Zendesk是美国一家做客户服务的公司,提供产品创新和定价等服务,他们的机器学习平台使用的是TensorFlow;之前InfoQ从TensorFlow与Kubernetes/Docker的结合上给出了一些企业实践文章,而在模型部署上,这篇文章是个好例子;Zendesk使用TensorFlow Serving来加载TensorFlow模型,使用修改后的protobuf生成原生可用(bazel-free)的Python gRPC客户端,同时介绍了模型压缩、AB测试等经验。此文由原作者授权,InfoQ中文站翻译并分享。
在Zendesk,我们开发了一系列机器学习产品,比如最新的自动答案(Automatic Answers)。它使用机器学习来解释用户提出的问题,并用相应的知识库文章来回应。当用户有问题、投诉或者查询时,他们可以在线提交请求。收到他们的请求后,Automatic Answers将分析请求,并且通过邮件建议客户阅读相关的可能最有帮助的文章。
Automatic Answers使用一类目前最先进的机器学习算法来识别相关文章,也就是深度学习。 我们使用Google的开源深度学习库TensorFlow来构建这些模型,利用图形处理单元(GPU)来加速这个过程。Automatic Answers是我们在Zendesk使用Tensorflow完成的第一个数据产品。在我们的数据科学家付出无数汗水和心血之后,我们才有了在Automatic Answers上效果非常好的Tensorflow模型。
但是构建模型只是问题的一部分,我们的下一个挑战是要找到一种方法,使得模型可以在生产环境下服务。模型服务系统将经受大量的业务。所以需要确保为这些模型提供的软件和硬件基础架构是可扩展的、可靠的和容错的,这对我们来说是非常重要的。接下来介绍一下我们在生产环境中配置TensorFlow模型的一些经验。
顺便说一下我们的团队——Zendesk的机器学习数据团队。我们团队包括一群数据科学家、数据工程师、一位产品经理、UX /产品设计师以及一名测试工程师。

Data Team At Zendesk Melbourne
经过数据科学家和数据工程师之间一系列的讨论,我们明确了一些核心需求:
经过网上的调研之后,Google的TensorFlow Serving成为我们首选的模型服务。TensorFlow Serving用C++编写,支持机器学习模型服务。开箱即用的TensorFlow Serving安装支持:
TensorFlow模型的服务
从本地文件系统扫描和加载TensorFlow模型
(小编注:TensorFlow和TensorFlow Serving的区别:TensorFlow项目主要是基于各种机器学习算法构建模型,并为某些特定类型的数据输入做适应学习,而TensorFlow Serving则专注于让这些模型能够加入到产品环境中。开发者使用TensorFlow构建模型,然后TensorFlow Serving基于客户端输入的数据使用前面TensorFlow训练好的模型进行预测。)
TensorFlow Serving将每个模型视为可服务对象。它定期扫描本地文件系统,根据文件系统的状态和模型版本控制策略来加载和卸载模型。这使得可以在TensorFlow Serving继续运行的情况下,通过将导出的模型复制到指定的文件路径,而轻松地热部署经过训练的模型。
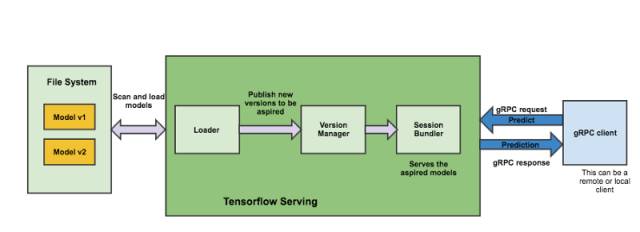
TensorFlow Serving Architecture
根据这篇Google博客中报告的基准测试结果,他们每秒记录大约100000个查询,其中不包括TensorFlow预测处理时间和网络请求时间。
有关TensorFlow Serving架构的更多信息,请参阅TensorFlow Serving文档。
原文链接:
http://mp.weixin.qq.com/s/M3E8t19I5a5fR6a5vkQFAQ










