基于神经网络的人工智能近年取得了突破性进展,正在深刻改变人类的生产和生活方式,是世界各国争相发展的战略制高点。
神经网络作为实现人工智能任务的有效算法之一,已经在各种应用场景获得广泛的应用。从云端到移动端,不同应用场景也对神经网络的计算能力提出了不同的需求。
神经网络的广泛应用离不开核心计算芯片。目前的主流通用计算平台包括 CPU 和 GPU,存在着能效较低的问题(能效即能量效率,是性能与功耗的比值)。为了获得更高的能效,我们需要设计一种专用的神经网络计算芯片来满足要求。国际IT巨头,如英特尔、谷歌、IBM,都在竞相研发神经网络计算芯片。
然而,神经网络的结构多样、数据量大、计算量大的特点,给硬件设计带来了巨大挑战。因此,在设计面向神经网络的高性能、高能效硬件架构时,我们需要思考清楚以下三个问题:
雷锋网本期公开课特邀请到清华大学微纳电子系四年级博士生涂锋斌,为我们分享神经网络硬件架构的设计经验。他将通过介绍其设计的可重构神经网络计算架构 DNA (Deep Neural Architecture),与大家分享在设计神经网络硬件架构时需要思考的问题。他在完成设计的同时,解决了这些问题,并对现有的硬件优化技术做出了总结。
本文根据雷锋网硬创公开课演讲原文整理,并邀请了涂锋斌进行确认,在此感谢。由于全文篇幅过长,分(上)(下)两部分。
可以把此地址复制到浏览器中查看上篇:http://www.leiphone.com/news/201705/8sB0WHz6D70J7NAy.html
公开课视频:
三、架构设计
讲完了计算模式的优化,我们接下来针对硬件架构设计给大家做一些分享。

我们研究工作的核心主要集中在计算模式的优化上面,而硬件架构本身其实更多的是如何去配合好的计算模式。
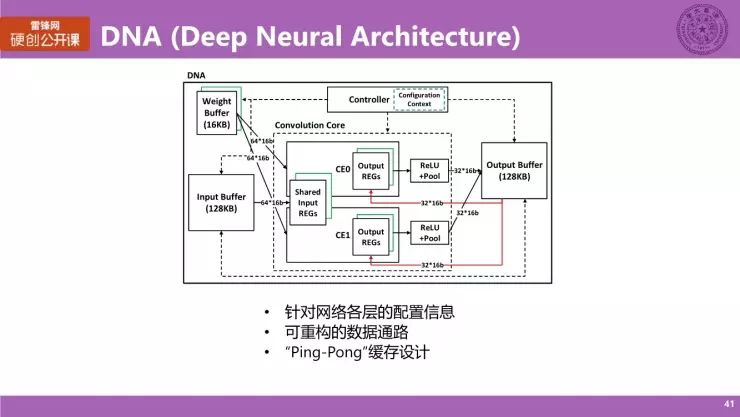
如图所示,这是 DNA 架构的一个整体的框架图。DNA 的全称是 「Deep Neural Architecture」,它的整体架构和我们之前提到的硬件架构模型是类似的,当然在具体的细节上就是会有一些参数,还有一些数据、通路上会做一些细致的一些策划。值得一提的就是说我们的计算核心内部有两个计算引擎,共享同一个同一块局部输入寄存器,但有各自的输出寄存器,而架构主要有三个特点:
针对网络各层的配置信息
