编者按:上个月,机器学习领域顶级会议ICML在美丽的瑞典城市斯德哥尔摩召开,微软亚洲研究院机器学习组实习生赵志冰参与了这次盛会,今天他从一位青年科研工作者的视角,为大家分享ICML 2018上的亮点与参会感悟。
另外,想入门AI的同学,不要错过文末GitChat线上交流活动的预告哦!
7月的瑞典斯德哥尔摩比北京凉爽许多,10日-15日,机器学习领域顶级会议ICML在这座美丽精致的小城召开,AAMAS 2018和IJCAI 2018也先后在同一会场举行。

本届ICML的注册人数达到了5000余人,是ICML 2017的两倍以上。大会共收到投稿2473篇,比去年增长了45%,其中621篇被接收。
来自神经网络结构和强化学习两个子领域的投稿数量最多,强化学习领域的接受率更高
,其它热门方向还有深度学习、在线学习、统计学习、隐私安全等等。

ICML 2018概况

ICML 2018论文子领域统计
对于有志于向ICML投稿的读者,我建议大家
关注大会的反驳环节(rebuttal)
。本次ICML的反驳环节促成了45%的审稿意见变更,最有利于提升审稿分数的关键词包括“深度”、“包括”、“澄清”、“建议”、“更新”、“有建设性的”、“有用的”、“有价值的”、“感谢”等等。如果把这些词连起来会变成如下的一句话:感谢您有用的建设性建议以及无价的有深度的问题。如果我们有测试我们估计结果的空间,我们会澄清我们的观测,并且更新最终的附录。这当然只是一个玩笑,但从中可以看出,
我们在向审稿人提出反驳意见的时候一定要保持礼貌和理性
。

本次会议评选出了两篇最佳论文(Best Paper Awards),它们分别是
-
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
这篇文章发现obfuscated gradients并不能完全抵御对抗样本的攻击。对抗样本的问题近年来得到越来越多的关注,我比较看好这个方向。还没确定自己研究课题的读者可以考虑加入这个方向。
论文链接:
https://arxiv.org/pdf/1802.00420.pdf
-
Delayed Impact of Fair Machine Learning
这篇文章分析了不同的公平标准对人的延迟影响。研究发现常见的公平标准一般不能对人群产生正面影响,甚至有时候会产生负面的影响。
论文链接:
https://arxiv.org/pdf/1803.04383.pdf
会议也评选出了一篇时间检验奖(Test of Time Award),获奖论文为发表于ICML 2008的“A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning”,目前已经被引用约2500次。如果你的研究方向目前比较冷门,请保持耐心,十年之后这个奖项可能就属于你:)。
论文链接:
https://ronan.collobert.com/pub/matos/2008_nlp_icml.pdf
下面介绍一下本次会议上发表的我比较感兴趣的一个教程。这个教程是关于
深度学习的理论理解(Toward Theoretical Understanding of Deep Learning)
,来自普林斯顿大学的Sanjeev Arora教授。虽然主题是理论,但教程更多的是对理论发展的科普,重点放在对深度学习的直观理解上,所以对一些不喜欢读理论的读者也比较友好。
教程首先介绍了深度学习的发展简史和一些基本知识,并且指出研究深度学习理论的目的是让我们对深度学习有更直观的理解,从而产生新的发现。
然后教程对深度学习领域的一些实际问题进行了讨论。比如,目前大部分深度神经网络的优化问题都是非凸的,有些问题甚至NP-hard,维度的诅咒(curse of dimensionality)会让问题尤其复杂。传统的机器学习认为模型越简单,参数越少,泛化(generalization)就会越好,否则会发生过拟合(overfitting)。但是,深度学习的实验发现,随着模型复杂度的增加,明显的过拟合并没有发生。而且,一些近期的研究发现,过参数化(overparameterization)反而会让优化变得容易,这种现象目前还没有得到理论上的解释。
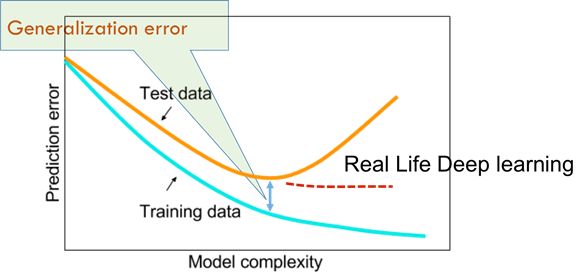
一个更加实际的问题是我们该如何选取网络的深度。直观上来说,越深的神经网络,表达力越强,但训练越困难。而最近的一个研究发现,增加神经网络的深度能够加快优化(注:笔者对这个结论持保留意见,因为文章里的实验结果只能表明,增加深度可以用更少的循环达到相同的效果,而没有比较每一个循环运行的时间。所以此处的“加快”应该更准确的理解为“用更少的循环次数”)。
该教程还讨论了生成对抗网络和文本编码等深度学习领域的热门话题。有兴趣的读者可以阅读教程原文:
http://unsupervised.cs.princeton.edu/deeplearningtutorial.html

接下来介绍一下我在ICML 2018发表的文章 “
随机效用模型的边缘似然估计
”。
随机效用模型是一个经典的离散选项模型。给定一个选项集,随机效用模型会认为每一个选项都对应着一个效用分布。一个选项对于不同人的效用独立服从于这个效用分布。每个人对于不同选项的偏好取决于他从每个效用分布中抽取的效用。
在一些场景下,为了实现更好的集体决策,我们需要根据人们对于一个选项集中不同选项的偏好来估计每一个选项的效用分布。例如下图的场景:Judy、Nick和Ben想要选一个吃饭的地方,他们对备选选项有不同的偏好,比如Judy最喜欢veggie grill,其次是dunkin’s donuts, 最后是哈根达斯。我们可以根据这三个人的偏好来估计出一个随机效用模型,然后根据估计的参数(即每个选项的效用分布)来帮他们选择一个餐馆。
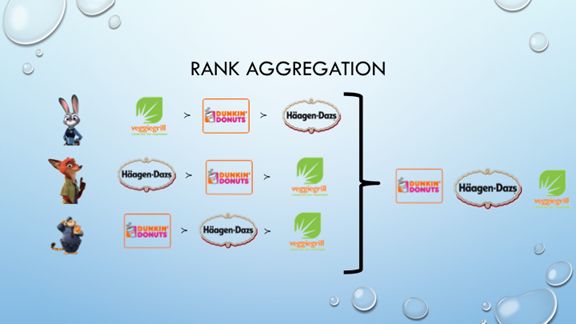
然而,随机效用模型在一般情况下(比如所有效用分布都是高斯分布)的参数估计比较困难,因为这种模型定义的排序的概率没有已知的解析表达式。因此,我们舍弃了传统的极大似然估计方法,用极大边缘似然估计方法取而代之。
我们以每一对选项的比较结果作为边缘事件,通过极大化边缘概率的方法达到参数估计的目的。我们还可以在不同对选项的比较上加上不同的权重,以达到更好的区分某一对或者某几对选项的目的。
最后,实验证明这种方法的好处有如下几点:
-
灵活。边缘事件和每对选项的权重都有无限的选取方式,这为我们服务不同的目的提供了可能性。
-
快。我们提供的算法只需要读取一次数据。我们证明了目标函数是严格的凸函数,极大的增大了优化的效率。这一点也得到了实验的证明。
-
准确。实验显示,我们的方法对高斯随机效用模型的估计比之前的广义矩估计更准确(均方差更小)。
想要了解更多详情,可以阅读论文或者通过个人主页联系我。
论文链接:
http://proceedings.mlr.press/v80/zhao18d/zhao18d.pdf
个人主页:
http://homepages.rpi.edu/~zhaoz6/
此外,在本次ICML上,微软亚洲研究院机器学习组也发表了两篇文章,感兴趣的读者可以点击以下链接了解详情:
纵观本次会议,大部分工作免不了是在已有的框架之下做一些改进和提升,而这种提升常常十分有限。如何跳出已有框架做出开创性工作,是我们每个青年科研工作者应该思考的问题。这种工作虽然难,但也并非无章可循,比如对抗生成网络(GAN)有效地结合了博弈论和神经网络。神级科学家可以闭门造车,一般的科研工作者至少可以做到广泛涉猎,并且融会贯通。机会总是光顾有准备的人,脚踏实地地学习创新,说不定我们的工作就会成为下一个焦点。
作者
简介

赵志冰,伦斯勒理工大学计算机系在读博士生,目前为微软亚洲研究院实习生。曾在ICML、AAAI、UAI发表多篇文章,感兴趣的方向包括排序学习和机器翻译。
你也许还想看
:










