裴雷,南京大学信息管理学院副教授,研究方向:信息政策分析与信息资源管理;
孙建军,南京大学信息管理学院教授,研究方向:大数据分析与人文社会科学、网络信息计量与网络信息资源管理;
周兆韬,南京大学信息管理学院研究生,研究方向:政策语料库分析(CAPS)。
政策文本是指因政策活动而产生的记录文献,既包括政府或国家或地区的各级权力或行政机关以文件形式颁布的法律、法规、部门规章等官方文献,也包括政策制定者或政治领导人在政策制定过程中形成的研究、咨询、听证或决议等公文档案,甚至包括政策活动过程中因辩论、演说、报道、评论等形成的政策舆情文本,历来是政策研究的重要工具和载体
[1]。如在政策研究方法论中,Trauth[2]认为主要有“预测-描述”的诠释范式、“价值批判-价值构建”的价值范式、政策过程范式以及政策评估和绩效范式等主要形式,其中诠释范式又分政策文本分析、政策分类或框架体系、政策生命周期律、政策社会系统等理论。可见,政策文本研究在政策分析研究领域占有重要地位。
随着计算机方法的引入应用,政策文本分析所能处理的素材量和处理精度得到了大幅提升,并引入了新的方法和理念。尤其是政策文本数据,如文本型数据(Textual Data)、数据文本(Text as Data)、文本数据空间(Text Universe)等相关概念的提出,研究者在政策文本内容分析法的基础上相继提出了政策文本语料库分析和政策文本数据挖掘方法,并利用上述方法解读和获知政策立场、政策倾向、政策价值、政策情感等深层政策内涵以及广义的政策比较分析。我国李江等[3]提出运用政策计量(Policiometrics)的研究思路来揭示政策引用、主题共现以及机构共现等政策关系。本文通过梳理国内外政策文本内容分析、政策语料库以及政策文本挖掘的相关理论研究进展,探讨了政策文本计算分析的可行框架与应用前景。
政策文本计算是21世纪初Michchael Laver、Kenneth Benoit和Will Lowe等提出的,运用计算机科学、语言学和政治学的理论建立的海量政策文本挖掘和计算分析框架。政策文本计算主张运用政策编码、政策概念词表或政策与语词之间的映射关系进行政策概念的自动识别和自动处理,最终构建从政策文本到政策语义的自动解析框架,并在此基础上关注政策文本及其内涵分析。具体到方法论层次,政策文本计算被认为是一种非介入式、非精确性的解析方式,并广泛应用于元政策分析领域。
2.1 政策文本计算是非介入式研究方法
从分析主体看,政策文本计算源自政策话语分析,是作为政策分析的一种非介入式方法引入政策科学领域。在政策分析传统中,一般强调以政策利益相关者的心理或行为假设为出发点,以公共政策绩效或调整结果为评价,并对政策过程、政策工具的可行性进行相关评估研究。因此,不论是运用控制论、运筹学、系统分析或博弈论等过程分析方法,还是运用行为科学、社会心理学、组织理论、权威理论、群体理论等行为解释理论,或是预设一定的分析框架予以验证,都不可避免地要预设政策立场以及政策价值取向,作为政策分析的判断标准。而政策文本分析或政策话语分析(Discourse Analysis)认为政策文本已经蕴含了政策交流系统中的语义与价值情感[4],研究者无需再设计相应的政策框架,仅需要转述或提取政策文本中蕴含的语义,并有序表达。
非介入式方法的优点是研究结果的中立与客观性,弱化了研究者因政策立场偏见、被调查者(样本)主观偏性而带来的效度瑕疵[5],并且便于将研究结果复现和应用于大范围尺度和长时间尺度,在宏观政策研究、比较政策研究和非预见性研究中具有广阔应用前景[6];但不足是文本处理过程效度不够,无法兼顾政策语境的差异性,研究结果的可解释性较弱。
2.2 政策文本计算是非精确性研究方法
