编者按:
现在公众号有置顶功能了,大家把微信更新到最新版本,点开“大数据实验室”公众号。点“置顶公众号”键,就可以置顶了,这样。不管我们什么时候更新,您都能容易找到。
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
选自arXiv
近日,卡耐基梅隆大学(CMU)和 Petuum 推出了新一代高效的分布式深度学习通信架构 Poseidon。Poseidon 是一个易于使用,并能放大 DL 程序在 GPU 集群性能的通信架构。已存的 DL 程序不需要更改代码就能通过 Poseidon 在多个机器上自动最优地实现并行化,加速效果和机器数量呈线性增长关系。机器之心简要地介绍了该论文,详细内容请查看原论文。
论文:Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
论文链接:https://arxiv.org/abs/1706.03292

深度学习模型在单 GPU 机器上可能需要花费数周的时间进行训练,因此将深度学习分布到 GPU 集群进行训练就显得十分重要了。然而相对于 CPU,拥有更大的吞吐量的 GPU 允许单位时间内处理更多的数据批量(batches),因此目前的分布式 DL 因为大量参数频繁地在网络中进行同步而表现不佳。
我们提出了 Poseidon,它是一个分布式 DL 在 GPU 上可实现高效通信的架构。Poseidon 利用深度程序中的层级模型结构而叠加通信与计算,这样以减少突发性网络通信。此外,Poseidon 使用混合的通信方案,并根据层级属性和机器数量优化每一层同步所要求的字节数。我们表明 Poseidon 能使 Caffe 和 TensorFlow 在 16 个单 GPU 机器上实现 15.5 倍的加速,而且该实验还是在有带宽限制(10GbE)并挑战 VGG19-22K 图像分类网络下完成的。此外,Poseidon 能使 TensorFlow 在 32 个单 GPU 机器上运行 Inception-V3 达到 31.5 倍的加速,相比于开源的 TensorFlow 实现 50% 的性能提升(20 倍加速)。
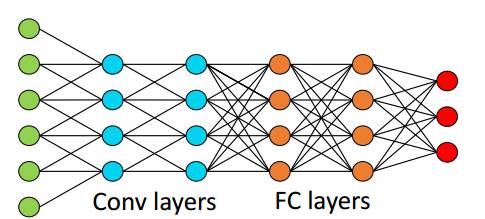
图1. 六层卷积神经网络
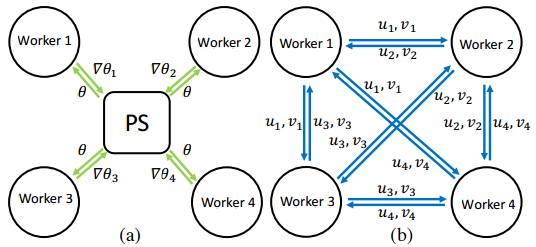
图 2:(a)参数服务器和(b)分布式 ML 的充分因子 broadcasting。
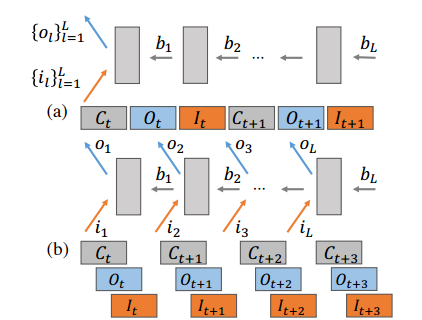
图 3:分布式环境中的(a)传统反向传播和(b)无等待(wait-free)反向传播。
Python量化投资实战营(深圳-香港)
2017年7月17日-21日(第一期)深圳-香港
2017年8月21日-25日(第二期)深圳-香港
量化交易深入解析
用Python做量化交易
Mongodb数据库与数据处理
Python量化引擎基础,执行一个策略
环球FOF投资
股票数据统计与Alpha因子策略
量化策略-CTA策略……

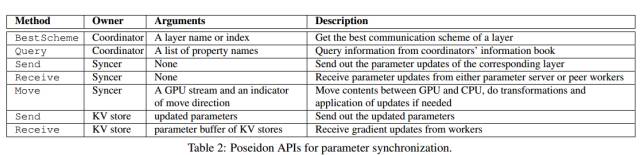
表 2:用于参数同步的 Poseidon API。

图 4:Poseidon 架构的概览。
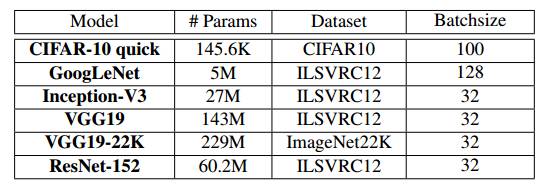
表 3:神经网络的评估。其中展示了单结点批量大小,这些批量大小是基于文献中的标准报告而选择的(通常最大的批量大小正好是 GPU 的内存大小)。
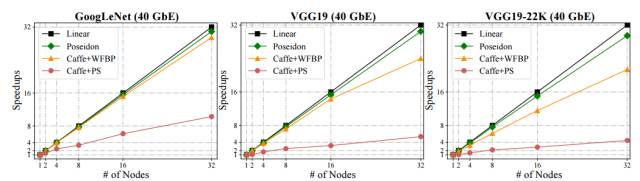
图 5:使用 Poseidon 平行化的 Caffe 和 40GbE 带宽训练的 GoogLeNet、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 Caffe 设置为基线(即加速=1)。
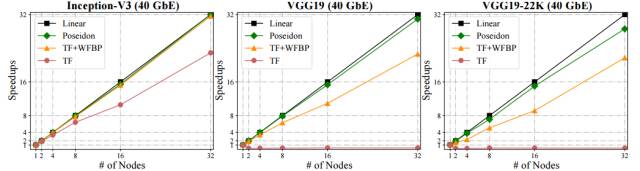
图 6:使用 Poseidon 平行化的 Caffe 和 40GbE 带宽训练的 Inception-V3、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 TensorFlow 设置为基线(即加速=1)。
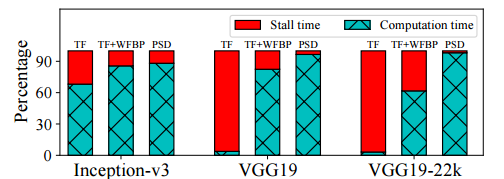
图 7:在 8 个节点上使用不同系统训练三种网络的 GPU 计算分解和延迟时间。
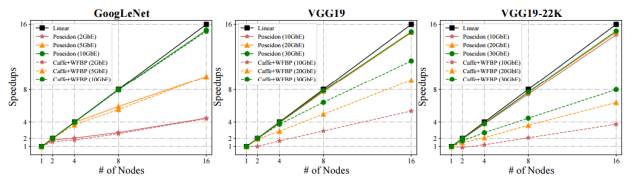
图 8:使用 Poseidon 平行化的 Caffe 和不同网络带宽训练的 GoogLeNet、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 Caffe 设置为基线(即加速=1)。
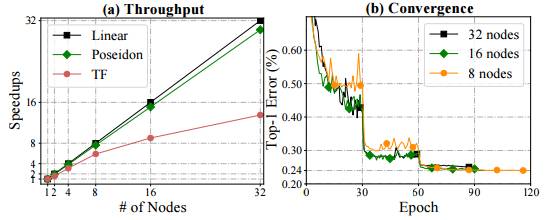
图 9:(a)加速 vs. 节点数量和(b)使用 Poseidon TensorFlow 与原始 TensorFlow 训练 ResNet-152 的最佳测试误差 vs. epochs。

厉害了!年化收益上百倍的爆发型交易员居然来自这里!
微波段稳定盈利的原理和必要因素
交易系统的组成和木桶效应
势与格局的判断
形态和k线组合……
2017年7月16日—8月11日 郑州
报名电话/微信:13061694649










