巡洋舰科技的机器学习项目也展开一段了,这几个月的一个突出感受是是, 人工智能的真正挑战是数据缺乏, 而我们面对的通常是小数据而非大数据问题。
人工智能如火如荼,很多公司想抓住机器学习人工智能的风口走一个,然而这些公司里,有很多人对数据的存留方式几乎可以用“落后”来形容……从几十万张纸片上的信息,到各路联络员脑子里的记忆,讲道理,客户说他有十万组数据,清洗完能有一千行可用的都谢天谢地了。
就比如说之前接的甲方预测农村土地报价的项目,甲方给我们做模型用的数据,大大小小清洗完,也就剩下了六百来个可用的……这可用的里面还有某些莫名其妙的原因导致应该肉眼去除的数据,比如北京某块十几亩的地一万块钱卖了这种,就算数据真实……对于我们想要构建的模型来说他也是杂音。
与大部分想象的大数据时代不同, IT时代走到现在这个阶段, 大部分公司面临的是小数据问题, 而非大数据。 就算是携程这样拥有巨量数据的公司, 深入到某个具体问题, 我们依然面临的是小数据问题, 比如云南的旅游线路推荐。 那些fancy的深度学习, 比如人脸识别和alphago中用到的卷积网络, 是注定无缘这些问题的。 那么这些领域是不是注定没法做呢?
数据小了, 我们怎么办? 其实小数据学习这件事,最会做的是我们人类自己, 我们的人脑, 最擅长根据小量数据举一反三 , 我们通过形成对客观世界的常识和概念来学习。 比如俗语说的一朝被蛇咬, 十年怕井绳这件事, 就是说当我们被蛇咬了一次(典型的小数据)然后我们就连看到井里的绳子,都会误以为那是蛇 。你掌握了规律, 看到苹果落地, 就懂得万有引力, 所以你能举一反三, 而目前的大数据却不能。
所以得目前一个征服小数据的有效手段,就是人为的录入规则,把这种“人类的方法” 加到机器学习里,从而大大减少需要学习的数据量。
好了, 铁哥的解决方法是什么? 出差和土地联络员面基!(田野调查),在亲吻大地的同时,了解土地价格里面到底了藏了多少秘密。 尼马,乱报价那是相当明显啊, 京郊普通土地虽然1000出头每亩每年比较正常, 然而多出几倍叫价的情形是会非常普遍,往高了叫2~5倍的价格,有些地方叫到十几倍都有可能……纯粹是看心情。这一观测使得我们团队果断选择了“范围内准确率”替代原有的相对误差。选择观测对象和角度, 有时是我们改善心情的唯一方法。
调查之后, 团队技术核心
@子楠
商议之后找出了一套更加适合小数据机器学习方法:
第一种要提到的是贝叶斯方法, 贝叶斯定律把已有的常识性信息通过先验概率嵌入到公式里, 而新的观测会修正先验得到后验概率,如果我们要通过为数不多的统计得到某城市的男女比例分布, 那我们把已知的全球男女比例102:100放入到先验里, 会大大加快少量数据下的结果稳定性。 先验概率里包含的常识信息, 可以大大减少我们需要的数据量
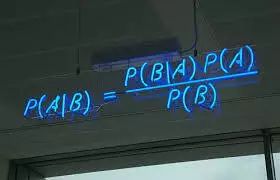
实践中我们更多采用符合实践的旁门左道而非直接用贝叶斯公式,但是思想里无疑不包含着贝叶斯种子。
首先我们合理假设去除脏数据,越是小数据, 个别的噪声对模型的影响可能就越明显, 我们首先把土壤转让价格转化成单价,然后根据我们在其他数据集上土地单价的相关知识, 把价格大于1600元每亩每年的都去掉。 我们发现, 在小数据问题上, 像Statistical tests, parametric models, bootstrapping这类的传统方法依然是大大有用的 。
再有我们决定削减冗余特征,做足特征工程,最早网络抓取的特征dummy化(如性别变成男,女,和中性三个特征,每个特征只取0,1)化后我们有200多特征 ,如水井, 农村土地补贴这些都纳入了因子特征, 我们大胆的把特征合并后得到10个左右核心特征, 如经济地理指数, 交通指数, 土地用途这一类, 准确率果然比200多特征还高
 数据量较小, 复杂模型是灾难而不是福祉, 不要过多特征, 更不要特征之间还有相互作用,神经网络表示跑出来的结果还不如线性回归
数据量较小, 复杂模型是灾难而不是福祉, 不要过多特征, 更不要特征之间还有相互作用,神经网络表示跑出来的结果还不如线性回归
不过我们还玩了一种更猛更激进的方法, 就是数据生成法,又称模拟大法, 就是我们在已有的原生数据里混入一些根据已有数据加上人为经验合成的人工数据,再放在一起来学习。 你说这不是造假吗? 其实不然,这里我们通过生成数据,在原数据中强化了我们对客观规律的认知。
比如这块地叫价50万,一般会往高了叫10万,那么,预测40~60万都认为是准确的,由于实际市场上人们偏向于报个高价(万一瞎猫碰上死耗子呢)而非叫低价, 于是我们考虑人类本性,选择 - 33% 到 + 50 %的价格范围来做价格评估。 这样准确率就轻松超越40% ,这反映了虽然存在大量瞎报价, 但是合理报价依然还是占有不少比例的。
然后在调查中我发现, 人报价的方法往往是一定按照单位面积的价格乘以面积(而土地上有房产则这种关系一定不成立,所以在数据统计中反而很难看出趋势), 而价格随着年份呈现一定的贴现率关系,当年数增大一倍, 价格并不翻倍,而是以一定指数折损,这背后的原理很简单, 我们对10年后的事情相对不关心, 所以10年后的价值要用现在的钱来买, 是要乘以一个折损率的。
我们把这些客观经验加进去,以此来增加模型中的有效信息,进而提高模型效果, 怎么样 ?
。反正提前拿出一部分数据藏起来作test集,然后再去对train集随便折腾。比如我的方法就是,copy一份train的数据出来,其他特征不变,面积全部增加或减少1.1倍,或年份增加或减少要1.1倍,用这些生成的数据混合原生数据,然后看看准确率是否得到了提高……
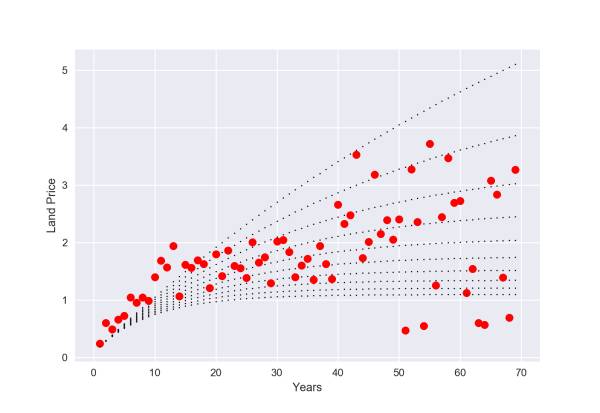 我们发掘的规律从数据拟合中得到了印证,价格和年份的关系果真符合一定的贴现率,而这个比率竟然是5% ,居然符合国家基本利率! 果然经济规律无处不在!
我们发掘的规律从数据拟合中得到了印证,价格和年份的关系果真符合一定的贴现率,而这个比率竟然是5% ,居然符合国家基本利率! 果然经济规律无处不在!
结果,果不其然(令人惊讶)的是,我们所采集的各个数据集上准确率都有提高,多的10%,低的2%,平均提高了5%左右。










