接着昨天的内容继续,今天依然会说目标检测的内容,希望关注的您可以轻松阅读,谢谢!
该文章主要是在detection当中引入了relation的信息,个人感觉算是个很不错的切入点,而且motivation是源自NLP的,某种方面也说明了知识宽度的重要性。但是一个比较可惜的点就是,relation module更像是拍脑袋思考了一个方法然后直接去实验验证了,对于relation到底学到了什么,能不能更好地理解这个信息,作者认为这还是个有待解决的问题。期待在relation问题上能看到更多有趣的思路吧。
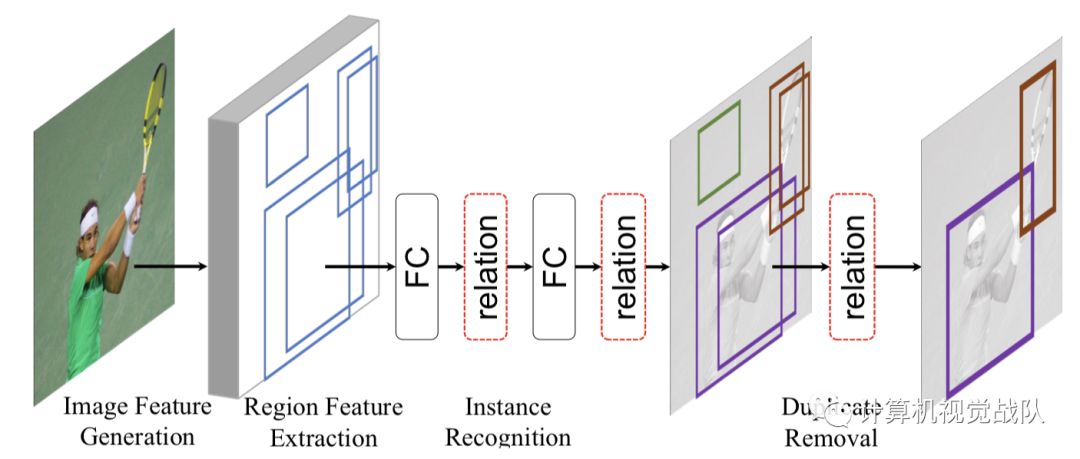
一、背景
在目标检测的时候,其实附近的环境,参照物其实也很重要。说到这个知识点,突然然我想到ICCV的一篇文章:

左图:
如果没有山,草坪参照,
在这个场景中检测羊其实很困难的。中间图:相反,右边图像上的上下文只会混淆船的检测。纯粹的物体特征是识别模型在这种情况下应该关注的问题。右图:这个汽车实例在其右侧被遮挡,识别模型应该集中在左边,这样才能准确检测到它。
总之,周边其他物体的信息很可能对某个物体的分类定位有着帮助作用,这个作用在目前的使用RoI的网络中是体现不出来的,因为在第二阶段往往就把感兴趣的区域取出来单独进行分类并定位。这篇文章作者就考虑改良这个情况,来引入关联性信息。
在文中,有一个直观的例子,蓝色代表检测到的物体,橙色框和数值代表对该次检测有帮助的关联信息。

接下来开始详细说说具体过程及实施:
假设,现在有一个object proposal用他的几何特征
f
G (
4-dimensional object bounding box)以及 外观特征
f
A
来表示。
对于给定的一组object
{
(
f
A
n
,
f
G
n
)
}
N
n
=1,
(比如RPN输出的300个object proposal),对于第n个object, 它收集得到的relation feature可以表示为:

其中m=1:N,相当于就是其他所有的object的特征,通过一个矩阵变化之后的加权平均。这个矩阵是学习得到的。下面具体讲不同object之间的权重是怎么得到的。
权重表达式如下:

其中,公式分母是个归一化的项,重点看分子,
ω
mn
主要是由两者决定的,
第m个object对第n个object产生影响的权重是由Appearance和Geometry共同决定的,
它们各自的求法如下:
外观(
Appearance
)权重表达式如下:

分别将下标为m和下标为n的object映射到低维空间(主要是降维),然后通过向量的内积来衡量两个object外观特征的相似性。分母表示降维之后的维度,
dot代表点乘,
dk是点乘后的维数。
几何(
Geometry
)权重表达式如下:

这个值得注意
,
用来将第m个object和第n个object之间的几何特征映射到高维空间,方法是首先计算m和n之间的相对位姿:

上述得到的相对位姿就是平移和尺度不变的了。然后将4维的相对位姿映射到64维的向量,和WG做内积之后,通过relu,relu的存在表明特征的融合只对具有特征几何结构的object之间进行。
上面的
f
R
(
n
)
表示第n个object收集到的一种relation feature,实际上,在作者的论文里,一个object会收集
N
r
种relation feature,然后将这
N
r
种feature concatenate在一起,和原本第n个object的feature相加,得到增强之后的特征。如下式:

对于目标检测,原来是用第n个object proposal的特征
f
A
n
输入classifier,现在是用融合了relation feature的特征输出classifier。为了保证concate之后的relation feature能够和原来的
f
A
n
维度一致,矩阵
W
V
对
f
A
m
起到了降维的作用。
这里是通过另一篇论文(Attention Is All You Need)中提到的方法将低维数据映射到了高维,映射后的维数为dg。
设dk=dg=64,总结如下:
在这个过程中,要留意通道数,比如16个relation模块输出concat可以和
f
A
n
叠加,那么它们每个的通道应该就是
f
A
n
的通道数
的16分之一。 这个模块直接应用在第二阶段,得到和原来相同的Output(score和bbox),应用是直接在fc层之后,即从原来的:

转变为:

如图所示:
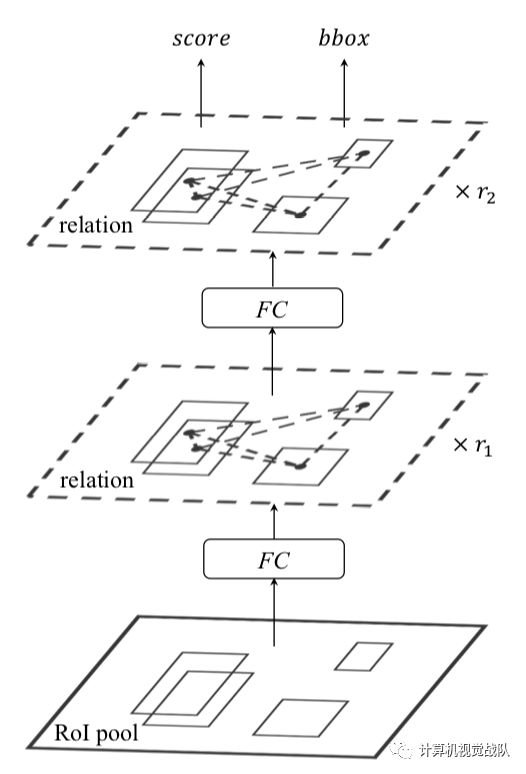
上面的具体过程如图:

Duplicate removal
作者的另一个贡献就是提出了这种可以代替NMS的消除重复框的方法。框架如下:

作者把duplicate removal归结成一个二分类问题,即对于每一个GT box,只有一个detected box是被分成correct,其他的都分成duplicate。Duplicate removal network是接在classifier的输出后面。该模块的输入包括object proposal的score vector(属于各个类别的概率), bbox,以及proposal的特征。
对于某一个object proposal的某一个类别,假设属于这个类别的概率为
score
n,
首先经过一个rank embed模块,即拿出其他object proposal属于该类别的score,进行排序,得到第n个object proposal在排序中的下标(rank),作者特别说明了,使用rank值而不是直接score的值非常重要。然后将rank值映射到128维向量,同时将该proposal的特征也映射到128维,将两种128维的特征相加之后作为新的appearance feature,然后和bbox作为relation module的输入,得到新的128维的输出,和W_s做内积之后通过sigmoid得到s_1,最终的correct的概率s=s_0 * s_1。整体流程如上图所示
作者认为这样做的好处如下:
-
output的时候,NMS需要一个预设置的参数;而duplicate removal模块是自适应学习参数的;
-
通过设置不同的η,可以将模块变成多个二分类问题,并取其中最高的值作为输出,作者经过试验,证明这种方式较单一阈值的方式更可靠;
-
作者发现阈值的设置和最后的指标有某种联系。例如mAP0.5在η=0.5
时的效果最好,mAP0.75的t同理,而mAP使用多个
η效果最好;
-
最后,就是η的含义问题。之前也发过邮件和作者沟通,对方的回复是,η本质上代表的是分类和定位问题的权重,它的值设置得越高,说明网络越看重定位的准确性。
作者也提出了问题:










