
#长按上图识别二维码,参与OSC源创会年终盛典#
摘要: 本文整理自 OSC 成都源创会上祝海强老师的演讲,主要对大规模MySQL自动化运维平台进行介绍,针对技术层面分享平台的架构实现,包括它的资源管理、监控、故障自愈等核心模块是怎么布局实现的?规模到底有多大?又是如何稳定提供服务的?
嘉宾介绍:祝海强,腾讯高级工程师。8年数据库经历,曾就职于第九城市、返利网任高级DBA。目前负责腾讯云CDB for MySQL运维团队,对MySQL、MSSQL等数据库运维、调优诊断具有丰富的经验。
1.CDB日常维护工作
CBD即云数据库(Cloud Database),主要具有以下特点:
(1)云存储服务,是腾讯云平台提供的分布式数据存储服务
(2)完全兼容MySQL协议
(3)提供了高性能、高可靠、易用、便捷的MySQL集群服务
(4)整合了备份、扩容、迁移等工具,同时提供CDB管理台,开发者可以方便的进行登录、数据库和表的增删查改等工作
(5)现网CDB的运营数据接近3PB,接入业务包括微信红包,腾讯彩票,腾讯话费充值,饿了么,微信电影票等等
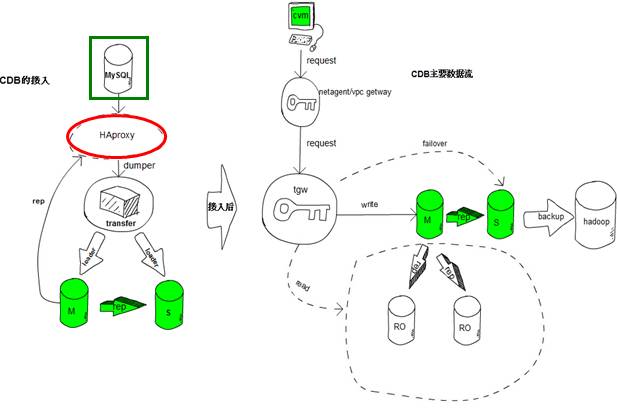
CDB基本架构:
用户在计算机房或是阿里云上,自建的MySQL通过 HAproxy或者transfer去打通,就可以导MySQL导数据到CDB里边。下图为CBD的一个基本架构:
自动运维平台日常维护CDB的工作:
设备初始化及大量的实例申请
主机硬件故障、过保设备下线、机房裁撤
大量业务扩容支持/低负载成本优化
实例主从切换、备份、高负载等case处理
2.扩容/缩容
由于腾讯云正在飞速发展,目前大概已有六万多的实例,靠人工去进行升级实例、迁移、切换是无法支持的,所以引入了自动化的运维平台。微信红包就是一个典型的例子,春节的量非常大,一扩容可能就是上千台机器,而过完年以后就需要缩容。这些工作量都是非常大的。
1.资源管理模块
(1)设备初始化持续部署
不同的机型做了哪些事情或者进行了哪些参数的调优。
包括 MySQL server 在机器上的部署,还有TGW(异常容灾切换)、cdb_report(性能采集agent)、AJS(任务运行agent)这些主键的安装,用来维护后端发起的迁移任务。这些主键将会在后面讲到。
(2)资源监控
一是在不停的扩容和缩容的过程中需要进行监控。例如运维人员不在的情况下线上的实例少于设置的阀值,用户可能在购买实例的时候遇到断货的情况,资源监控的作用就是当实例数量少于阀值的时候自动从buffer池里拿出来上架。
还有就是统计每个月新增机器的数量。比如每个月消化了一百台机器,那么下个月报废设备的时候,在不考虑特殊服务的情况下就是增加一百台机器的量,资源监控做出每个月甚至每天消耗机器统计的报表。
(3)资源循环
同地区集群之间资源共享
已迁移和已下线实例自动回收机制
例如用户购买实例,如果业务下线了需要退掉实例,资源管理模块会对用户下线的实例进行自动回收。
2.运维操作模块
人工运维的时候,MySQL需要做哪些操作?
(1)申请实例
用户研发的时候需要实例,一般是找两台机器,安装MySQL,搭建一个主从,提交给研发用,这个过程需要手工去申请;
(2)主从切换
最早的版本没有HA切换,主从挂了以后,告警出来需要手工去切;
(3)迁移实例
用户申请实例发现内存不足,需要进行的升级;
(4)数据回档
假如用户改错数据了,需要通过手工去找回来;
(5)下线实例
实例不用了的时候,需要人工去下线。
实例操作模块就是负责这些手工操作的模块。运维工具十分庞大,但其实都是从日常的手工操作发现需要做哪些事情,哪些事情人工做的比较多,必须减少运维的哪些手工操作等等演化过来的。
比如做MySQL的运维人员都了解的这个例子:用户主机挂了,然后切到从机上服务,就会发起迁移,通过备份导到新的master上面,再新构建一个主从,通过HA方案切到新的主从识别上去。
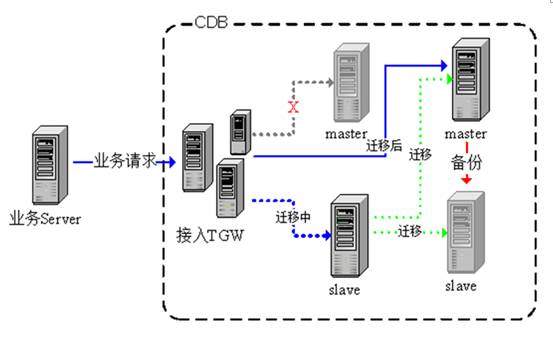
3.平台监控模块
平台的监控模块的作用在于发现实例是否有正常,或者有什么异常:
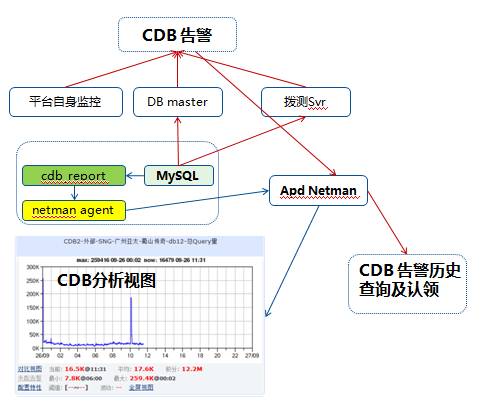
拨测Svr的作用就是模拟用户连接和读写CDB实例,如失败,则告警,并将失败错误码和错误内容返回。
如果拨测连不进 MySQL server,拨测就会跟另一个模块DB master打交道 ,DB master通过一个长链接一直连到MySQL ,DB master就会进去看连接是不是满了或者有没有死锁,看完以后就会提交告警,并且下发到Apd Netman。
Apd Netman 会做一些监控、告警的收敛,如果用过CBD还可以通过采集 MySQL 性能数据的工具cdb_report 看到监控曲线,所以这个系统是旁路监控系统的一个重要模块。
cdb_report相关监控项:

以上几个模块就是整个 CBD 系统的看门狗,检测这个看门狗是不是能正常工作就需要用到另一个旁路系统——平台自身的监控系统来监控这些主键是否正常运行,查看所有模块的健康状态。
4.平台自愈模块
监控出现问题以后就交给人去处理,但是线上那么多实例,单靠人工很难维持,所以平台加了一个自愈的模块,把经常出现的异常加入到故障的自愈列表里,出现故障以后先到自愈模块去走一遭,如果走不通,再通知运维去干。
这个自愈模块包括一些MySQL经常会出现的问题:
1)复制异常
由于MySQL主从的架构,可能出现从机跟主机的通信被中断的情况,大概有以下四种:
问题:第一种就是relay_log在从机损坏了,如果没有及时处理,这时主机的relay_log被干掉,bug被修复以后可能会丢数据,做过DBA都知道一般主机、从机重启会导致relay被损坏 。
解决:可以通过一个方法开启relay_log,就是从第二个起就不要了,重新拿一次主库的relay_log再回来回放就好了;
问题:用过MySQL的应该也会经常碰到,如果一个表在操作,如果机器断链了,或者如果操作被kill掉了,它没有自动回滚的,然后再起来服务以后它就会报这个表是损坏的状态。
解决:数据异常以后对这个表做repair_table;
问题:这两个比较像。如果主从数据已经不一致,如果对数据进行修改,在主机上面给一条数据的时候发现从机没有,它就会报找不到这个表。
解决:暂时跳过,然后对于主机上有的数据从机上没有的就以主库为主,再引入另外一个工具 table-sync 自动修复从机的数据。
无论是发现的自愈,还是自愈后的补救措施都会记录到配置DB里,第二天再通过邮件发报表告诉运维人员复制异常自愈模块做了哪些工作,让他们知道这些东西要再跑一个脚本去看这个模块是不是在正常工作。
2)备份异常
备份异常和修复方法:
问题:这个是典型某个节点挂了,或者是当时网络有瞬断,会报的一个32管道的错误,由于那么大的量,各种网络上抖动等错误不能避免。
解决:一旦发现备份失败,平台立马就会去重试备份。另外冷对系统有异常的时候,也会报错,虽然错误可能不是一样的,但是具体的操作都是重试。
问题:如果MySQL自己出现了异常,比如在备份的时候,然后这个备份的selection被牺牲掉了,或者是业务进程把select给kill掉了,
解决:当捕捉到这个异常也是进行重试。
问题:这个跟复制异常的那一点也很像,其实就是把表损坏了。
解决:在复制异常的时候会去做表的修复。
3)最大连接数
问题:如果拨测的时候发现连接跑满了导致MySQL进不去。
解决:由于DB master 是一直通过长链接在MySQL上面的,所以拨测检测到异常的时候仍然可以进去,就可以去check-load,是什么东西导致了所有的连接数跑满,然后select,假如发现它是表锁了,就针对这种select牺牲掉它,让整个MySQL server恢复正常。
问题:另一种是没有锁的情况,只是业务单纯的sleep 导致连接满了,这是因为实例规格不同,对最大连接数的设置也是不一样的。
解决:为了避免运维凌晨起来,就可以把time out设久一点,比如sleep如果默认是八个小时,比如第一次设到一个小时,如果还缓存不了,就设到60秒,如果还缓存不了,运维人员再去处理。
问题:如果通过time out也解决不了问题。
解决:可以在这个服务器负载允许的情况下,就是内存容纳还够的情况下扩大它的最大连接数。
4)锁等待
问题:锁等待就是发现死锁以后怎么去做:
解决:一种就是通过活动连接这个最直观的方法,如果锁很多的时候活动连接就会很多;
第二种就是通过运用DB自身的系统库去做一些判断,如果检查到连接数是一样的情况下,就像刚才一样表锁了就指定牺牲掉;
5)极端高负载
问题:如果机器负载很高。
解决:平台会做一些高负载的修复方法,比如看到某一个实例的负载很高,平台就会判断MySQL是不是可以通过加索引去解决,如果可以,线上就会自动去加一个索引先修复,运维人员可以在第二天上班时间再去跟进。
平台的总体架构共分为四块:
1.Web Server
Web Server就是一个可视化的界面,后端提供一些API的服务,例如从主机到从机发起的迁移就是一个常任务,可能需要两三天的时间。
2.后台作业系统
常任务里包括数据对比这些东西,有一个作业系统进行管理,负责协调前端或者后端通过API发起的任务到公众模块的衔接;
3.功能模块
包括资源分配、备份中心、数据迁移、HA模块以及提供给客户的接口,客户通过API就可以拿到最大连接;
4.基础服务组件
任务运行agent:AJS
性能采集agent:cdb_report
异常容灾切换:TGW
基础服务组件包括腾讯内部的一个AJS系统;后端cdb-report是自研的一个采集器;还有异常切换需要用到腾讯的Tencent GateWay(TGW)。
平台总体架构图:












