套,
Cray
的
DataWarp
、以及
OrangeFS
各有
3
套,
DDN IME
、
CephFS
和
NFS
都是
2
套。
以
Dell
为例,
25
套参测系统中有
6
套
Lustre
,
16
套
BeeGFS
和
3
套
OrangeFS
。后面
2
种新兴的开源
HPC
文件系统
,在这个榜单种几乎都是
Dell
贡献的?而据我了解
DellEMC
在国内应该是主推
Lustre
和
Isilon
,也许和客户群偏保守一些有关吧。
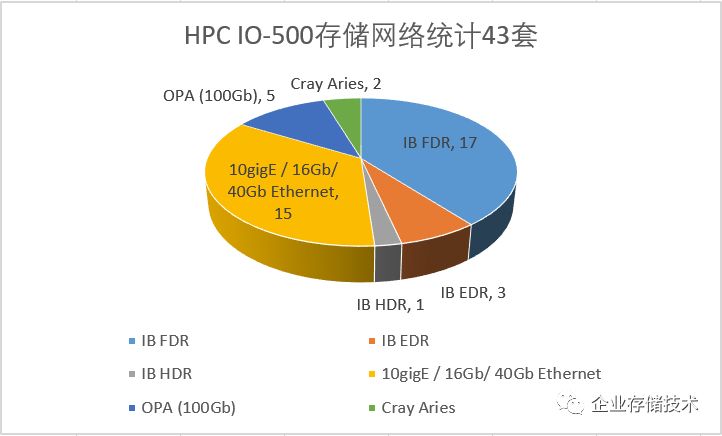
至于元数据以及存储节点之间的互连,我一共看到
43
套系统的信息。
InfiniBand
接近占据半壁江山
,其中
56Gbps
的
FDR
最多达到
17
套,还有
3
套
EDR 100Gbps
和
1
套
HDR 200Gbps
;各种
以太网一共
15
套
,这里面我没按速率来分是因为有些没标明,除了
1
套
40Gb
和
2
套
16Gb
之外我看还是
10GbE
比较多
。
余下的就是
5
套
Intel OmniPath
(
OPA
)
和
2
套
Cray Aries
。我记得除了从
QLogic
收购
IB
业务之外,
Cray
也把一部分
HPC
互连技术卖给了
Intel
。
下面看看性能,以及决定性能的因素。
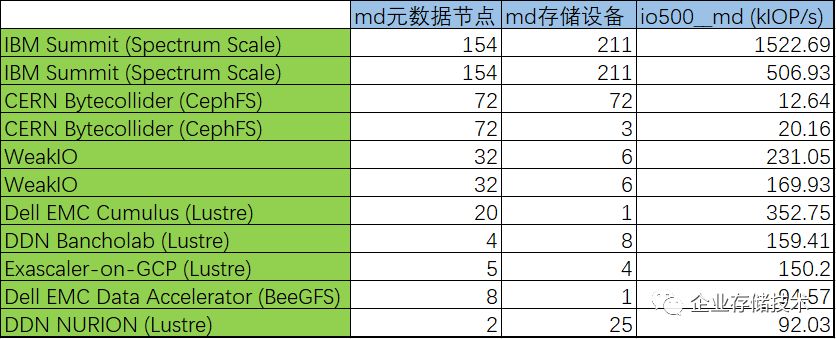
高性能计算存储
IOP/s
排名分析
按照经验,
文件系统的
OPS
(每秒操作数)主要取决于元数据性能,因此往往
和
md
元数据节点数量和存储设备性能有直接关系
。在这里我特别先关注了元数据节点数量,所以除了
kIOP/s
排名前
8
位的,另外把
2
套
CephFS
也列进来了。
IO500
我觉得在统计存储系统特性时还欠缺一些分类。比如
IBM ESS
是
对称分布式文件系统
的
GPFS
吧?
