
英文:Luke Wilson,编译:伯乐在线/可乐
编程语言是怎样工作的
理解编译器内部原理,可以让你更高效利用它。按照编译的工作顺序,逐步深入编程语言和编译器是怎样工作的。本文有大量的链接、样例代码和图表帮助你理解编译器。
作者注:
这是我在 Medium 上的第二篇文章的再版,
上一版
有超过 21000 的阅读量。很高兴我能够帮助到各位的学习,因此我根据上一版的评论,完完全全重写了。
我选择 Rust 作为这篇文章的主要语言。它是一种详尽的、高效的、现代的而且看起来特意使得设计编译器变得简单。我很喜欢使用它。
https://www.rust-lang.org/
写这篇文章的目的主要是吸引读者的注意力,而不是提供 20 多页的令人头皮发麻的阅读材料。对于那些你感兴趣的更深层次的话题,文章中有许多链接会引导你找到相关的资料。大多数链接到维基百科 。
感谢你的关注,我希望你能够喜欢这些我花费了超过 20 个小时的写出的文章。欢迎在文章底部评论处留下任何问题或者建议。
简单介绍
编译器是什么?
你口中所说的编程语言本质上只是一个软件,这个软件叫做编译器,编译器读入一个文本文件,经过大量的处理,最终产生一个二进制文件。 编译器的语言部分就是它处理的文本样式。因为电脑只能读取 1 和 0 ,而人们编写 Rust 程序要比直接编写二进制程序简单地多,因此编译器就被用来把人类可读的文本转换成计算机可识别的机器码。
编译器可以是任何可以把文本文件转换成其他文件的程序。例如,下面有一个用 Rust 语言写的编译器把 0 转换成 1,把 1 转换成 0 :
// An example compiler that turns 0s into 1s, and 1s into 0s.
fn main
()
{
let
input
=
"1 0 1 A 1 0 1 3"
;
// iterate over every character `c` in input
let
output
:
String
=
input
.
chars
().
map
(
|
c
|
if
c
==
'1'
{
'0'
}
else
if
c
==
'0'
{
'1'
}
else
{
c
}
// if not 0 or 1, leave it alone
).
collect
();
println
!
(
"{}"
,
output
);
// 0 1 0 A 0 1 0 3
}
编译器是做什么的?
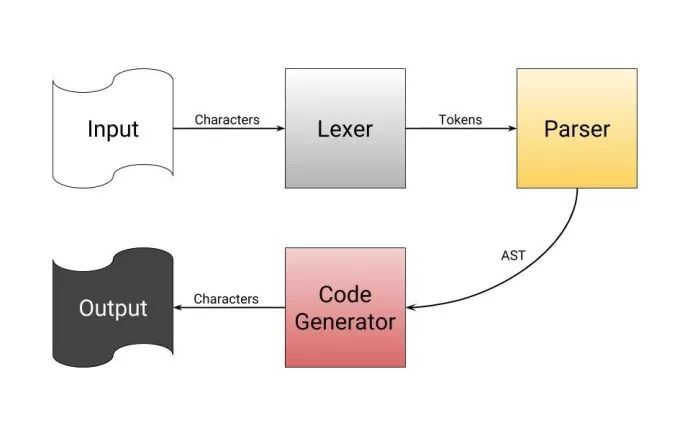
简言之,编译器获取源代码,产生一个二进制文件。因为从复杂的、人类可读的代码直接转化成0/1二进制会很复杂,所以编译器在产生可运行程序之前有多个步骤:
-
从你给定的源代码中读取单个词。
-
把这些词按照单词、数字、符号、运算符进行分类。
-
通过模式匹配从分好类的单词中找出运算符,明确这些运算符想进行的运算,然后产生一个运算符的树(表达式树)。
-
最后一步遍历表达式树中的所有运算符,产生相应的二进制数据。
尽管我说编译器直接从表达式树转换到二进制,但实际上它会产生汇编代码,之后汇编代码会被汇编/编译到二进制数据。汇编程序就好比是一种高级的、人类可读的二进制。
解释器是什么?
解释器
非常像编译器,它也是读入编程语言的代码,然后处理这些代码。尽管如此,解释器会跳过了代码生成,然后
即时编译
并执行 AST。 解释器最大的优点就在于在你 debug 期间运行程序所消耗的时间。编译器编译一个程序可能在一秒到几分钟不等,然而解释器可以立即开始执行程序,而不必编译。解释器最大的缺点在于它必须安装在用户电脑上,程序才可以执行。
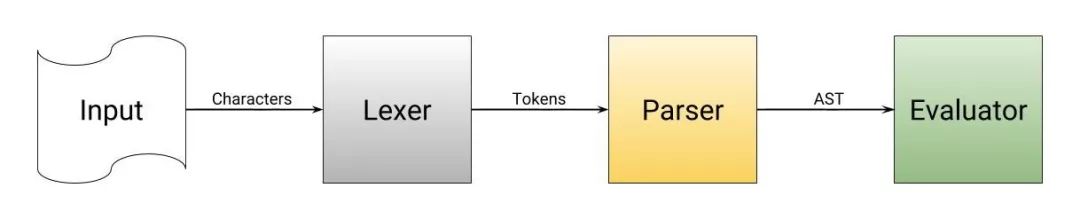
虽然这篇文章主要是关于编译器的,但是对于编译器和解释器之间的区别和编译器相关的内容一定要弄清楚。
1. 词法分析
第一步是把输入一个词一个词的拆分开。这一步被叫做
词法分析
,或者说是分词。这一步的关键就在于 我们把字符组合成我们需要的单词、标识符、符号等等。 词法分析大多都不需要处理逻辑运算像是算出 2+2 – 其实这个表达式只有三种
标记
:一个数字:2,一个加号,另外一个数字:2。
让我们假设你正在解析一个像是 12+3 这样的字符串:它会读入字符 1,2,+,和 3。我们已经把这些字符拆分开了,但是现在我们必须把他们组合起来;这是分词器的主要任务之一。举个例子,我们得到了两个单独的字符 1 和 2,但是我们需要把它们放到一起,然后把它们解析成为一个整数。至于 +也需要被识别为加号,而不是它的字符值 – 字符值是43 。
如果你可以阅读过上面的代码,并且弄懂了这样做的含义,接下来的 Rust 分词器会组合数字为32位整数,加号就最后了标记值 Plus(加).
https://play.rust-lang.org/?gist=070c3b6b985098a306c62881d7f2f82c&version=stable&mode=debug&edition=2015
你可以点击 Rust playgroud 左上角的 “Run” 按钮来编译和执行你浏览器中的代码。
在一种编程语言的编译器中,词法解析器可能需要许多不同类型的标记。例如:符号,数字,标识符,字符串,操作符等。想知道要从源文件中提取怎样的标记完全取决于编程语言本身。
int
main
()
{
int
a
;
int
b
;
a
=
b
=
4
;
return
a
-
b
;
}
Scanner
production
:
[
Keyword
(
Int
),
Id
(
"main"
),
Symbol
(
LParen
),
Symbol
(
RParen
),
Symbol
(
LBrace
),
Keyword
(
Int
),
Id
(
"a"
),
Symbol
(
Semicolon
),
Keyword
(
Int
),
Id
(
"b"
),
Symbol
(
Semicolon
),
Id
(
"a"
),
Operator
(
Assignment
),
Id
(
"b"
),
Operator
(
Assignment
),
Integer
(
4
),
Symbol
(
Semicolon
),
Keyword
(
Return
),
Id
(
"a"
),
Operator
(
Minus
),
Id
(
"b"
),
Symbol
(
Semicolon
),
Symbol
(
RBrace
)]
C 语言的样例代码已经进行过词法分析,并且输出了它的标记。
2. 解析
解析器确实是语法解析的核心。解析器提取由词法分析器产生的标记,并尝试判断它们是否符合特定的模式,然后把这些模式与函数调用,变量调用,数学运算之类的表达式关联起来。 解析器逐词地定义编程语言的语法。
int a = 3 和 a: int = 3 的区别在于解析器的处理上面。解析器决定了语法的外在形式是怎样的。它确保括号和花括号的左右括号是数量平衡的,每个语句结尾都有一个分号,每个函数都有一个名称。当标记不符合预期的模式时,解析器就会知道标记的顺序不正确。
你可以写好几种不同类型的解析器。最常见的解析器之一是从上到下的,递归降解的解析器。递归降解的解析器是用起来最简单也是最容易理解的解析器。我写的所有解析器样例都是基于递归降解的。
解析器解析的语法可以使用一种 语法 表示出来。像 EBNF 这样的语法就可以描述一个解析器用于解析简单的数学运算,像是这样 12+3 :
expr
=
additive
_
expr
;
additive_expr
=
term
,
(
'+'
|
'-'
),
term
;
term
=
number
;
简单加法和减法表达式的 EBNF 语法。
请记住语法文件并不是解析器,但是它确实是解析器的一种表达形式。你可以围绕上面的语法创建一个解析器。语法文件可以被人使用并且比起直接阅读和理解解析器的代码要简单许多。
那种语法的解析器应该是 expr 解析器,因为它直接与所有内容都相关的顶层。唯一有效的输入必须是任意数字,加号或减号,任意数字。expr 需要一个 additive_expr,这主要出现在加法和减法表达式中。additive_expr 首先需要一个 term (一个数字),然后是加号或者减号,最后是另一个 term 。
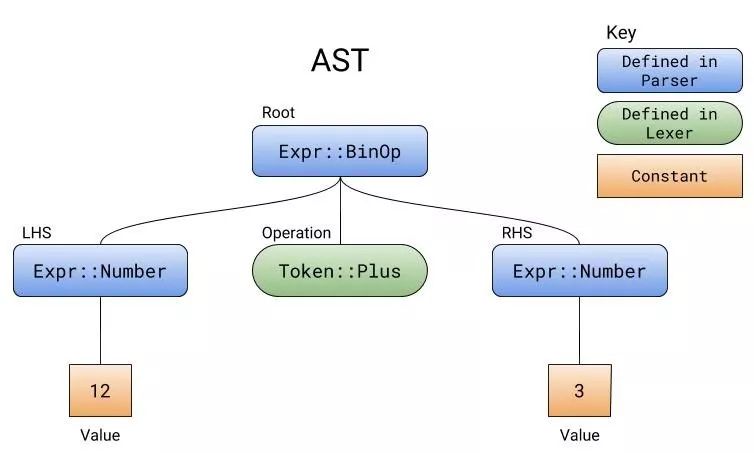 解析 12+3 产生的样例 AST
解析 12+3 产生的样例 AST
解析器在解析时产生的树状结构被称为
抽象的语法树
,或者称之为 AST。 ast 中包含了所有要进行操作。解析器不会计算这些操作,它只是以正确的顺序来收集其中的标记。
我之前补充了我们的词法分析器代码,以便它与我们的语法想匹配,并且可以产生像图表一样的 AST。我用 // BEGIN PARSER // 和 // END PARSER // 的注释标记出了新的解析器代码的开头和结尾。