架构在片上会存储一些针对网络各层的配置信息(Configuration Context),存储在控制器内部(蓝色虚框)
可重构的数据通路
即从 Output Buffer 反馈回 Output REGs 的通路(红线)是可重构的。此外,整体的输入数据通路也是可重构的形态。
另外在 CE 内部,它也会有一些可重构的数据通路,我们之后会展开。
「Ping-Pong」缓存设计
我们的设计中必须要考虑的一点,在于我们必须承认,对现有的这些深度神经网络而言,它的计算量数据量非常大,以致无法在片上完整地存储整个网络的数据和权重,所以在计算过程中,我们不得不与外部的存储进行频繁地访问。为了在计算过程中对存储器的访问不影响这些计算的性能,使得计算单元一直处于工作状态,我们需要对于每一块的这些存储进行一个「Ping-Pong」Buffer 的缓存设计,意思就是说在当前 Buffer 在工作的时候,它的另一块 Buffer 在外面保留数据,使得我当前 Buffer 用完的时候,下一次需要用到的数据也准备好了。
此外,我们对 CE 内部(Convolution Engine)内部做了一些额外的设计——4 级 CE 结构,这里提一些主要的概念。我做了一个空间上的展开图。
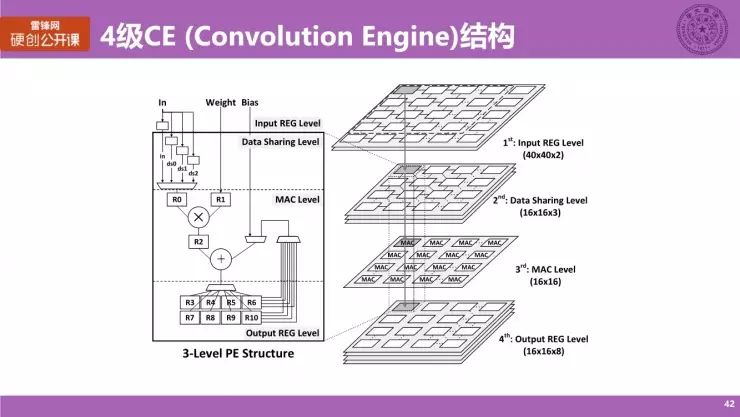
它主要有四个级别:
第一个层次叫做输入寄存器级(Input REG Level),对应的是 CE 内部的局部输入寄存器;
第二个级别叫数据传输级别,或称数据共享级(Data Sharing Level)。它主要是进行数据通路的重构,以支持我们刚刚提到的并行卷积映射方法,是很重要的一个部分。
第三部分就是最核心的计算机,即 MAC 级(MAC Level),MAC 就是乘加单元的意思,就是最核心计算以一个 16×16 的阵列实现。
第四级就是和输入级对应的输出寄存器级。
而我们前面也提到,CE 是由很多个 PE 构成的,那么此处 CE 的第二至第四层这三个级别,他们对应的是 PE 的三个级别,实际上 PE 也是一个三级的结构,和 CE 结构是对应的,比如对于一个 CE 来说,总共有 16 个 PE,所对应的就是 16 个 Map 和 16 个数据传输级的寄存器,从数值上我们也可以看到它的对应,具体就不多展开了。
数据传输网络