从分析方法看,政策文本计算的出发点是政策文本的自然语言处理,即政策的语法解析。虽然众多政策文本计算研究者试图构建语法文本与语义文本、语用文本的映射关系,或依据研究者的理解构建分析词表或抽取若干政策元素或属性,然后以“聚焦”方法跟踪研究。但早期通过这种“重构”或“再塑造”方式建构的政策文本内容分析方法,不仅耗时长、成本高,而且在方法论上形成了研究者事实上的“意识介入”,研究者本身作为研究工具存在于研究过程,其可靠性依然为学界所诟病。
随着政策文本数量的激增和开放获取的便捷性,基于海量政策文本的语义自动提取方法日益成熟,在显性政策要点、政策情感以及政策立场领域的识别精度越来越高。如Hjorth等[7]对自动文本分析与专家调查分析的对照分析发现,两种自动分析方法和专家分析对CMP RILE measure政治演讲语料库的对比分析中,自动分析政策主题排序与专家主题分析排序的spearman相关系数(Spearman’s ρ)显著优于专家与一般选民识别的spearman相关系数。不过,从政策计算的分析结果看,政策文本分析结果仍然是非精确性的。如Proksch和Slapin[8]认为,现有的政策文本处理的算法缺陷、政策文本的语言特征以及政策文本结构和语境适用性缺失都是政策文本计算分析的致命不足;虽然Mikhaylov和Benoit等[9-10]在研究政见语料库时均发现,专家研究的手工编码误差并不比计算机自动编码误差小,因而政策文本计算的分析误差来自编码本身,而非计算机算法或处理误差。而在主流政策分析领域,政策研究者虽认可政策计量在问题识别和政策分析中的价值[11],但认为政策计算分析的结果仍是非精确性的、参考性的[12]。Grimmer和Stewart[13]甚至提出政策自动文本分析的“4原则”:第一,所有的自动文本分析结论都是“错误”的,但可用;第二,自动文本分析永远无法替代政策分析者本身;第三,永远没有最好的文本分析解决方案;第四,连说三遍“研究效度”。因此,研究者普遍认为,加强政策的解释性分析,并融合质性方法的混合方法更具有应用前景[14]。
2.3 政策文本计算聚焦于元政策分析
在政策分析中,元政策一般是“政策的政策”,是从现有政策中抽象出的理念或方法,其关注的是整个政策系统及其改进,涉及公共政策的指导思想、价值标准、行为准则、程序步骤、方式方法等[15]。而从分析对象看,政策文本计算处理对象多为政策语词、政策概念(主题)、政策义素等显性政策功能词,或政策立场、意识形态、政策倾向、政策情感、政策价值、政策态度等元政策领域。
究其原因:首先,元政策分析的非精确编码属性与政策计算分析的非精确性具有很好的契合度,具备了元政策计算分析的方法论基础;其次,元政策抽离了政策工具、政策区域以及政策地域的语境影响,一是形成了最大可能的频次聚焦,二是具备了跨区域政策比较的可能性;最后,元政策具有非显在性,无法通过简单观察获知,而借助计量或计算方法的元政策识别机制能为研究者所接受。
政策文本计算既是一种政策分析研究理念和研究框架,也是完整的政策分析流程。从分析方法角度看,Wiedemann将政策文本计算,或称为计算机辅助文本分析(Computer Assisted Text Analysis,CATA)分为文本内容分析、文本数据处理和文本挖掘三个研究层次,并先后经历了计算化内容分析(Computational Content Analysis,CCA)、计算机辅助定量数据分析(Computer-Assisted Qualitative Data Analysis,CAQDA)以及语料计算学(Lexicometrics for Corpus Exploration)等不同发展阶段[16];从分析流程角度看,Grimmer和Steward[13]将政策计算分为政策文本获取(Acquire Documents)、政策文本处理(Process)和政策文本分析三个典型阶段(见表1)。两者均认为政策文本处理和文本挖掘方法是政策文本计算分析的核心,本文则从政策文本内容分析、政策文本计量分析、政策文本数据处理和政策文本挖掘四个方面考察政策文本计算的典型方法。