154
个存储服务器上应该都有元数据;至于
CephFS
,
MDS
元数据节点达到
72
个应该说不少了。
至于“
md
存储设备”,
有可能是每节点(节点对)上的部分或者全部驱动器;也可能是后端存储阵列映射给
MDS
元数据服务器的
LUN
(
MDT
)
,因此直接从数量上来评价性能似乎不太合适。
补充一点,目前用
SSD
放
HPC
存储元数据已经相当普遍。

注:
ONRL
——美国能源部橡树岭国家实验室
根据
IBM Summit
的资料,其
77
节点应该是指
Power9 HA
服务器对,一共就是
154
台服务器;每对服务器共享连接
4
个
4U 106
盘
JBOD
,其中包括
104
个
NLSAS HDD
和
2
个
NVMe SSD
(
4
个
JBOD
中一共有
2
个
NVMe
用于系统盘?)。
我猜测
NVMe SSD
应该被用于元数据加速?但从
IBM
提交给
IO500
的信息来看,应该是每块数据盘上都有
GPFS
文件系统的元数据。
由于
IBM
的
IO500
测试高达
152
万
IOPS
,我看有同行朋友认为是“在文件系统客户端采用了某种激进的元数据缓存机制”,事实上好像并非如此。
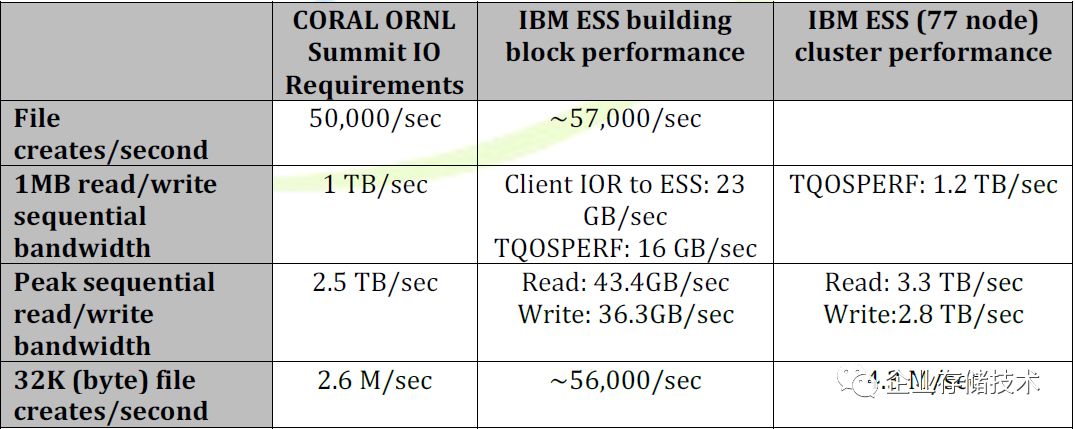
根据官方文档中给出的性能指标,
IBM
给
ORNL
的
Summit
聚合读
/
写带宽可达上
TB/s
水平。在
HPC
存储方面我只是个初级爱好者,一直很佩服
Spectrum Scale
中国研发经理,有
GPFS
老父亲之称的冯硕老师。
但同时我还看到,在
IO500
测试的带宽结果中,
Summit
的表现似乎没有那么好?
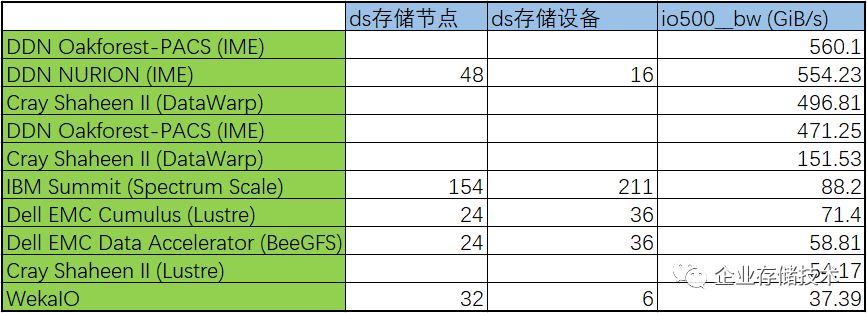
高性能计算存储带宽(
GiB/s
)排名分析
上表我按顺序列出了带宽测试排名前
10
的系统,
DDN IME
和
Cray DataWarp
明显表现较好,我在网上看
IME
(
Infinite Memory Engine
)应该是用
NVMe
全闪存服务器节点作为
HPC
存储前端的大容量缓存层。
在这里我觉得
IBM GPFS
的发挥似乎不太正常?因为除了一套测得
88.2GiB/s
,还有一套
Summit
只测到
9.84GiB/s
,对比前面
IBM
自己测出的性能就比较奇怪了。
因此,我初步认为
IO500
的带宽测试可能不够全面反映实际应用水平
,或者不排除有的厂商做了优化?不知大家怎么看。
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://chuansong.me/account/huangliang_storage