采用了并行卷积映射方法的时候,如何共享所使用的输入数据呢?我们设计了一个数据传输网络(Data Sharing Network,DSN)。这三个图分别对应的是 16×16、8×8 和 4×4 的网络,以不同的块和尺寸来进行数据的传输,传输的方向主要有三个,包括从左往右的横向、从上往下的纵向、以及斜 45 度角的从左上往右下的斜向,以相邻的数据块进行数据的传递。
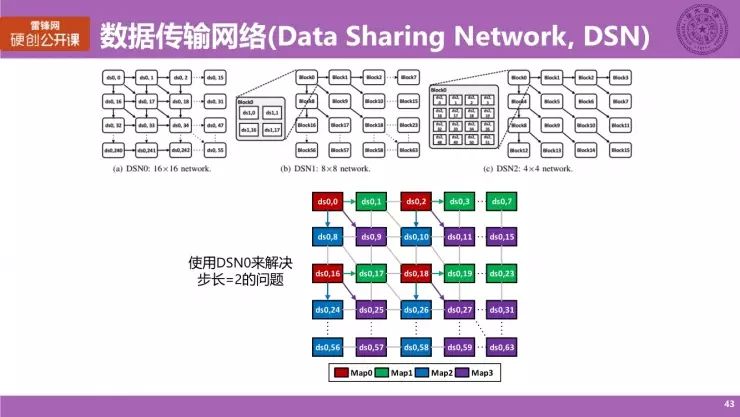
我们这里以步长为 2 且使用 DSN0 的一个案例简单看一看。我们之前说到,对于步长为 2 的情况,并行计算四张 Map,而每张 Map 的数据其实是复用的。具体来说,红色小块代表的是 Map0 的第一个点,它所收集到的输入数据是可以直接共享给它相邻的三个(绿色、紫色和蓝色)的三张 map 上面的,而它们只需要直接从红色小块上的 PE 上获取各自所需要的数据,并不需要从外部导进来。这样的话,其实从一定程度上减少了访存的次数。
工作流程与调度框架
有了一个架构之后,我们需要有一套的工作流程去指导怎么使用它。
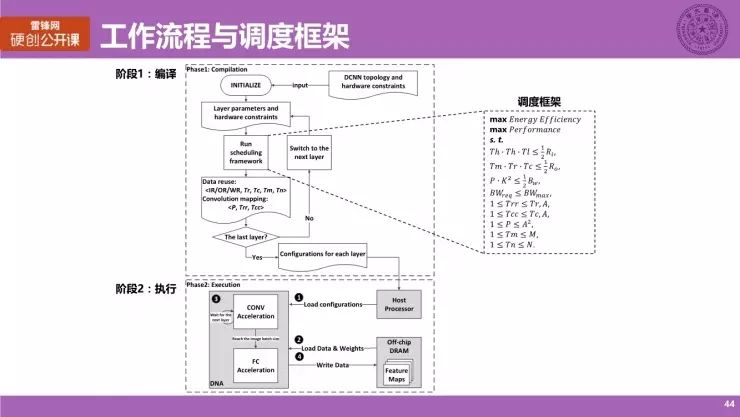
我们的主要工作流程主要分为两个阶段,一个是编译阶段,第二个是执行阶段。
阶段 1:编译
我们需要输入神经网络的一些参数,以及硬件的约束,比如 Buffer 的容量,还有计算资源的个数等描述硬件架构的一个参数,一旦硬件架构设计好后,这些参数是可以提出来的;
在我们的编译框架里面,需要对网络的每一层逐一地进行调度,并执行一个调度框架,它内部其实是在解决一个优化问题,优化问题是什么?
用户可以设定是要优先优化性能还是优先优化能效,或者优化两个目标,而它的约束条件就是我们硬件上的一些参数,比如说我缓存的需求不能超过片上的缓存大小等,这些都可以通过一个约束条件进行约束。通过执行一个调度框架,我们可以得到每一层的调度结果,分别由数据复用模式和卷积映射方式构成,并用一些参数化形式表达。
对神经网络的每一层进行这样调度,我们就得到每层的一个调度表,从而生成目标神经网络的配置信息,这时候我们就可以进入执行阶段,配置信息会放入到主处理器里。
阶段 2:执行
在执行过程当中,大家看左边大的矩形就是我们的 DNA 架构,它会不断地从处理中读取配置信息,随后会根据需求从片外的 DRAM 里读取数据和权重,在片上进行神经网络的计算,在计算过程中因为片上存储有限,它会将数据再写出到片外的 DRAM,这个过程是不断的迭代,就以图中 1234 的次序进行迭代,以完成整个神经网络一个计算,这是我们所说的逐层加速的一个策略。
我们在这里简单地展示了 AlexNet 的网络在 DNA 架构上的一个调度结果。
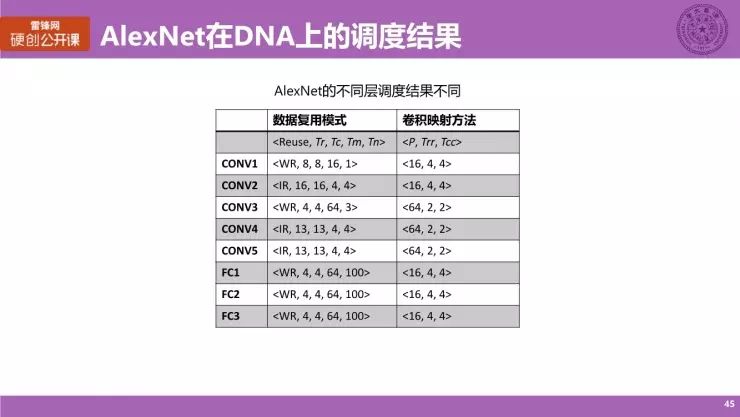
图上呈现的是神经网络的每一个层,这里其实既包括卷积层,也包括全连接层;采用了数据复用模式与卷积映射方法。从参数中我们可以看到,对 AlexNet 的不同的层,它有不同的调度结果,这其实也是符合我们预期的。
四、实验结果
到目前为止,我们已经讲完了基本的计算模式和架构设计,接下来我们就看一看一些实验结果。

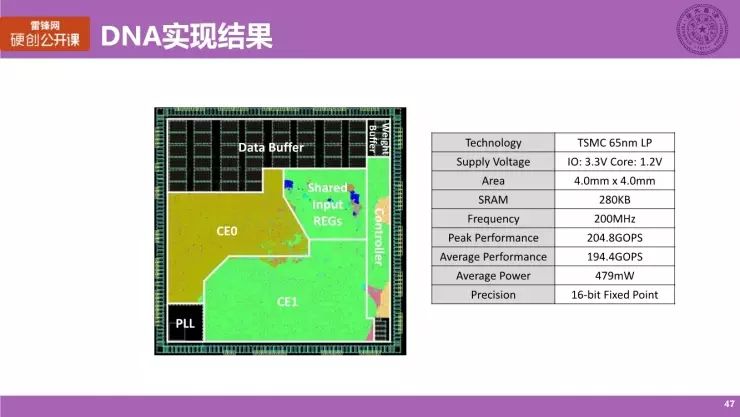
这是 DNA 架构的实现结果图,图上每个模块也标出了对应的区域,右边是主要的一些参数,我们使用的是 TSMC 65nm LP,面积是 4.0×4.0 平方毫米,片上的 Buffer 容量是 280KB,在 220MHz 的工作频率下,控制性能达到了 204.8 GOPS,而平均的性能是 194.4 GOPS,平均功耗是 479mW,需要注意的是,这里的功耗指的只是架构芯片设计的功耗;架构内部的数据宽度(Precision),它是 16 Bit 的定点宽度。
我们直接看一下结果。我们使用的是 AlexNet、VGG、GoogLeNet 与 ResNet 这四个非常经典的卷积神经网络,这两个图分别展示了总能耗降低及 PE 利用率提升的情况:
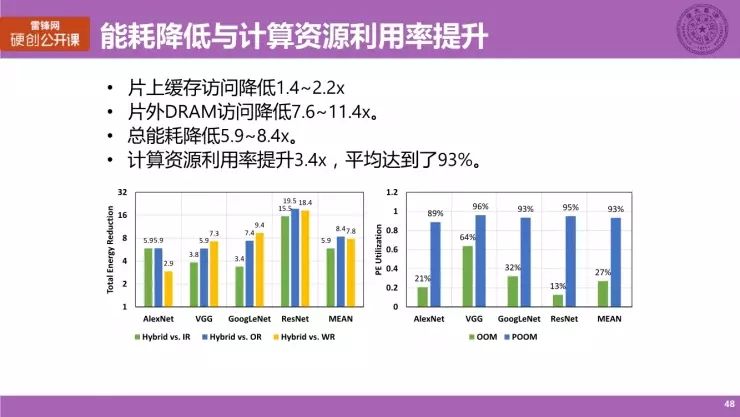
片上缓存访问的降低达到 1.4 到 2.2 倍,主要是与 Input Reuse、Output Reuse 与 Weight Reuse 来相比。
片外 DRAM 访问降低了 7.6 到 11.4 倍;
总能耗的降低达到了 5.9 到 8.4 倍,这是一个比较大的一个提升,
计算资源利用率平均提升了 3.4 倍。而平均的利用率是达到 93%,这是非常高的一个值。
与顶尖工作比较(AlexNet)
除了方法上的比较,我们还和目前顶尖的这些工作进行了一些比较,这主要和英伟达的 K40,还有 FPGA'15、ISSCC'16 等非常经典的神经网络架构的文章进行一些比较,具体的话不进行过多展开。
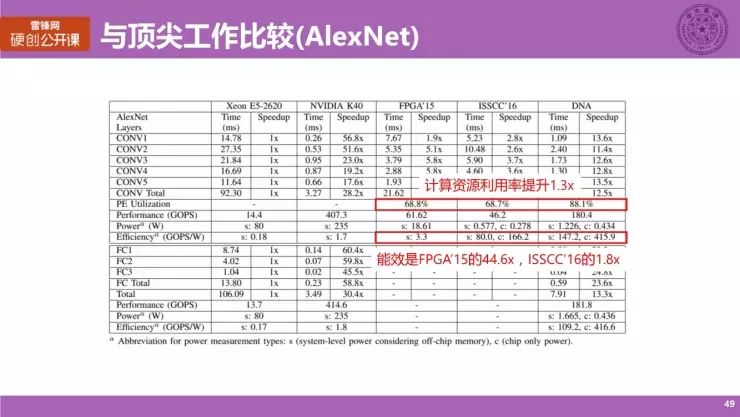
这张表展现的是 AlexNet 上的一些具体分析结果,大家主要看一些参数。
第一个是计算资源利用率,我们评估了一下,在 FPGA'15、ISSCC'16 的工作上,计算资源利用率大约只有 68%,而用 DNA 架构,可以获得 88% 的一个计算资源利用率,达到 1.3 倍的提升,还是个比较大的一个提升。
另外值得提的一点是,我们的能效是 FPGA'15 的 44.6 倍,是 ISSCC'16 的 1.8 倍。大家看名字也能知道,前者是在 FPGA 上实现的,而后者是在 ASIC 上实现的。
特别强调一点,我们这里比较的能效是系统能效。大家通常喜欢比较的是纯芯片的内部能效,不考虑片外存储,其实并不是特别公平。
我们在评估芯片本身的能耗以外,还评估了片外 DRAM 的能耗,综合起来我们称之为系统能效,我们认为这样的比较是相对合理的。在这种比较下,我们获得的能效提升也是非常好的。
最后,我们与更多的一些工作进行比较。这一张表格里有展现出来,我们直接看结论。
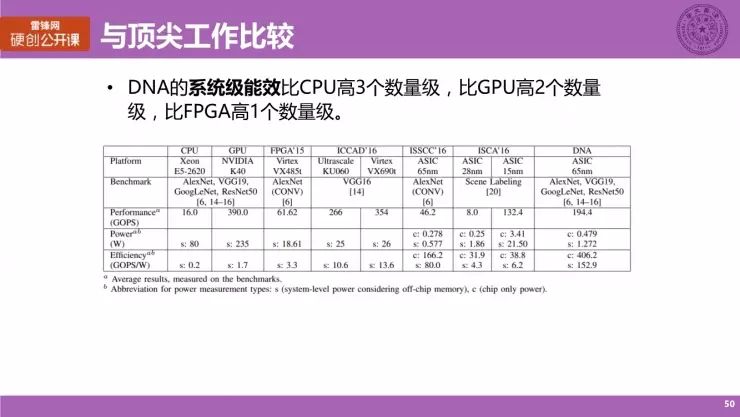
我们的 DNA 架构,它的系统级能效比 CPU 提高了三个数量级,比 GPU 高两个数量级,比 FPGA 高一个数量级,基本上达到我们的设计需求。
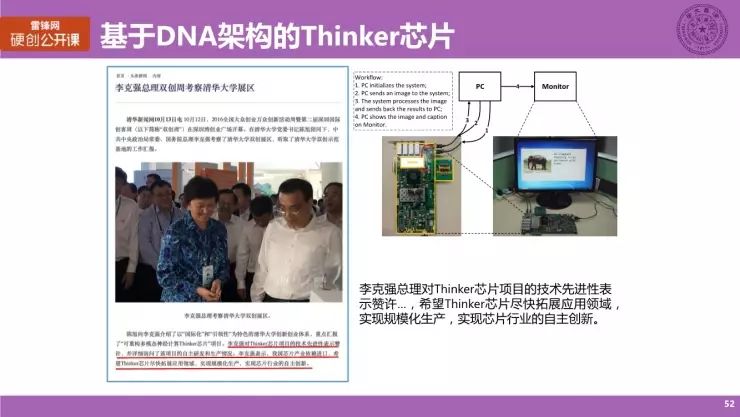
基于 DNA 架构,我们完成了一款 Thinker 芯片,这是一款可重构的神经网络计算芯片。左边是芯片的照片,右边是我们搭的芯片 demo 演示图,相关的成果已经发表了数篇的顶级会议文章和权威期刊文章。

值得一提的是,我们在今年 ISSCC(该领域的顶级会议)上作了 poster 的展示。
此外,这款芯片作为清华的杰出的代表性工作,参加了 2016 年的全国双创周展览,获得李克强总理的高度赞许。李总理表示,希望 Thinker 芯片尽快拓展应用领域,实现规模化生产,实现芯片行业的自主创新。这是一个非常高的评价,我们会继续努力,实现总理对我们的期望。
五、总结思考
首先回到最开始提出的三个问题,我们对这三个问题都做了非常好的解决。

好的计算模式是怎么样的?
首先它需要具备一个混合的数据复用模式,另外还需要一个并行的卷积映射方法降低总能耗,以提升计算资源利用率。
为了支持这样的计算模式,架构应该怎么设计?
我们设计了一款可重构的神经网络计算架构 DNA,它具有可重复的数据传输通路和计算引擎。
我们对针对计算模式做了一个很好的架构设计,相比 CPU、GPU 和 FPGA 都有多个数量级的系统级能效提升。
已经实现的架构,针对具体算法和应用需求,如何配置成最优的计算模式?
我们设计了一个基于网络层的调度框架,配合架构的使用,将调度问题转化成一个优化问题。这样一来,针对任意的网络,其他的架构也可以使用我们的调度框架,将调度问题转换成优化问题,配置成用户想要的最优计算模式。
这些所有的相关成果已经发表在今年的 IEEE Transactions on Very Large Scale Integration System(TVLSI)上。
最后我们对现有的优化技术做一些思考。
最开始我们在分析的时候提出了两个主要公式,分别对能耗和性能进行评估。这两个公式其实是一个非常好的一个描述,或者说建模的分析方法。
我们也对近几年出现在顶级会议和权威期刊上,针对神经网络硬件架构所使用的硬件优化技术以及算法优化技术进行了整理。

计算模式优化
第一类就是其实是和我们这份工作很相关的,就是计算模式方面的优化。它主要优化的是什么?它通过降低访存次数来以及提高计算资源的利用率来实现能效、能耗和性能的优化。
模型压缩、降低数据精度及二值化
这些技术主要能够降低单位 DRAM 和 Buffer 访问的能耗以及单位计算的能耗。
非易失存储器
第三类是在学术界非常流行的非易失存储器,简称 NVRAM,将这种新型的存储器应用到我们的架构设计当中。NVRAM 具有一个非易失的特点,然后它的通常它的功耗是很低的,可以降低单位存储访问的能耗;有的工作,比如说使用 NVRAM 进行乘加计算阵列的构建,甚至可以降低单位计算能耗。
稀疏化
无论是算法还是硬件,稀疏化是大家目前都非常关注的一个特点。不管是数据还是权重,神经网络其实有大量的零以及接近零的数值,我们通过人为的一些控制,使得数据里面出现更多的零,这样我们可以减少从存储器中访问数据的次数,甚至可以降低操作数,因为如果是零的话,我可以不做计算,因为零乘以任何数都是零。
神经网络的基本计算就是零,所以稀疏化的好处就是可以降低访问次数和操作次数,对于能效的好处是非常明显的。
动态电压频率调节
动态电压频率调节简称 DVFS,它是一个非常经典的、大家很常用的电路技术。我们可以通过降低电压和频率,来降低单位访存和计算能耗。如果我希望获得很高的性能,我可以通过提升电压以提升频率,来获得更好的性能。
我们可以发现,目前现有的这些优化技术,其实都对应我们对性能或者能效的设计或优化的需求。
通过对现有这些技术的分析,也可以启发我们所做的事情。比如说,我们如果想用新的技术,可以回顾一下这两个公式,是否真的有效,是否解决了关键的问题?这其实是我很想分享给大家的观点。
这里有我的一些联系方式,包括个人主页、知乎专栏,电子邮箱等,欢迎大家与我联系。

我在维护的 GitHub 项目名为「Neural Networks on Silicon」,因为我们领域近几年呈现爆发式的发展,有大量新的工作出现,我在 GitHub 上做了一个小小的项目,整理了一下近两年出现在这个领域顶级会议上的一些论文,也会对部分有意思的工作做一些评论。大家有兴趣的话可以看一看。其实这也是一个蛮好的整理,但因为现在的工作实在太多了,大家也可以帮助我一起整理。
这页 PPT 上呈现了刚刚涉及到的一些重要参考文献。

提问环节
好,谢谢大家,现在进入提问环节。
1. 你们的工作和国内外神经形态芯片相比(非加速器),有哪些优势?
我简单介绍一下,我们的神经网络硬件芯片这一块主要有两个流派,一块是神经网络加速器范畴,另外一个是神经形态芯片,英文叫做 neuromorphic chip. 而我们的工作属于神经网络加速器的范畴,而题主提到的神经形态芯片属于另外一类芯片,以 IBM 的 TrueNorth 为代表。那么二者的主要区别是什么?
它们主要是算法原型不一样。前者或者说我们的工作主要针对的是人工神经网络,特别是强调就是当前非常流行的,以深度学习为代表的神经网络,而后者的算法模型是我们称之为叫脉冲神经网络,英文叫做 spiking neural network。
在脉冲神经网络的网络里面,数据以脉冲信号的形式进行信号信息的传输,这样一种网络,或者说这样的计算方法,其实更接近我们最开始提到的生物上的什么样的模型,
首先,二者因为目标算法不一样,所以不好直接比较性能和功耗,如果你看到一些直接比较功耗的工作话,我觉得并不是特别公平,因为连目标算法都不一样,设计的目的也不一样。我们做科研非常讲究公平比较,为了更公平的比较,其实硬件层面其实并不是很好的一个比较方式,比如从算法层面来比较深入学习和脉冲神经网络。当前的主流观点是前者的精度更高(识别人脸),而后者因为更具备生物上的一些特点,在能效上更有优势。
我个人的观点是:就目前而言,深度学习几乎统治了模式识别的各个应用领域,是当下更好的一种选择,但是科学是螺旋式发展的,深度学习不可能永远地统治下去,我觉得也应该不会是人工智能的最终形态。
脉冲神经网络,其实代表的是科学探索的一个方向,但我觉得也并不是唯一的方向。如果关注人工智能这块的话,我们其实会看到有很多其他的方向也在展开,比如说量子计算。
人工智能的最终形态并不一定是制造一个人的大脑,或者人脑。关键在于是否能够解决问题,比如说我们要识别人脸,什么样的算法才是好的算法,那么怎样的算法才能解决问题,这才是关键。而它具体的形态并不是我们特别关心的,这里有个比较恰当的例子分享给大家,好比人要飞翔,其实并不需要有一个鸟一样的心态,历史上已经证明过,很多人制造了翅膀也飞不上去,其实我们只要造一架飞机就够了,甚至我们还能飞上天空甚至飞出银河系。我们不在乎形态是怎样,关键是要能够解决问题。
2. 你们在第二代架构在设计上有哪些构想?
这位同学应该是看了我知乎专栏上的一些文章。其实刚刚有提到,现在有一些比较大家常用的一些技术,就像稀疏化等,其实在我们的二代架构设计当中已经有一些考虑。基本上不能说有多大创新,但我们都会考虑进来。
这是我们现在在做的一些工作,主要想解决大家真正在用神经网络硬件架构的时候会遇到的一些实际的问题,如果有新的成果发表出来,也会及时地分享给大家。
3. 芯片只针对推断进行优化吗?推断其实就是前向计算的过程,没有包括训练的过程吗?
在第一代神经网络芯片 Thinker 上,我们主要只针对正向计算做了优化,如果大家对训练过程比较了解的话,其实训练的过程当中有大量的正向计算的过程,当然它还包含了一个反向的误差传播的过程,在我们第一代芯片当中没有考虑误差传播的过程,我们已经在做一些相关的工作,如果做出来之后会及时地和大家分享一下我们的一些想法。
4. 如何看待「芯片+人工智能」这样一种模式?
我简单讲讲吧,大家从新闻上已经能看到很多报道,说人工智能时代到来了,其实人工智能或者这个概念,我觉得更多是媒体在为了宣传的方便,所以靠一个很好的帽子,也更方便大家理解。
其实我们刚才也提到,大家经常说到人工智能,其实它背后有更多的内容,比如深度学习、机器学习等,深度学习本质上就是神经网络,只是经过很多年的扩展之后或者说发展之后,成为现在的样子。
那么人工智能硬件或者说芯片,简单来说叫做智能硬件。它在未来就是一定会代替人做很多事情,这是未来的一个发展趋势。随着生活智能化,未来的智能硬件会越来越多,会代替人做很多事情。比方工厂里使用一些机械臂,或者说一些生产线上的工具,可以代替人做体力劳动。
智能硬件在未来,肯定会代替人去做一些稍微低级点的智力劳动。人的伟大,其实是在于创造工具、使用工具,我们会制造越来越多的智能工具,替代我们做很多我们不想做的事情或者说反复的事情,让我们用有限的精力去做更多的、更高层次的一些智能任务吧。所以我觉得「人工智能+芯片」或者说智能硬件的一个模式在未来肯定是会一直发展下去的,是不会变的。
5. 如何看待 GPU、FPGA、ASIC 的未来?
我谈一点自己的见解,GPU、FPGA、ASIC 是当下智能硬件,或者说人工智能芯片的三个极点。GPU 可以认为是偏向通用的一类硬件,然后 ASIC 是相对专用的一种硬件,而 ASIC 是介于二者之间的一种硬件,它们各有千秋,然后各有所长。当前 GPU 广泛地应用于训练过程或者说大量数据的训练。FPGA 可以根据应用的需求非常适应性的去改变配置,把不同的算法烧进去,完成不同的功能。
狭义上的 ASIC,可以具体的某一种应用,或者说比方说做一款芯片来专门实现人脸识别。大家可以看到,我们刚刚介绍的基于 DNA 架构的 Thinker 芯片,其实是一种可重构的 ASIC,这种结构叫做 CGRA(Coarse Grained Reconfigurable Architecture),它其实有点像 FPGA,它可以重构配置来支持不同的算法。我们可以支持任意网络规模、任意参数的神经网络,它的好处是我们采用大量粗粒度的 PE 形式的计算资源,使之能够快速地、高效地、在线地配置计算资源的形态来支持不同算法。
其实我个人觉得,针对未来可能会发展成一种融合的形态,不知道大家有没有注意到,英伟达最新发布的 V100 其实是有 Tensor Core 的,因此我觉得未来的通用计算可以处理很多复杂的控制或者逻辑等。
而一些很关键的计算,比方说神经网络里面的神经元计算,或者说一些核心的计算,会做成一些专用的 ASIC、可配置的核,放入通用的一个处理器如 CPU 和 GPU,甚至是 FPGA 里面。其实这就是融合的一种思想。
此外 CPU 通常用于训练一个过程,有很多实际的应用场景,或者说我们刚才提到云端与移动端,移动端的话有大量的低功耗的需求,此时用 CPU 平台就显得不是那么合适,所以说其实我外部的控制逻辑可以稍微简单一点,像我们用到的我们设计的这款可重构的芯片就可以直接运用到其中。
对于神经网络的应用来说,它其实是有一定通用性的,所以在移动端,它其实有很大的潜力,作为一个处理的核心来做神经网络计算,来实现如图像识别或者语音识别的任务。
今天的公开课就到此结束了,非常感谢大家来收听和观看雷锋网的硬创公开课。我和我们组也会继续做神经网络硬件架构的一些研究,刚刚跟大家分享的也是我们过去一些研究的成果和思考。我们现在也在做一些非常有意思的研究,也欢迎大家跟我们交流,如果有一些新的成果,我也会及时和大家分享,今天的公开课就到此结束,谢谢大家,再见。
AI科技评论招业界记者啦!
在这里,你可以密切关注海外会议的大牛演讲;可以采访国内巨头实验室的技术专家;对人工智能的动态了如指掌;更能深入剖析AI前沿的技术与未来!
如果你:
*对人工智能有一定的兴趣或了解
* 求知欲强,具备强大的学习能力
* 有AI业界报道或者媒体经验优先
简历投递:
[email protected]










