Wannacry1.0勒索未完,变种2.0开始以3600台每小时速度席卷全球
2017年5月13日,Wannacry病毒正以洪水之势扑向全球,截至到2017年5月16日,全球共计150多个国家、20万个设备受到影响,包括医疗、能源、交通运输、教育、金融、通信、制造行业、公共安全等都受到了大规模冲击,数据丢失,业务中断。仅国内就有近3万个机构和企业受到攻击,小到个人,大到政府机构,甚至连公共安全部门都不能例外。此次事件已经直接威胁到了全球政治和经济秩序的安全。目前病毒正在变种中,新的一波冲击正以每秒3600个设备的速度攻击全球……
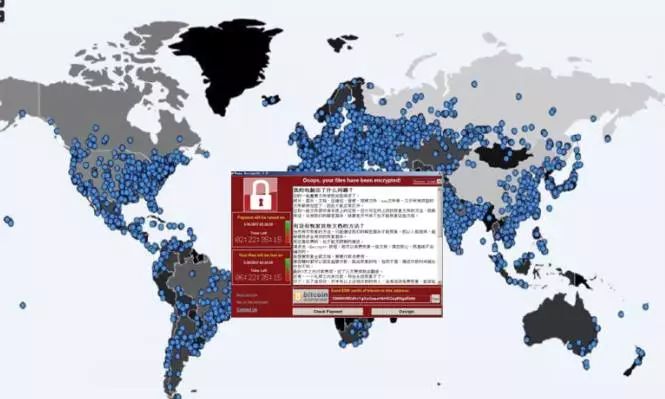
为什么受影响之大?
这次病毒很快就袭击到全球的网络,除了措施、工具、系统未落实外,很重要的一点还与采用的IT基础架构硬件和软件相关。
传统IT数据中心,为什么在遇到病毒破坏后的数据恢复慢?
传统的IT数据中心,通常是由各式服务器、存储、网络设备、安全设备、各类应用软件、磁带库等构成,样子如下:

在普通的服务器或者桌面电脑上开展业务,拿服务器举例(办公电脑上相对简单一点,但复杂度也不低),大部分IT部门,通常包括如下几个步骤:
a) 部署服务器到数据中心
b) 安装部署操作系统
c) 升级操作系统到最新的补丁状态
d) 安装数据库系统
e) 安装应用服务器软件
f) 安装周边支撑和工具软件
g) 安装业务软件
h) 调试系统
i) 进入生产状态
一旦病毒入侵,把a-i 任何状态的数据(包括软件配置/软件执行程序/库等)破坏后,要进行大量的软件恢复工作后,再进行数据恢复比对、核查。这一步的前提还是在有备份数据的情况下。如果被Wannacry或类似恶意软件锁定,首先解决的是怎样找到可用的、正确的数据。要确保有数据,就得有数据保护机制,特别是数据备份、数据容灾体系的建立。
目前针对物理机体系的数据保护软件,通常采用如下方案构成:
一套保护软件 (可能是厂家A)
一组服务器,通常2-3台起(厂家B)
一组存储(厂家C)
一套归档设备,如磁带(厂家D)
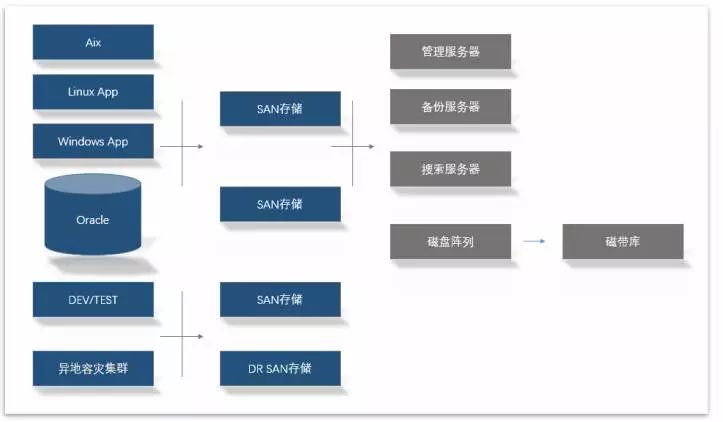
如果要加强数据容灾,还得在异地部署一套对等设备,中间再租用专线。
挑战出来了,通常这类方案特点:
- 由于设计复杂性、软硬兼容性测试,部署实施周期都在几周-几月
- 使用门槛高,导致在出现紧急恢复时候,时间太长。因为各种情况要考虑运行环境修复处理,数据校验比对,无法进行快速恢复,甚至都不敢恢复业务
- 包括近1-2年银行在内的故障事件表明: 异地容灾,安慰居多,能用的少
本质上是基础架构决定了上层数据保护的复杂性,数据恢复时间高达数小时到数天。这个时代的厂商要花大力气解决各种兼容性问题,需要经历很长的时间,投入大量资源,方案才能进入成熟期。这就是为什么,在存储备份领域,一直是国外的大型IT厂商主导。即便这样,也很难快速解决病毒对数据破坏的威胁。因此传统方案研发重点主要在以下几点:
-大量硬件,系统软件、应用软件的兼容性研发
- 数据规模相对小,考虑的是单机的可靠性稳定性,大规模扩展不是考虑重点
- 通过在物理服务器内部安装客户端软件,提高备份速度
- License化各模块,变相提高部署管理的复杂度,增加服务收入
复杂的体系设计,只会让病毒无形中放大了影响时间。总之,恢复慢重要的三个原因是:
- IT系统物理服务器居多,构建复杂,业务流程复杂
- 数据保护系统设计复杂,功能使用路径长
- 恢复方案主要是通过回写数据完成,越大越慢!
正因为传统数据中心时代,随着业务和应用的不断发展,基于传统的IT模型导致IT规模增大,出现以下问题:
- 数据中心空间不够用
- 高能耗
- 维护成本高
- 各种安装部署复杂
导致IT不能够快速响应需求,越来越多的政企环境开始演化为虚拟化/云化结构,提供了资源利用率和管理的灵活性,这种架构面对病毒,有更从容的保护方案可以应用。

我们先来看公有云市场,目前在此病毒勒索次事件中,受到的影响比较小,根本原因有两点:
a) 公有云在网络防护层面做了很多基础保护系统,上层的防护特性更好,门槛低、容易启用
b) 公有云运维技术团队较强,短期内可以快速反应,收敛病毒的影响
但也不能说,公有云就绝对安全了,安全是一个体系,涉及到平台、应用、用户。包括软件的设计、用户的行为、周边的安全环境等都在影响着数据安全。
在私有云市场,我们很幸运,VMware、微软等带动了商业虚拟化市场的全球应用,比例曾高达70%份额。KVM, XEN等开源虚拟化体系,在国家、大型企业、开源组织的推动下,正在一起重构传统IT架构。据主流机构预测,到2020年,中国云化数据中心市场在5000亿以上,说明IT决策者们看到了传统数据中心的各种问题,逐步在升级改造原有的数据中心。
受影响的都会很低调,不会主动传播有损企业形象的事件。从技术架构上看,新型数据中心在资源、硬件容错、自动化迁移管理方面解决了不少问题,但病毒对这类数据中心威胁程度一样,上面跑的Windows、Linux等系统面临同等情况的威胁:系统文件、应用软件、应用数据都可能被恶意加密;如果虚拟化软件本身出现了被病毒利用的漏洞,那影响的将是一批业务系统。绝大部分情况,企业或机构的IT团队规模是远远低于公有云技术团队。在这种情况下,借力专业数据管理和保护方案就显得特别重要。
我们再回顾一下,云化数据中心在国内经历了3个阶段:
阶段一:
2008-2010年之前,虚拟化属于初级发展阶段,这期间属于非核心业务时代,属于在摸索、测试阶段,应用场景大多是在开发、测试等非核心环境中。首要原因是虚拟化技术还比较新,IT人员掌握起来有一定难度,同时,PC服务器的性能还不足以跑虚拟机环境和重要应用。
阶段二:
2010-2014年,虚拟化进入逐步规模应用时代,包括一些内部OA、知识管理、邮件、内部IM等,由于SSD 、高速网络、内存、多核CPU架构的兴起,中等配置的PC服务器通过虚拟化可以足够满足一些基本应用的虚拟化要求,后期逐渐开始过度一些重要业务逐步开始应用。
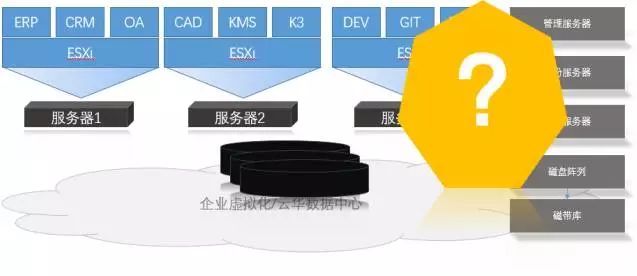
针对传统数据中心的数据保护方案已经不能适应
阶段三:
2015-2017年,虚拟化增强架构/云化架构开始爆发,大部分客户需要的依然是服务器计算虚拟化为核心,并适度增加网络、存储调度与管理能力。由于硬件性能提高的同时,价格大幅度降低,重要应用逐步开始虚拟化,包括ERP、CRM、交易系统、财务、各行各业核心应用等。对系统可靠性要求极高的金融行业,也逐步开始在虚拟化和云化环境部署重要生产业务系统。
这就回答了为什么在2015到2017年之前,在国内很难有专注的虚拟化数据管理领域的公司出现,答案是:市场基础还不够,普通价位的PC服务器性能不够,性能配置强的成本太高。
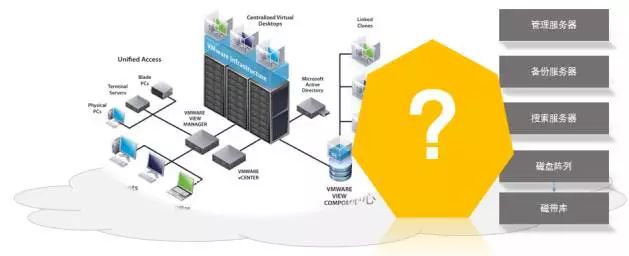
过渡到第3阶段之后,云化时代有三个特点:
- 部署一套系统,分分钟可以完成,因此数据增长很快,数据规模急剧增大
- 业务进行了拆分,由原来多个业务集中到每业务一个或多个虚拟机系统
-业务由地理分散,开始进行了集中
因为以上的新特征,在原来已有的指标:RTO、RPO等级量化管理能力外,相应的也对方案提出新要求:
- 数据管理容量和性能要能按需扩展
- 能快速恢复系统,而不仅仅是应用、文件和数据
- 针对病毒这样的威胁,要求系统具备很强的容灾能力
- 更可靠,更安全,数据100% 能恢复
-管理、维护要很简单、灵活、便捷
针对以上需求,木浪云的创新思路: 融合与按需
基于WebScale模型架构,软件、硬件与云一体化融合数据管理方案,针对Wannacry勒索病毒等带来的威胁,无论数据规模多大,都能轻松部署,从容应对!

目标:
精简融合保护备份、恢复、异地复制、数据分析、搜索、云复制能力等,一个产品解决所有问题,简单易懂易用。
能力优势:
这种设计好处就在于:上手容易、配置快、管理简单、对管理员友好。
在最快情况下,无需专业备份或虚拟机管理员,普通毕业1-2年的IT工程师,在10-20分钟可以搞定一次部署,每次备份在1-3分钟可以完成,大幅度降低企业在运维管理方面的投入和开支。
针对Wannacry:
- 59秒内恢复
由于操作简单,底层有极速恢复支持硬件和软件体系,对于病毒受破坏的系统,仅需几十秒钟就可以恢复到健康状态。
- 无限独立可恢复版本
针对病毒威胁,产品设计上采用无限制独立版本系列,数百到数千个版本,可以轻松恢复到任意1个版本,粒度可以是系统,也可以是系统内部的文件、文档等,轻松应对病毒加密数据带来的威胁!
传统方案:
传统的方案需要周期在几天到几周,通常需要资深的管理员学习很长时间才能管理好。原因就在于,每一块都有自己的管理平台,风格不一,需要学习备份,存储,带库等等知识技能才能掌握。这也是传统方案成本高的原因之一。
目标:
简单说:就是可以管理整个数据中心的数据。可以跨越多台木浪云软硬一体化产品,实现全局检测重复数据
能力优势:
- 最大节省90%成本
可以最大程度去除90%的重复数据,大幅度降低企业数据管理和数据灾备成本!规模越大,越有优势!
-提高防护率到100%
有了木浪云这种全局数据管理能力,无论多大规模的网络,从数百到数千规模的云化数据中心,都可以轻松自动保护全部业务系统, 提高数据中心整体防护率到100%
传统方案
我们知道,传统的方案支持的虚拟机规模有限,当支持更大规模虚拟机后,需要部署多套方案,而虚拟机底层磁盘本身数据重复度很高,部署越多,重复数据占用的空间越大,消耗的成本越高,也难管理。所以,传统的方案很难解决规模化虚拟化数据中心管理难题。
目标:
自动扩展系统,无需手动添加、删除、移动备份数据、备份任务等,系统智能管理负载,并进行全局平衡,大幅度降低运维扩容成本和难度。
能力优势:
- 设计模型,支持2PB保护容量
目前通过WebScale模型,设计上可以支持96个节点,管理多达2PB的保护容量。这是什么概念? 小到中小型企业,达到大型集团公司,云平台运营商都可以轻松支持。传统的方案如果支持大体量的数据中心管理,投入将会是木浪云的3-5倍!
- 集群最大并行备份任务 5000个
系统设计采用多节点并行智能调度方案,企业正常数据增长规模下,可并行支持5000个任务以上,解决超大规模云数据中心的保护难题;同时,任务在所有节点可以任意切换
传统方案:
分成两种情况,
1)软件方案通常不能进行全局数据管理,软件的扩展只是添加备份存储,全局存储性能和容量并不能同步扩展。这样就带来一个问题,软件方案只能解决一半的扩展问题,不能解决性能问题,并行能力弱。
2)如果是一体化,传统方案通常就是软件安装在一台服务器上,服务器内部通过Raid存储数据,并行能力弱。传统方案最大容量受限于服务器的硬盘槽位数。通常扩展的时候,系统需要停机重新调整存储架构,同时面临数据丢失的风险。目前这种方案,通常最大扩展的容量也在100TB规模左右。考虑3-5年的扩容,一次性投入成本会再多出30-50%。
目标:
公有云有天生的数据灵活和异地容灾优势,企业通过我们特别设计的公有云数据复制技术可以安全方便、更低成本、更快速度管理历史冷数据或做数据冗余。
能力优势:
-减少80%的云复制投入
通过木浪云的云复制技术,最理想的情况下,相对传统方案,将会减少80%的投入。一个趋势,国家大力推进云计算产业的落地,最重要的一条是降低接入带宽的费用。
云在应对病毒威胁的场景中,又多了一条便捷的通道,重要的数据可以轻松加密复制到公有云存储系统,形成云灾备。
传统方案:
集成云本身不是一件难事,难点在于如何把数据轻松复制到云,同时根据需要还可以快速取出,并融合到数据备份、恢复、内容搜索等应用逻辑。
传统的方案,更多就是调用API ,上传数据到云; 需要单独购买部署软件。

木浪云采用一体化,可伸缩扩展模型,轻松保护虚拟化/云平台
下面是更细的一张效果对比表
|
|
|
|
木浪云
|
传统方案
|
|
可全局管理数据规模
|
按需模块化扩展,24TB-2PB
|
通常最大在100TB-200TB
|
|
RPO表现
|
分钟级,随着集群节点增加,整体RPO性能保持不变
|
分钟到小时级,处理任务规模越大,RPO越不能保证
|
|
RTO表现
|
59秒内
|
分钟级,数小时
|
|
并行恢复接管能力
|
节点越多,并行接管能力越强,最多并行恢复接管480个虚拟机
|
单个设备支持个位数的虚拟机接管
|
|
部署实施时间
|
15分钟
|
数天到数周
|
|
可靠性、稳定性
|
节点级冗余
|
单点故障
|
|
安全性
|
多级用户角色权限模型
高强度加密
|
多级用户角色权限模型
高强度加密
|