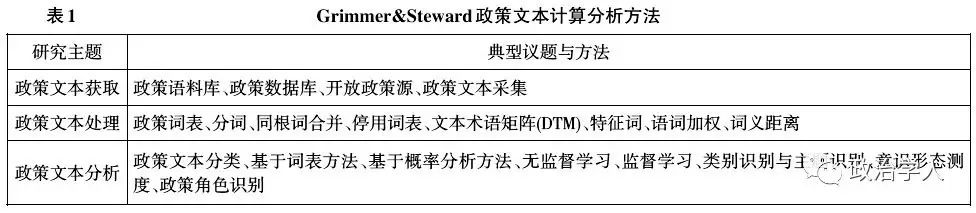
3.1 政策文本内容分析方法
政策文本内容分析是一种介于定性与定量之间的半定量研究方法,与之类似的还有一致性分析(Concordance Analysis)、话语分析(Conversational Analysis)、话语文本分析(Discourse Analysis)、计算诠释学(Computational Hermeneutics)、定量文本分析(Qualitative Text Analysis)等研究方法。从20世纪80年代开始业内就陆续研制了相关的文本分析软件用于文本标记、文本编码和相应的编码管理工具,如Atlas.ti、MAXQDA、QDAMiner、NVivo、SPSS Text Analytics for Surveys、QCAmap、CATMA、Libre QDA、MONK Project等文本数据管理软件工具。虽然引入了计算机软件对政策文本进行概念抽取和定量化统计,并具有文本数据的自动统计和关系识别方法,但其概念抽取方法仍采用传统的文本分析方法和流程,在数据处理环节仍主要依赖研究者的人工提取,体现为一种半计算化分析工具。
因此,这类计算处理方法能够处理的政策文本数据有限,一般处理政策样本集(Sample,n≤200),最多通过协作方式处理政策主题集(Subsets,N≈1000)范畴的政策文本集,而对政策语料库(Corpus,N≥10000)基本上无法处理。因而,这类研究方法的研究议题也主要沿袭了政治学和诠释学中的政治话语研究和政治文本内容分析框架中的符号论和政治语词解读(政策主题识别与比较)的研究传统。
3.2 政策文本计量分析方法
政策文本计量分析主要是采用文本计量分析的基本理论与方法,通过对已有政策文本数据库或政策文本语料库在政策主题分布、政策发布时间序列分布、政策引证以及政策主体关系等要素进行计量分析[3]。在Grimmer的政策计算分析框架中,政策文本主要来自政策数据库和已有语料库、网络政策文本和非电子化政策文本。因此,政策文本计量分析的主要方法和工具也主要有三种类型:一是政策文本数据库自有的文本计量分析方法与工具,如LexisNexis、ProQuest、Westlaw、Hein Online、北大法宝和CNKI政府公报数据库等政策或法律文本数据库,利用数据库自带的字段设定结合政策主题、类型、时间、地域等进行政策统计或计量分析,或应用共词或共现分析,能有效分析政策文献增长、扩散、流变等变化规律;二是利用网络分析和替代计量学(Altermetrics)方法和工具进行网络政策文本分析[17],如Wiley,NPG和PLOSOne等开始提供Altmetric服务,Altmetric也可以对国内新浪微博进行追踪,因而对社会媒体中的政策文本以及跟踪研究也成为可能,如匹兹堡大学创建的MPQA政策辩论语料和卡内基梅隆大学Sailing实验室Jacob Eisenstein 和Eric Xing创建的政治博客文本集语料;三是通过政策文本采集与语料库构建并提出新的统计口径和研究方法,如苏竣和黄萃等对中国科技政策的类型统计分析[18]以及卡内基梅隆大学Wilson等对网站隐私政策的主题解析分析[19]。
3.3 政策文本数据处理方法
从政策文本的范围看,政策文本结构性差异很大:既有政府的政策文本、法律档案(听证会材料、判例),也有政策新闻、媒体数据和政策研究文献;既有总统竞选纲领、演说文本集,也有社交媒体的公众政治言论和政治评论。而通过自然语言处理将政策文本解析为结构化文本数据(Textual Data),并构建语词、语义或情感等特殊对象,不仅能形成对大规模政策文本语料的系统化处理,而且能在不同的政策文本集中进行比较分析和一致性分析,推动政策文本融合分析。结合政策文本分析的应用,典型的研究方法和工具有政策文本自然语言处理和语法计量分析、政策文本处理以及政策语义分析(见表2)。
在政策文本数据处理过程中,政策文本或语料集适用于通用的自然语言处理方法和文本数据处理方法,政策语词分析和政策语义分析在政策主题统计(聚类)、政策热点识别、政策意见分析中应用较多[20-21]。目前,在政策文本处理领域最受关注的议题:一是语料库尺度的政策内容分析[22-24],主要是对政策语料库的统计和计量分析,识别政策语境中的热点议题[25],关注政策议题的扩散或影响[26-27],尤其是政治演说语料库、政见语料库、政治纲领语料库分析;二是政党和选举研究中的政策立场分析和政策倾向研究,政策文本计算的概念本身即为比较政见研究(CMP)的Michchael Laver提出,而基于先验词权(Reference Score)的WordScore和无先验词权的WordFish也是政策文本计算分析中应用最广泛的分析软件,CMP以及后续研究项目(MARPOR)提供的政见语料库也是采纳率最广的语料库。
3.4 政策文本数据挖掘方法
文本挖掘,又称为文本数据挖掘或文本知识发现,是指在大规模文本集合中发现隐含的、以前未知的、潜在有用的模式的过程[28],涉及数据挖掘、机器学习、统计学、自然语言处理、可视化技术、数据库技术等多个学科领域的知识和技术[29]。与政策文本处理更注重政策语词或语义分析相比,政策文本数据挖掘更注重在大量文本数据集合中发现分类/聚类特征、发现关联知识或规则,并注重深层潜在语义的知识发现。因此,政策情感分析、政策意见分析、政府行为预测等典型方法得到政策研究领域的广泛关注,如Saremento等对用户评论的政策倾向分析[30]、Hopkins和King[31]对博客政策意见的分析。政策情感分析在西方国家选情预测中尤为关注,包括政治领导人的政策情感倾向[32]、选民的情感反馈与倾向[33-34]以及整体选情预测[35-37];在政策意见分析中,公众意见收集和政治意见追踪也是常见的研究主题,并将公众政策意见与其政治立场和政党支持度关联,建立了计算化的政党舆情监测、政党竞争或政党派系识别以及政策结果评估的分析方法[38-39];政府行为预测体现了政策预测分析的方法和思路,通过对政府领导人、政党的竞选纲领或关键政策文本的分析,挖掘潜在的政策热点或发展轨迹。国内研究者也利用数据挖掘方法对政策热点[40]以及政策价值[41]进行了分析,或系统利用文本挖掘方法对政策文本的内部结构关系进行了主题识别或关联分析[42-44],但总体上缺乏系统性和连续性。
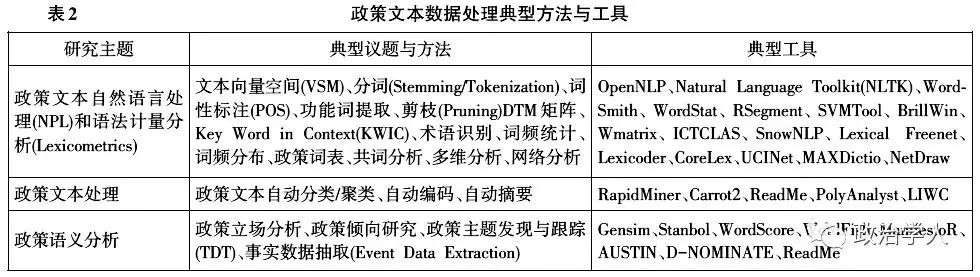
4.1 政策文本语料库建设
政策语料库以及语料库语言分析是政策文本计算分析的基础。早期的政策语料库一般针对政府出版物或公开政治文本进行采集加工,如政策条文、相关政策解释、政治人物传记、语录或新闻纪录等;现在则扩展到更加多样化的语料来源。除了LexisNexis、北大法宝等传统的法律信息服务提供商,目前比较典型的政策语料库有:
(1)德国柏林社会科学研究中心比较政见研究项目政见文本语料库(MRG/CMP/MARPOR)[45]。Manifesto语料库是目前政策分析领域加工最为成熟的开放政策语料,包括1945~2015年70年跨度,涉及所有欧洲国家和少数英美联邦国家(美国、加拿大、澳大利亚、南非、新西兰)总计超过50个国家的4051个政见语料集,涵盖了1979~1989年政见研究组MRG(Manifesto Research Group)、1989~2009年比较政见研究CMP(Comparative Manifestos Project)以及当前基于政治表达的政见研究MARPOR(Manifesto Research on Political Representation)持续研究的政策语料。在语料分析工具包中,既包括手工编码的政策术语编码手册(Code Book),也包括794536个跨语种的机器识别政策术语、短语或词条;既包括软件版本的WordScore分析工具,也包括R语言的分析包Manifesto R。因此,Manifesto语料库和Word-Score分析软件是目前政见分析和政策文本计算领域引用率最广的语料库,尤其在政策立场和政策倾向研究中。
(2)美国康奈尔大学政策文本语料库(Corpus of political discourse)[46],它是康奈尔大学计算机系庞大的语料集中的一个子集,主要是由Matt Thomas,Bo Pang和Lillian Lee整理的总统国会演讲数据集(Congressional speech data),同时因Lillian Lee设计开发了相应的情感开发工具ReadMe,因此在严肃政策文本的政策情感研究领域受关注度较高,目前共有22篇研究文献利用或援引了该数据集。
(3)美国匹兹堡大学计算机系的MPQA Opinion Corpus语料库(Multi-Perspective Question Answer,MPQA)[47],主要是新闻报纸素材的语料,包含4个子库、4个词表和基于语料库分析技术开发的Opinion-Finder系统(目前提供2.0版本下载),其中有一个专门子库为政策辩论数据库(Political Debate Data)。同时,因其情感标注系统比较出色,因而也是博客、评论等开源语料政策情感分析的主要素材和工具。
(4)卡内基梅隆大学计算机系Sailing实验室的政治博客语料库[48]。由Jacob Eisenstein和Eric Xing整理开发,主要采集了2008年6个博客平台的13246个政治博客文本记录,并且通过意识形态的分层抽样,也是政治博客研究比较重要的语料资源。类似的语料集还有美国海军学院Twitter政策语料集。
(5)香港浸会大学整理开发的政治演讲语料集(Corpus of Political Speeches-HKBU Library)[49]。目前主要包括4个部分:美国历届总统演说语料文本集和多媒体文本(1789~2015)(约443万字)、历届香港总督或特首施政报告语料集(1984~1996,1997~2015,约43万字)、历届中国台湾地区领导人新年致辞和双十演讲语料集以及中国历届政府总理施政报告语料集,是比较完整的中文政策语料集之一。
此外,德国柏林Brandenburg科学研究院的阿德莱登·巴拉巴西提供的德国政策语料集[50]则结合了政策语料分析与可视化研究,利用这个政策语料集可进行总统演讲频率、演讲主题和演讲所涉及的政策语言的可视化分析,网站提供粗语料、分词后的语料以及标引后的语料等不同版本的语料。
4.2 政策文本分析工具研制
因语境意义对政策文本分析的现实意义更大,当前政策文本计算比较注重政策词典和政策文本分析专用工具的研制。目前,主要有两类研究方法:










